Data Analytics Lifecycle
The data analytics lifecycle is a structure for doing data analytics that has business objectives at its core. Following this structure will help you better understand your data and improve the effectiveness of your data analytics work. In addition to showing you a data analytics lifecycle tailored to meeting business objectives, this article describes the six phases in this lifecycle, gives further information about each phase, and explains the benefits of following the data analytics lifecycle.
What is the data analytics lifecycle?
The data analytics lifecycle is a series of six phases that have each been identified as vital for businesses doing data analytics. This lifecycle is based on the popular CRISP-DM analytics process model, which is an open-standard analytics model developed by IBM. The phases of the data analytics lifecycle include defining your business objectives, cleaning your data, building models, and communicating with your stakeholders.
This lifecycle runs from identifying the problem you need to solve, to running your chosen models against some sandboxed data, to finally operationalizing the output of these models by running them on a production dataset. This will enable you to find the answer to your initial question and use this answer to inform business decisions.
Why is the data analytics lifecycle important?
The data analytics lifecycle allows you to better understand the factors that affect successes and failures in your business. It’s especially useful for finding out why customers behave a certain way. These customer insights are extremely valuable and can help inform your growth strategy.
The prescribed phases of the data analytics lifecycle cover all the important parts of a successful analysis of your data. While the order can be deviated from, you should follow all six steps, as missing one out could lead to a less effective data analysis.
For example, you need a hypothesis to give your study clarity and direction, your data will be easier to analyze if it has been prepared and transformed in advance, and you will have a higher chance of working with an effective model if you have spent time and care selecting the most appropriate one for your particular dataset.
Following the data analytics lifecycle ensures you can recognize the full value of your data and that all stakeholders are informed of the results and insights derived from analysis, so they can be actioned promptly.
Phases of the data analytics lifecycle
Each phase in the data analytics lifecycle is influenced by the outcome of the preceding phase. Because of this, it usually makes sense to perform each step in the prescribed order so that data teams can decide how to progress: whether to continue to the next phase, redo the phase, or completely scrap the process. By enforcing these steps, the analytics lifecycle helps guide the teams through what could otherwise become a convoluted and directionless process with unclear outcomes.
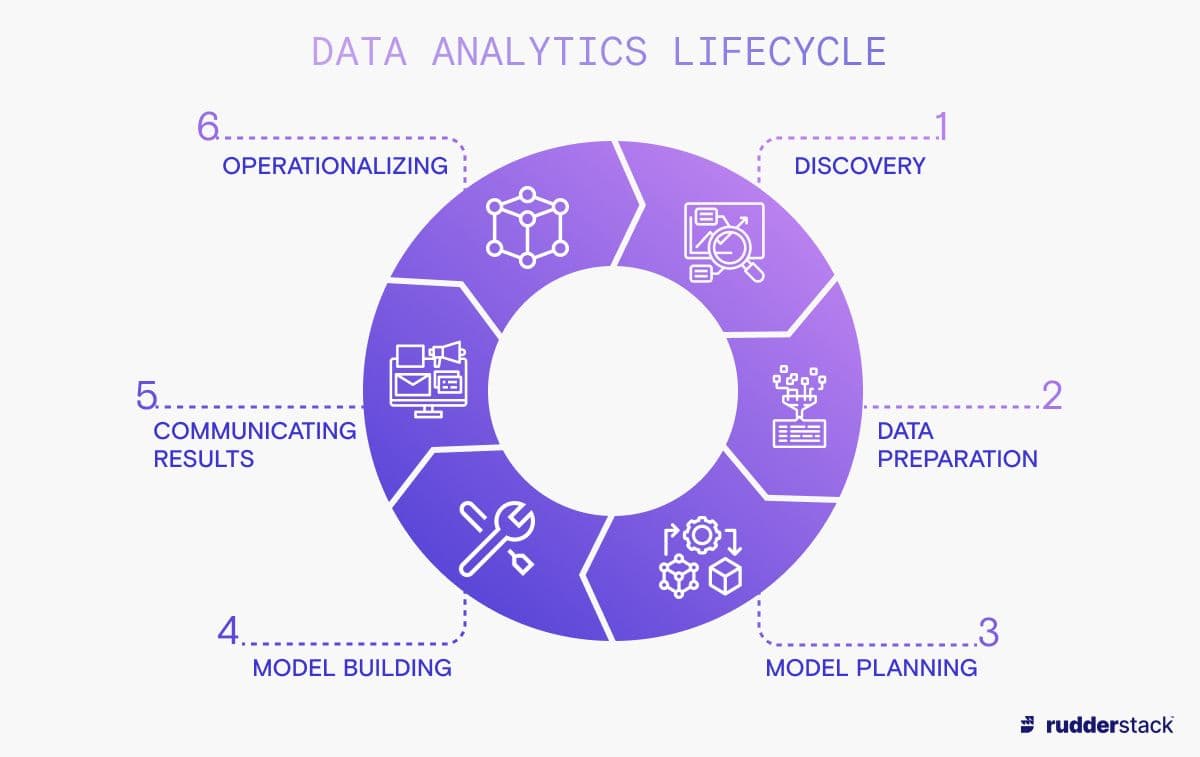
1. Discovery
This first phase involves getting the context around your problem: you need to know what problem you are solving and what business outcomes you wish to see.
You should begin by defining your business objective and the scope of the work. Work out what data sources will be available and useful to you (for example, Google Analytics, Salesforce, your customer support ticketing system, or any marketing campaign information you might have available), and perform a gap analysis of what data is required to solve your business problem analysis compared with what data you have available, working out a plan to get any data you still need.
Once your objective has been identified, you should formulate an initial hypothesis. Design your analysis so that it will determine whether to accept or reject this hypothesis. Decide in advance what the criteria for accepting or rejecting the hypothesis will be to ensure that your analysis is rigorous and follows the scientific method.
2. Data preparation
In the next stage, you need to decide which data sources will be useful for the analysis, collect the data from all these disparate sources, and load it into a data analytics sandbox so it can be used for prototyping.
When loading your data into the sandbox area, you will need to transform it. The two main types of transformations are preprocessing transformations and analytics transformations. Preprocessing means cleaning your data to remove things like nulls, defective values, duplicates, and outliers. Analytics transformations can mean a variety of things, such as standardizing or normalizing your data so it can be used more effectively with certain machine learning algorithms, or preparing your datasets for human consumption (for example, transforming machine labels into human-readable ones, such as “sku123” → “T-Shirt, brown”).
Depending on whether your transformations take place before or after the loading stage, this whole process is known as either ETL (extract, transform, load) or ELT (extract, load, transform). You can set up your own ETL pipeline to deal with all of this, or use an integrated customer data platform to handle the task all within a unified environment.
It is important to note that the sub-steps detailed here don’t have to take place in separate systems. For example, if you have all data sources in a data warehouse already, you can simply use a development schema to perform your exploratory analysis and transformation work in that same warehouse.
3. Model planning
A model in data analytics is a mathematical or programmatic description of the relationship between two or more variables. It allows us to study the effects of different variables on our data and to make statistical assumptions about the probability of an event happening.
The main categories of models used in data analytics are SQL models, statistical models, and machine learning models. A SQL model can be as simple as the output of a SQL SELECT statement, and these are often used for business intelligence dashboards. A statistical model shows the relationship between one or more variables (a feature that some data warehouses incorporate into more advanced statistical functions in their SQL processing), and a machine learning model uses algorithms to recognize patterns in data and must be trained on other data to do so. Machine learning models are often used when the analyst doesn’t have enough information to try to solve a problem using easier steps.
You need to decide which models you want to test, operationalize, or deploy. To choose the most appropriate model for your problem, you will need to do an exploration of your dataset, including some exploratory data analysis to find out more about it. This will help guide you in your choice of model because your model needs to answer the business objective that started the process and work with the data available to you.
You may want to think about the following when deciding on a model:
How large is your dataset? While the more complex types of neural networks (with many hidden layers) can solve difficult questions with minimal human intervention, be aware that with more layers of complexity, a larger set of training data is required for the neural network's approximations to be accurate. You may only have a small dataset available, or you may require your dashboards to be fast, which generally requires smaller, pre-aggregated data.
How will the output be used? In the business intelligence use case, fast, pre-aggregated data is great, but if the end users are likely to perform additional drill-downs or aggregations in their BI solution, the prepared dataset has to support this. A big pitfall here is to accidentally calculate an average of an already averaged metric.
Is the data labeled with column headings? If it is, you could use supervised learning, but if not, unsupervised learning is your only option.
Do you want the outcome to be qualitative or quantitative? If your question expects a quantitative answer (for example, “How many sales are forecast for next month?” or “How many customers were satisfied with our product last month?”) then you should use a regression model. However, if you expect a qualitative answer (for example, “Is this email spam?”, where the answer can be Yes or No, or “Which of our five products are we likely to have the most success in marketing to customer X?”), then you may want to use a classification or clustering model.
Is accuracy or speed of the model particularly important? If so, check whether your chosen model will perform well. The size of your dataset will be a factor when evaluating the speed of a particular model.
Is your data unstructured? Unstructured data cannot be easily stored in either relational or graph databases and includes free text data such as emails or files. This type of data is most suited to machine learning.
Have you analyzed the contents of your data? Analyzing the contents of your data can include univariate analysis or multivariate analysis (such as factor analysis or principal component analysis). This allows you to work out which variables have the largest effects and to identify new factors (that are a combination of different existing variables) that have a big impact.
4. Building and executing the model
Once you know what your models should look like, you can build them and begin to draw inferences from your modeled data.
The steps within this phase of the data analytics lifecycle depend on the model you've chosen to use.
SQL model
You will first need to find your source tables and the join keys. Next, determine where to build your models. Depending on the complexity, building your model can range from saving SQL queries in your warehouse and executing them automatically on a schedule, to building more complex data modeling chains using tooling like dbt or Dataform. In that case, you should first create a base model, and then create another model to extend it, so that your base model can be reused for other future models. Now you need to test and verify your extended model, and then publish the final model to its destination (for example, a business intelligence tool or reverse ETL tool).
Statistical model
You should start by developing a dataset containing exactly the information required for the analysis, and no more. Next, you will need to decide which statistical model is appropriate for your use case. For example, you could use a correlation test, a linear regression model, or an analysis of variance (ANOVA). Finally, you should run your model on your dataset and publish your results.
Machine learning model
There is some overlap between machine learning models and statistical models, so you must begin the same way as when using a statistical model and develop a dataset containing exactly the information required for your analysis. However, machine learning models require you to create two samples from this dataset: one for training the model, and another for testing the model.
There might be several good candidate models to test against the data — for example, linear regression, decision trees, or support vector machines — so you may want to try multiple models to see which produces the best result.
If you are using a machine learning model, it will need to be trained. This involves executing your model on your training dataset, and tuning various parameters of your model so you get the best predictive results. Once this is working well, you can execute your model on your real dataset, which is used for testing your model. You can now work out which model gave the most accurate result and use this model for your final results, which you will then need to publish.
Once you have built your models and are generating results, you can communicate these results to your stakeholders.
5. Communicating results
You must communicate your findings clearly, and it can help to use data visualizations to achieve this. Any communication with stakeholders should include a narrative, a list of key findings, and an explanation of the value your analysis adds to the business. You should also compare the results of your model with your initial criteria for accepting or rejecting your hypothesis to explain to them how confident they can be in your analysis.
6. Operationalizing
Once the stakeholders are happy with your analysis, you can execute the same model outside of the analytics sandbox on a production dataset.
You should monitor the results of this to check if they lead to your business goal being achieved. If your business objectives are being met, deliver the final reports to your stakeholders, and communicate these results more widely across the business.
Following the data analytics lifecycle improves your outcomes
Following the six phases of the data analytics lifecycle will help improve your business decisions, as each phase is integral to an effective data analytics project. In particular, understanding your business objectives and your data upfront can be super helpful, as can ensuring it is cleaned and in a useful format for analysis. Communicating with your stakeholders is also key before moving on to regularly running your model on production datasets. An effective data analytics project will give useful business insights, such as the ability to improve your product or marketing strategy, identify avenues to lower costs, or increase audience numbers.
A customer data platform (CDP) will vastly improve your data handling practices and can be integrated into your data analytics lifecycle to assist with the data preparation phase. It will transform and integrate your data into a structured format for easy analysis and exploration, ensuring that no data is wasted and the full value of your data investment is realized.
Further reading
In this article, we defined the data analytics lifecycle and explained its six phases. If you’d like to learn about other areas of data analytics, our learning center has a series of useful articles on this subject, including: