What is an Identity Graph?
Identity resolution demonstrates clear benefits to a modern company. This demands that marketing, sales, and executives understand the underlying technology to make the best use of its capabilities. Even for those without a technical background, the identity graph — a map that enables identity resolution and identity-related data work — is crucial to literacy in modern digital marketing.
If you’re unfamiliar with the scope and benefit of identity resolution, we suggest you refer to our article on the topic for a foundation before diving into identity graphs.
The problem solved by identity graphs
Databases are often thought of as simple collections of two-dimensional tables, but modern data requires a more advanced data model with more advanced insertion and lookup. Data warehouses are commonly used to maintain large quantities of data with quick lookup and good tooling integration, but primarily serve to organize different types of data along a time axis. This makes sense, given that data end users across the organization are often interested in data in the context of time. For example, data requirements often take the form of “how long since a user performed an event” or “how many leads did we get this week”.
When pursuing identity resolution however, our main concern is compressing data along a "customer" axis, where it can then be integrated into a larger context of business data.
That means that a new type of data structure is called for in solving the issues of identity resolution. It must be able to scale to massive numbers of nodal connections (person to person, customer to device, device to website event, etc.) It must also have quick indexing and lookup, so that new data with unclear identity can be quickly and efficiently matched to a probable customer. The tool for these jobs is the graph database.
Nuts and bolts
A graph database is an approach to data storage that focuses on the connections between nodes. Rather than joining tables to see relationships between data points, a graph represents those relationships as a web of connections in their original forms and places, without any further processing. Searching for connections in a graph is therefore much lower latency than a relational database, with a lower cost in computational resources, labor, and technical difficulty.
Identity graphs are typically organized around a particular customer's unique identifier. This node can be generated for an anonymous session, to represent an unresolved identity that nonetheless has data to be collected, or for a known user with good biographical data. These can be referred to as non-authenticated profiles or authenticated profiles respectively.
An identity graph incorporates models that help it ingest new information. As a new datapoint is added, with whatever connections are immediately known, the graph database will determine if it fits into any existing customer identifier. If there is a clear link — such as a matching device ID or conclusive biographical data like a credit card number — the graph will incorporate the data into the relevant user node as a deterministic match. Less certain data, in the form of something like a multi-user account ID or an IP address, is directed through modeling to create a probabilistic match to a unique user. Since the need for absolute certainty varies between business functions (e.g. legal compliance vs general marketing outreach), graph systems often offer operation in both ways, presenting a deterministic node network, or one that includes probabilistic matches as well.
In most cases, non-authenticated user nodes and probabilistic matches can be revisited with additional data to increase resolution as more data becomes available.
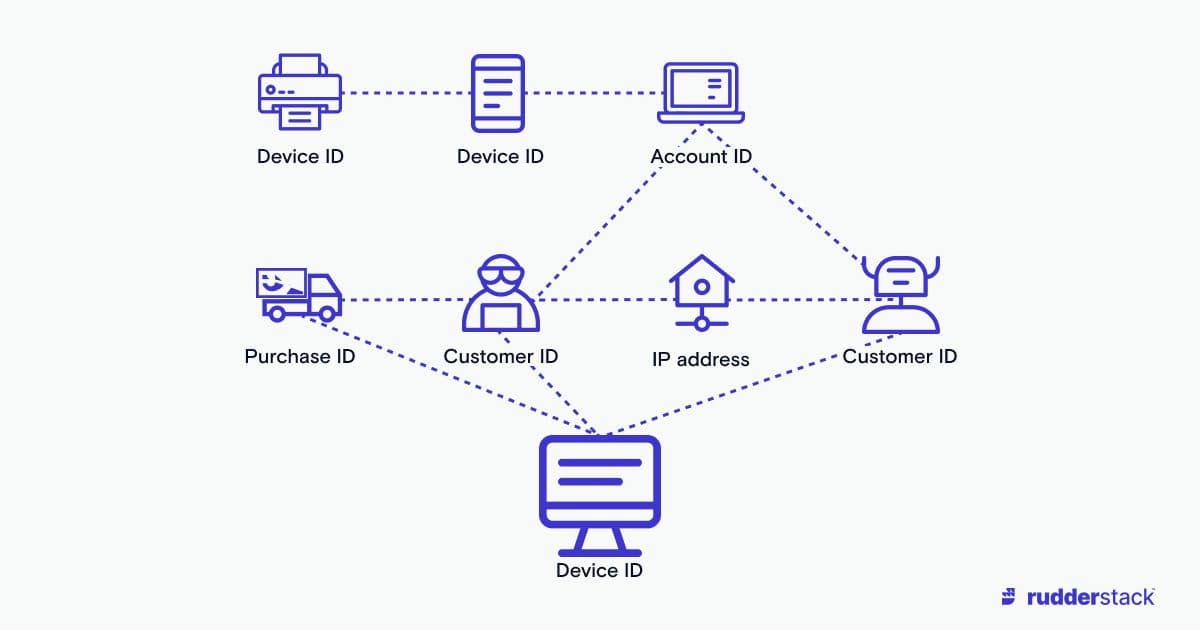 Non-biographical information can be ambiguous when multiple customers are connected.
Non-biographical information can be ambiguous when multiple customers are connected.Who is marketing the identity graphs?
Digital identity databases are a valuable commodity, often the crown jewels of a marketing-focused company. Safe storage and distribution of an identity graph is an important part of their function. Additionally, due to the scaling synergy of identity resolution (the more you know about a customer, the easier it is to learn more), more populated identity graphs are almost always better.
This means there are two general approaches for using an identity graph. For smaller-scale firms, a third-party identity provider is sometimes the correct choice. By using a vendor with large-scale access, you can leverage much greater identity resolution than is available from your proprietary information. On the other hand, third-party identity vendors typically closely guard the insights available, often only providing you with final classification of users and not with access to the underlying identity graphs. Depending on your use case, this means you may not be able to maximize your value from identity resolution without in-house approaches.
Proprietary graphs, derived from information you’ve collected, are used to gain as much market insight as possible. Some approaches use both third-party identity resolution and internal systems to squeeze the maximum inferred knowledge about customer populations from incoming information. In some cases, by protecting your identity graph internally, you can even generate another source of value by offering access to your proprietary graph to those interested in your customer demographic.
Regardless of the third-party/in-house mixture you employ, data privacy regulations are an important consideration in the cost of implementing such a system. If you use a third-party vendor, some of the legal liability may be offloaded from your firm, even if it does not impact potential reputational damage.
Identity graphs: a microscope for your market
As the accessibility of devices expands, resolution of digital identity is only going to become a more important tool for marketing and business analysis. While it is helpful to understand identity graphs, the engine underlying identity resolution, it may also help your research to dive into the fuel that supplies this important system.
Look at our learning center, where we offer additional articles on customer data, advanced data storage, and more:
The Data Maturity Guide
Learn how to build on your existing tools and take the next step on your journey.
Build a data pipeline in less than 5 minutes
Create an accountSee RudderStack in action
Get a personalized demoCollaborate with our community of data engineers
Join Slack Community