Customer Data Analytics
Although data is the basis of value for many modern companies, there are technical limitations today to extracting valuable insights out of the data being collected. Customer data analytics is the practice of generating helpful inferences from data that’s either coming directly from your customers, or is inferred through their actions in your SaaS product, website, and campaigns.
Such a summary might sound familiar, or even clichéd. Even before the first customer satisfaction form was filled out, medieval peddlers were reacting to in-person feedback on the quality and consistency of their spices. But to remain competitive in the modern marketplace, unlocking insights from customer data analytics is critical, and often requires implementing and using modern data technology and systems.
This article will identify the parameters and important questions that go into the practice of customer data analytics (also known as customer data analysis or consumer data analytics). It will give you the breadth of understanding to handle specific questions you want your data to answer, as well as an intuition for developing a stronger underlying technical and organizational system for your customer data.
The first step: different types of analysis
Just as with any data-driven inquiry — from school science fair to dissertation — customer data analysis needs to begin with a hypothesis. The general directions of investigation in business are often clear (i.e., which campaigns produce the highest-value customers), but it's worth categorizing some large-scale themes, as they have consequences for later data system design.
To put it another way, before we build the data systems and actual customer data analytics themselves, we need to know what we are building for.
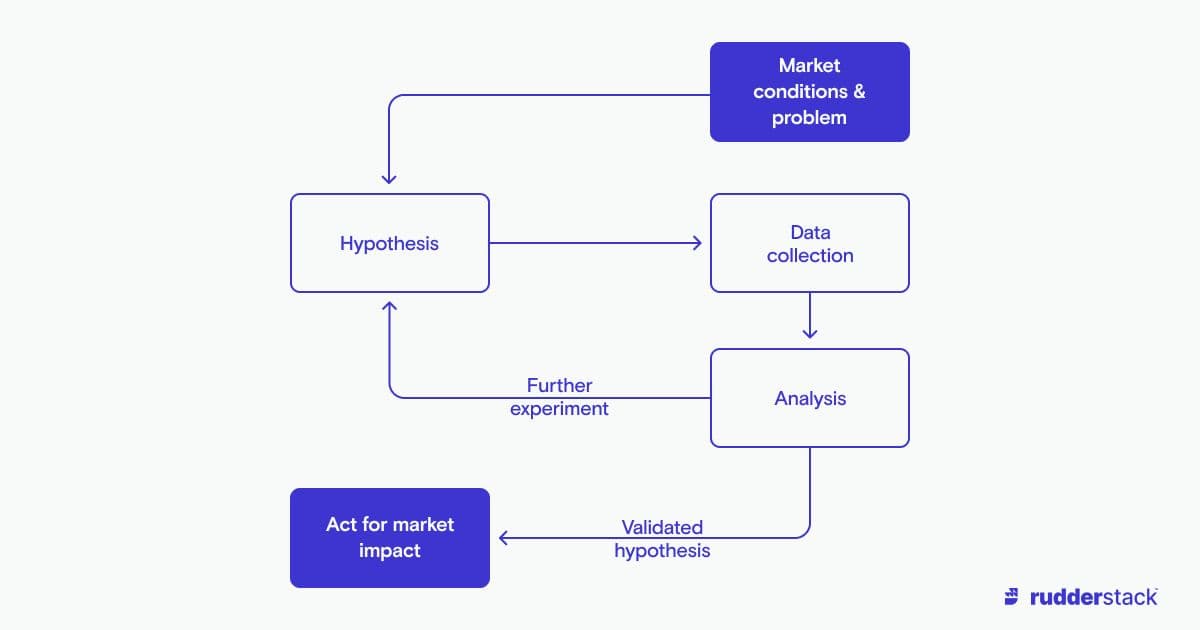
Using data to meet new market conditions with a testing cycle
Defining the scope of your question
Let’s look at two questions that seem simple on the surface and are related, but have significant differences in terms of building analytics.
- Where are customers coming from?
- How are people using the product/service?
These questions are related. For example, investigating customer satisfaction with a new feature could fall into either category. However, the use of this knowledge is quite different. A marketer might seek to identify a range of features that customers seek in the market in order to build campaigns, while a product analyst could run deviation analysis on satisfaction results according to version history to track the feature adoption.
Understanding which direction your analysis will take can help define the tools and data sources that are required to build that analysis
Responsiveness — how frequently does this analysis need to be updated?
From quarterly reports to live dashboards, there is an entire range of time-based resolution that can be used with any given analysis. This is an important aspect of your investigation to understand in advance, as both high-resolution and high-frequency analysis are associated with higher compute, database, and storage costs. The last thing you want to do is clog up a badly configured production database with complex queries.
Longevity — how should this data be stored?
This is another decision that can determine the correct tool for the job. As we will see later, most modern data systems collect data in a central data warehouse and base analyses on that foundation. However, not all data needs to be kept up to date. Consider a large neural net: these can run to hundreds of gigabytes in size, and in some processes they are regenerated daily. There is no need to retain all the older models, just a few historical benchmarks. On the other hand, identity resolution of customer data should be preserved indefinitely, as it reduces duplication and the hassle of analysis (and customer data retains value even despite churn).
Storage requirements and data retention are yet more aspects to consider before setting up the parameters of your analysis.
The state of the data — preparing for analysis
With some idea about the direction and requirements of your analysis, it's time to inventory your existing data, and to gauge possible future data sources. This process is different for every case — some analysts are newcomers in a large and well-oiled machine, so they simply need to understand the landscape of tools and data in order to produce their analysis, while others have to deal with a chaotic data architecture.
Still others have to collaborate to build the systems that will collect and aggregate the data before analysis is possible. In large organizations, it’s common for all of these situations to exist at the same time across different parts of the company.
Proactive versus reactive data management
When designing a customer data management scheme, a paramount concern is acquiring and providing all the data that will be required by internal analysts. Ideally you already know all the information you want to measure, and can simply implement data systems to carry out your queries.
In reality, instrumentation of data flows is often reactive, testing ideas and moving data in response to new developments in the business. After all, anyone capable of perfectly predicting their business’ growth and the analysis necessary to facilitate that growth would hardly need to do analysis at all. Therefore, when assessing existing data systems, keep in mind two primary stumbling blocks that might send you back to the drawing board:
- Insufficient existing data infrastructure needs to be extended to support new kinds of analysis.
- New data needs to be collected into the existing infrastructure to test new hypotheses.
Every data analyst will certainly encounter both of these issues, and may create the requirement for one while solving the other (for example, analyzing new hypotheses reveals the need for new infrastructure). Data management is an iterative process; as long as this type of hurdle is resolved in an organized way that improves the health and scalability of the overall system, there is nothing wrong with encountering such challenges. After all, analysis is an ongoing feedback loop of new insights and new infrastructure.
Generating and managing your data
With the context of your extant available data, as well as honest assessment of any shortcomings, it's possible to define the data updates you need to conduct successful analysis.
What data to collect
Generating new data is an important component of many customer data analysis roles. Try to select data that will fit your current needs, but that might also be applicable to future projects. A keen understanding of company key performance indicators (KPIs) and milestones is good here, as you'll be able to predict gaps in future needs based on what might be measured for those targets.
Sanitize and standardize
Duplicate data is almost as problematic as erroneous data. To keep things clean in your data warehouse, start at the source. Ensure any new metrics are consistent with extant data where possible: standardize the timestamp format, sanitize postal addresses, unify internal ID conventions, and so on.
The data warehouse
Most modern companies put everything in a data warehouse, on which different tools and mechanisms can be used. Depending on your role, it might be that you have little direct contact with a central warehouse, but it's worth understanding the principles in any case.
A central “source of truth” like a data warehouse can keep all your data and your generated insights and extrapolations. But as more data is added and more varieties of information are stored away, complexity rises. Approaches like a data lake or big data systems can handle complexity at scale. The choice between these options depends on the scale that you need, as well as the capacity of your engineers and budget — but generally a data warehouse is a solid all-around choice for data storage and integration for most companies.
A key feature of a data warehouse is that it offers company-wide access, so your documented data and analysis can be a boon to others looking to provide insight or visualization of business internals.
Unpacking the toolbox
We’ve discussed a number of factors that inform which tools you might want to use for analysis, but there are some core considerations that are crucial to these decisions.
Data stack maturity
For companies early in their data maturity journey designing their Starter Stack, a strong foundation is the foremost concern. Appropriate, clean data system fundamentals must take precedence over any particular line of analysis. At this stage, an analyst’s role is often focused on answering basic questions while also considering long-term uses for the data, and what that will require of the data stack.
Conversely, maturing companies will need to expand from this stack. Once a company hits the Growth Stack phase, the analyst is seeking to synthesize new insight by joining diverse data from various sources. This requires new tooling, as does moving from the Growth Stack phase into the ML Stack phase and potentially into the final frontier, the Real-Time Stack. The important thing to note here is that the expansion of the data stack should be driven by clear goals and accompanying business needs.
Nuts and bolts
Throughout this article, we have touched on the four core elements of a data analysis stack: storage, pipelines, modeling and visualization. Compared to the hard work of developing a clear, useful direction for your analysis to take, picking out the right tools for the job can seem easy.
A common technique for picking specific software in the stack is the warehouse-first approach. By first centralizing your data in a warehouse, you provide flexibility and scaling to address new directions of analysis, security for high quality data, and efficiency in processing.
There are several ways to go, even with a warehouse-first approach. You’ll find some helpful guidance and high level architectures in our Data Maturity Guide. In the end, you are the best expert on your product, your analysis, and therefore the tools that suit your purposes. Given a thorough plan for analyzing data, the clear choices for tools often fall into place.
On-premises versus cloud customer data analytics
As is the case with most modern software, there is a core split between self-hosted on-premises deployment (often using open-source technologies) and cloud-based solutions. There are advantages and disadvantages to each. A long-term consideration that is often determinative in selecting products is the issue of vendor lock-in: open-source solutions allow firms to retain control of their own data and to adapt less painfully to new technologies and services.
In the end, you want to select tools and hosting choices that will provide the least friction in the turn-around from noise to signal, and sometimes a prefabricated, proprietary tool is the best fit for a project.
Let your queries fly
As we have seen, an analyst with good theoretical principles can generate insights from customer data analytics while their company progresses along its journey toward data maturity. Check out the rest of our learning center to dive deeper into the underpinnings of data analytics.