Data Warehouse Architecture
Data warehouses are incredibly flexible and scalable when it comes to storing and processing a wide variety of data. For example, if you need to analyze data from multiple sources like Salesforce and Stripe, along with behavioral data from your website or app, having it centralized makes building all kinds of use cases much easier. At scale, centralizing data is necessary because of the sheer quantity.
While centralization is great, if the data isn’t stored in an efficient system, cost and latency can limit usability and query execution. Also, if the data isn’t organized well, the lack of structure will create unnecessary work for data engineers and analysts working in the warehouse.
Data warehouse architecture is the process of designing the structure and format of datasets in a data warehouse. The goals of data warehouse architecture are to maximize both usability and efficiency.
In this article, you’ll learn more about how data warehouses work, cover various data warehouse architectures and learn best practices for managing your own warehouse.
The Key Elements of a Data Warehouse Architecture and How They Work
Understanding the fundamentals of how data warehouses store and work with data is key to making good architectural decisions. In this section, we will look at how data warehouses differ from other forms of data storage, including both the technical differences and the ways in which these differences impact how you should structure your data.
Technical Features: How Data Warehouses Function
This section covers several key explanations of how data warehouses are built specifically for analytical and computational use cases.
Columnar storage
First, we will cover a feature that is invisible to you as the end user, but highlights why you shouldn’t use certain types of databases as a data warehouse.
Let’s say you’re analyzing data for a retailer that sells TVs. When customers make a purchase, those transactions are stored in a database.
Traditionally, when a database records a transaction in a row, all fields in that row contain a value related to that particular transaction. In this scenario, storing all rows in contiguous blocks) on a hard drive makes perfect sense.
The following example outlines how a row-based database stores transaction lines for a store that sells televisions (yes, in reality, it's a little more complex).
While this might look like the structure of a typical table in a data warehouse, working with the data in a relational database management system (DBMS) like MySQL or PostgreSQL is different than working with it in a warehouse. While a tool like PostgreSQL is perfectly capable of calculating the total number of sold devices by Samsung (which you need for your analysis), it probably has to access a lot of disk storage blocks to do so. That's very inefficient. Not only that, but these blocks contain a lot of data that’s unnecessary for this particular calculation. Ad hoc analyses rarely require all columns, so it's safe to say that row-based systems aren't suited for (or are at least suboptimal at) analytical queries, which is a primary use case for data warehouses.
Ease of use for analysis and computation is a big reason why companies that run production databases like PostgreSQL also run cloud data warehouses, and that's why most data warehouses store their columns in contiguous blocks. Here's what the same example would look like in a column-oriented database:
Again, this is invisible to you as a user, but columnar storage is a fundamental technical principle of data warehouses that make them distinct from other types of databases and provide multiple benefits, especially for analysis work:
- Fewer blocks need to be accessed
- These blocks do not contain unneeded data
- Storing homogeneous data within a single block enables better compression
Separation of storage and processing
Operational databases are designed for processing lots of transactions at millisecond latency. Keeping storage close to computing power is a big help in ensuring ACID properties, which are intended to ensure validity of data even in the event of errors. Having guarantees is critical when running production databases.
When your main purpose is analysis and computation, though, you don’t require rigid ACID properties. In that scenario, keeping storage close to compute is often costly and unnecessary. Typically, when data is stored on local drives attached to the processing nodes, database systems partition the data so that each node owns a portion of the data. Scaling a database in this way requires that the whole cluster of nodes be rebalanced when adding additional nodes. Otherwise, some nodes will remain idle when there's no data allocated to them.
That's where the decoupling of storage and compute comes in. When storage is added via a network, you can add a node and point it to one of the existing network drives. This way, the new node can get ownership over a portion of the data without actually moving that data from one partition to another. Furthermore, if a node fails, no data is lost—not even temporarily. That's because the other nodes in the cluster can also access the data that initially belonged to the failed node.
For you as a data warehouse user, this means that you can manage data storage and computation distinctly to meet the specific needs of your use case without having to worry about cost or inefficiencies.
Massively parallel processing
By moving their analytical workloads to the cloud, organizations open the doors to virtually unlimited storage and computing power. The benefit? Queries that used to take days—or that broke production systems altogether—can now get answers in seconds. The secret ingredient is massively parallel processing, or MPP.
It shouldn't surprise you that adding more servers (horizontal scaling) to a database system can speed up queries. But for decades, this was an extraordinarily complex and expensive architecture to manage.
That changed when major cloud providers abstracted these difficulties away by offering data warehouses as a service. Amazon Web Services has Redshift. Google Cloud Platform has BigQuery. Here's how a Google whitepaper boasts BigQuery's capabilities: "You would need to run 10,000 disk drives and 5,000 processors simultaneously to execute the full scan of 1TB of data within one second. Because Google already owns a huge number of disk drives in its own data centers, why not use them to realize this kind of massive parallelism?"
The enormous success of cloud data warehouses is responsible for the rise of dedicated vendors such as Snowflake and Firebolt.
Functional Features
Of course, these technical bells and whistles would be pointless if they didn't come with any functional benefits for the people actually using data warehouses. Below, you can find six of them: speed, cost, instantaneousness, zero-maintenance, scalability, and availability.
Speed: The be-all and end-all for data warehouses is their speed. There are many benchmarks out there, and frequently these result in all-out war. Although independent benchmarks don't always line up and vendors dispute each other's results, it's indisputable that cloud data warehouses drastically reduce time to insight.
Zero startup costs: Using a cloud data warehouse means no investments in physical hardware and no fees for expensive consultants to manage it. The costs for storing data in a cloud data warehouse are ridiculously low, and the price for processing data often runs on a per-query basis.
Instant deployment: In the case of Redshift, deploying a data warehouse is a matter of minor configurations. For Snowflake, you only need to select a cloud provider. And BigQuery is entirely serverless. In other words, getting started with your data warehouse has never been easier.
Zero-maintenance: Because cloud data warehouses are software as a service (SaaS), maintenance isn’t a concern. No one needs to monitor the performance of underlying hardware to ensure that the CEO gets his weekly report on time.
Scalability: Because compute and storage are strictly separated, it's possible to modify the system's configuration dynamically. A serverless data warehouse like BigQuery even scales resources on a per-query basis.
Availability: The separation of processing power and storage is also responsible for near-perfect availability. There are no nodes to manage, and there’s no downtime with a cloud provider that has network centers across the globe.
Designing a Data Warehouse Architecture
At this point you should have a basic understanding of how data warehouses are built, how they differ from other kinds of databases and why you should consider using one for your analytical and computational needs.
In this section, we’ll dive into the organizational side of data warehouse architecture and outline best practices for managing data in your warehouse.
Data Types
Typically, data warehouses support all kinds of structured data, and some even support semi-structured data. The following types of data are relevant in a variety of contexts.
Since data warehouses generate a lot of interest from within business intelligence and marketing analysis communities, organizations tend to prioritize data sets related to their customers and their buying behavior, so that’s where we will focus in this article.
Transaction and order lines are an obvious first pick. That's because sales, purchases, revenue and margin all go into a company’s most valuable and sought after reports. But that's not the only reason. Transactions are usually stored in a data repository (such as an OLTP database) owned and maintained within the company and it’s not difficult to get that data into a data warehouse. In addition to traditional ETL data flows, rarely does setting up a data replication pipeline from a transactional database to a data warehouse require third-party integration software. Complete database dumps or SQL statement logs often suffice.
Another point of interest is the data stored within an organization's customer relationship management (CRM) tool. It shouldn't surprise you that salespeople looking for new opportunities want to know who their customers are—or aren't. The same can be said of marketing departments. They're in the business of promoting the right products and services to the right customers. Combining transaction data with CRM or marketing automation data to get to those insights is an easy win.
Both transaction data and customer properties are explicit data intentionally provided by the customer. But organizations can also acquire implicit data, which can be collected by monitoring how users or customers interact with their (often digital) channels.
- Email: Tools like Braze, Mailchimp and Marketo store information on every email that is sent out: who it’s delivered to, who opens it, who clicks on a link. Adding that engagement data to your transactional and CRM can produce even more interesting analyses. Getting the data out can be done programmatically or by using data integration tools that maintain connectors for interfacing with these tools' APIs.
- Web: A popular way for tracking web behavior is Google Analytics, which integrates seamlessly with BigQuery (Google's cloud data warehouse). But there are other tools like Snowplow and RudderStack, which can stream directly into your data warehouse.
- App: Installing tracking on websites has become less painful throughout the years. Nowadays, tools that are mostly installed for tracking web behavior can also be used for tracking app interactions.
It doesn't end here. With support for all kinds of structured and semi-structured data, there are nearly infinite use cases for which a data warehouse is the most suitable data repository.
When storing this data, it’s helpful to think about the hierarchy of the data as it relates to your specific business and analytical needs. For example, you may want to group your website, app and email event data together in a set of tables, but separately from relational customer records from your CRM.
Creating clear structures that align with your business logic makes writing queries and onboarding new analysts much easier.
Schema
Fetching a lot of data is one thing; storing it in the most suitable way for your use case is another. In operational databases, data typically gets normalized, resulting in a snowflake or a star schema. That has two significant advantages. First, storing all dimensions in separate tables makes transactions more compact. Second, it deduplicates data and reduces storage volumes.
However, data warehouses are mainly used for reading operations. Furthermore, given the separation of storage and computing power, reducing storage volumes isn't a concern. This raises the question: how should one organize data inside a data warehouse?
The answer: flattening tables, or "denormalization."
For example, with storage being extremely cheap, Google recommends optimizing queries instead of schemas in BigQuery: "Denormalization is a common strategy for increasing read performance for relational datasets that were previously normalized. The storage savings from using normalized data has less of an effect in modern systems."
Nevertheless, many vendors offer features so that their customers can have it both ways: optimization of both storage and computing power. Firebolt has semi-structured tables, Redshift has the SUPER data type, and BigQuery has nested and repeated fields. This way, data redundancy can be avoided while optimizing query speed and keeping costs down.
And what about slowly changing dimensions? For example, when a user in your database changes addresses, do you overwrite his previous location? Or do you want to keep a historical overview? There are at least half a dozen ways of handling this issue, but without storage volume concerns, this isn't much of a problem for a data warehouse.
- If your data arrives via an event stream, you'll always have an event timestamp, which can be used to keep track of historical changes to a particular field.
- If your data arrives in batch (e.g., per day via ETL), you'll have the snapshot timestamp. This date field can be used to keep a daily historical log.
Finally, warehouse-first tools like RudderStack come with a predefined schema, meaning the data is automatically organized when it reaches your warehouse. The data these tools generate are optimized for analytical queries and don't require post-processing steps.
From ETL to ELT
With their processing power and storage capacity tightly linked together, tools like OLAP cubes or relational databases were terrible data sinks. You couldn't just dump troves of data in them without sacrificing performance or paying for expensive scaling operations. For this reason, most data warehouse architectures were designed around an ETL workflow.
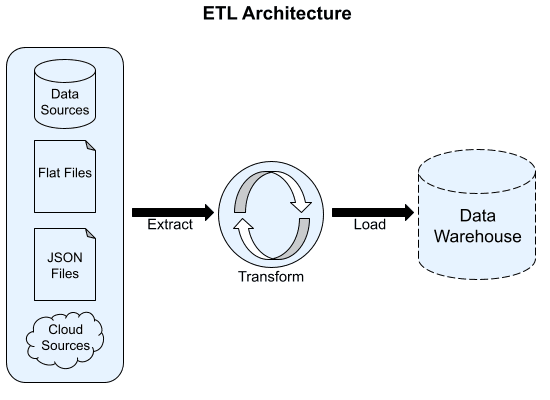
ETL to ELT
ETL is an acronym for extract, transform, and load and describes how data flows from source systems into analytical data stores. In this workflow, data is extracted from source systems into a data sink. In this workflow, data is extracted from source systems into a data sink. The data sink could be as simple as a server with vast storage capacity, but data lakes were built for this exact purpose.
Next, data would flow between the sink (or data lake) and the analytical store through data pipelines that transformed it into its final form. Data teams would use the transformations in this sink process to architect data structure before the data entered their warehouse. Traditionally this ETL process could become complex and span multiple systems, making it hard to manage and troubleshoot.
In the past couple of years, the following three data engineering evolutions were notable:
- Data integration is now completely commoditized by tools such as RudderStack and Fivetran, which provide pipelines directly into the data warehouse.
- Data warehouses now increasingly support the loading of streaming data (e.g., Snowpipe or BigQuery's streaming inserts).
- The third one is a combination of the first two: due to cheap storage, unlinked from processing capacity, the data warehouse can now be leveraged both as a sink and for managing the data pipeline.
These technological evolutions sparked a whole new paradigm known as ELT, an acronym for extract, load, and transform.
In this workflow, data gets extracted directly into the data warehouse from its source system. Remember that most data warehousing technologies also support semi-structured data. Consequently, extracted data in a data warehouse is often completely schemaless.
The ELT workflow allows data teams to separate the process of loading data and architecting the structure of that data in their warehouse, making the process of maintaining a well-organized warehouse even easier.
Although stored procedures and materialized views can theoretically manage the transformation from raw data to perfect tables, the ELT paradigm has spawned a whole new software category of data transformation tooling that allows organizations to transform, model, and track the lineage of their data at scale. Most popular are dbt, Matillion, and Dataform (now Google-owned).
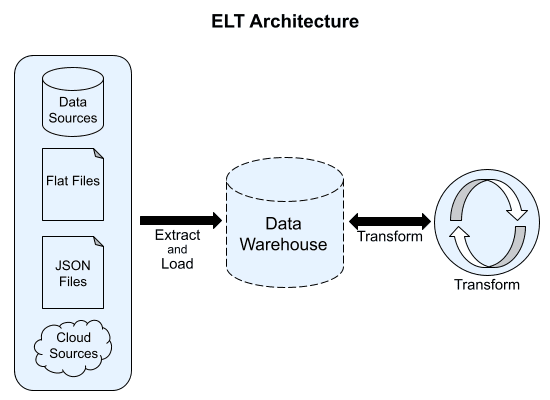
ELT Architecture
Reverse ETL
Once companies have a well-architected warehouse with well organized data, they often discover that they can do more with their warehouse data than simply analyze it for improved decision-making. This ambition often means that the data needs to be extracted from the data warehouse into other (third-party SaaS) tools. Think about the following data-driven use cases:
- Segments for personalizing Google search and display ads based on transaction data
- Personalized emails in your marketing campaigns based on sales intelligence from your CRM
- Propensity scores to feed your product recommendation engine
- Survey recipient selection based on customer support ticket data
- Next-best-action scores for contacts in a CRM
The challenge is that even if you compute all of those audiences and metrics, they are trapped in your data warehouse.
Until recently, it was very cumbersome to maintain integrations from your data warehouse with each product where you wanted to send enriched data (i.e., CRM, marketing tool, customer support tool, etc.). However, with data warehouses taking up an increasingly important role in the stack, another new warehouse-first software category rose to prominence: the Reverse ETL pipeline. While traditional data integration tools focus on getting data out of SaaS applications, reverse ETL tools like RudderStack Reverse ETL and Hightouch are focused on moving data back into them.
Having a clear, structured architecture in your data warehouse makes the process of operationalizing it via reverse ETL that much easier.