Collecting Customer Data
It’s no secret that data has become the most precious commodity to today’s leading businesses. When properly mined, data can enable powerfully effective marketing and game-changing growth strategies. To make the most of your collected data, it’s important to understand and implement a variety of business-relevant approaches; from handling different types of customer data, managing data storage, and using the data processing tools that will turn raw data into actionable insights.
However, in researching and designing data systems, it’s easy to gloss over the very first step in the lifecycle of customer data: Data Collection.
When it comes to hunting business-relevant information, one of the trickier types of prey is customer data. It’s difficult to know how to collect customer data because customers are diverse, self-selecting, and discreet about sharing their data, plus, the legal restrictions on customer data are different from those on other data sources.
Further complications to the collection of customer data come from siloed or fragmented data collections, as a diverse set of data-generating business segments refract through dozens of websites, apps, SaaS tools, marketing platforms, and more.
Solving these problems by gathering a centralized, coherent, and properly handled repository of customer data is necessary to have a competitive foothold in the data-driven economy.
Starting with the big picture
As with any part of a data project, good data collection starts with an encompassing look at all existing data sources and data projects. Do other teams at your company already harvest the data you’re after? Is your proposed collection in line with company privacy policies? Are there existing projects that could render the new data you’re generating obsolete?
All these questions should be easy to answer with an adequate customer data management plan. With a central view of your business’s entire data operation, you can make sure the data you are targeting constitutes an efficient use of resources.
How does your data arrive?
Customer data is a term for any data provided to you by the customer — a fairly broad definition. We recommend reviewing our article on the taxonomies of data, because there are several useful categories to understand.
Mechanics of data ingestion
Data can arrive from a variety of sources. For example, SDKs deliver behavioral data by logging in-app events, SaaS apps in your stack supply relational data, and system data can be supplied by product databases.
Throughout the lifecycle of customer data, it will also produce secondary information — prediction models, inferred demographics, regression analysis, and more. This data can be ingested throughout the data stack, delivered by analysis software like identity resolution, regression analysis, or similar products. Thus, it's important to keep in mind that, along with primary-source customer data at the top of your data stack, there will be additional inputs to be collected and accessed.
Friction in the data
For the purposes of companies collecting data on customers, we want to focus on a different breakdown — namely, how much work it takes to acquire this data.
If we place different types of customer data on a sliding scale of ease of collection, one end of that scale might be the essential information whose exchange is necessary for the internet to function — IP addresses, browser types, or HTTP headers. This “passive data” is available to essentially anyone on the internet, never requires consent to collect, and is exchanged automatically with no input from the user.
On the other end of that scale, we could put highly obtrusive bits and bytes that require customer consent and explicit input. A street address, customer satisfaction survey, or manual photo geotag are examples of information that require active, intentional input and permission from a customer.
Data from the more active end of the customer data scale can be more productive, but is almost always more difficult to collect. By using the right tools and methodologies, however, it is often possible to infer active data from passive data (for instance, by identity resolution). Additional benefits of this type of inference are less intrusion on the customer's user experience and less risk of falling foul of privacy regulations (where identity resolution is provided by a third party, with their own responsibilities to the data).
Collecting passive data
Let’s break down some common forms of more passive data collection. These are often already available to you from a data warehouse or other storage schema, so collecting them may be as easy as visiting an internal API. If not, processes for adding them are well-documented.
Transactional data
This is collected when customers complete an information exchange with your services, generally a purchase or sale. Other types of transactions worth collecting might be order forms, help tickets, or service line interactions.
This data should be passively available, as transactions occurring on your servers (or anywhere on your data stack) are almost certainly recorded in order to be served in the first place. Often, collecting this data is as simple as getting the relevant information automatically forwarded to a part of your data storage system that you can access.
Identity resolution
As mentioned above, identity resolution is a convenient form of passive data collection that can improve existing data for better performance or even glean more information about a customer using third-party sources. Identity resolution leverages already-collected customer data to enrich itself or other data, generally without any further input from the customer.
Many types of identity resolution do require the services of a vendor (although advanced customer data platforms have native identity resolution services that you can operate in-house), so it might be regarded as a higher-friction data generation scheme than many other passive modes.
Marketing data
This is inferred customer data, usually automatically collected during marketing campaigns and made available by your marketing partners. Metrics like click-through rates or social media interactions can give you a wide-lens view of customer behavior, even if you aren’t getting customer-by-customer data. Although customers are actively generating this data, your company is essentially insulated from any of the overhead of these interactions.
Website or app usage
Keeping tabs on a customer’s journey is necessary for debugging and product design in front-facing services. If you want to use this tracked information for insights into customer sentiment about your product, it may already be freely available to you — or, as with other functional data sets, you may need to request that an engineer set it up to be forwarded to you.
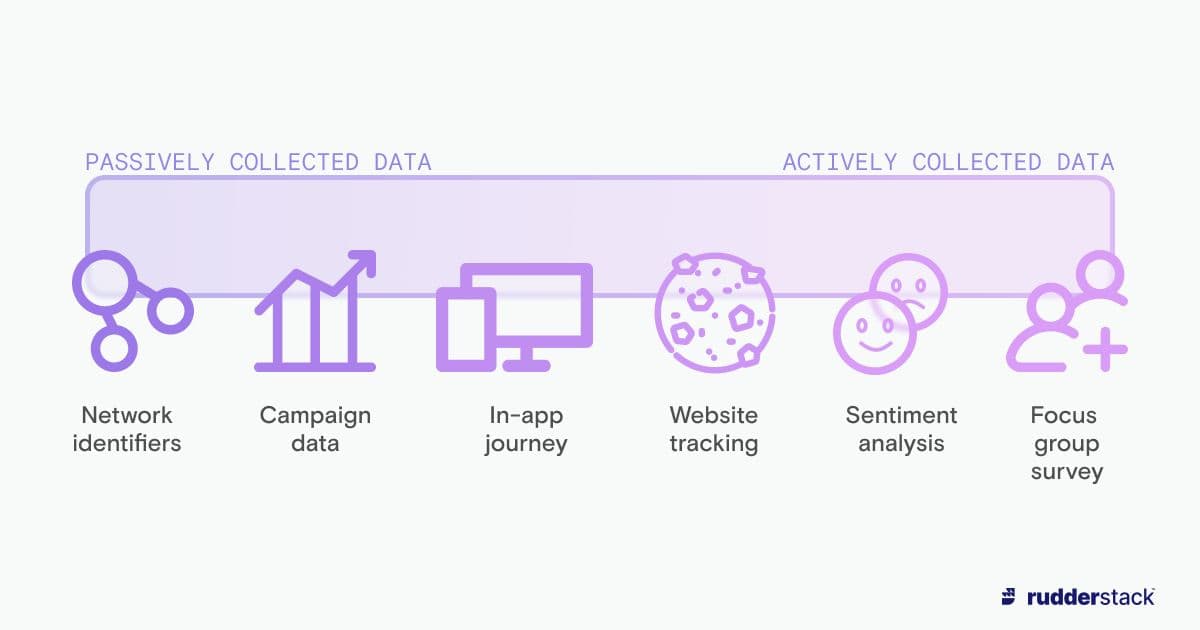
As customer data increasingly involves customer interaction, it generally becomes more difficult to collect.
Active data collection
Sometimes recording existing customer data doesn’t generate the right data for your goals and it's necessary for companies to take a more active hand in customer data collection. Active collection methods range from simply obtaining boilerplate consent for tracking to full-tilt market research experiments. Regardless of difficulty, the following data collection methods require active participation on the part of the customer.
Cookies and privacy compliance
Thanks to the omnipresence of cookie requests since the implementation of GDPR regulations, everyone is acutely aware of the consumer input needed for website tracking. Website usage data and tracking cookies can yield a suite of valuable data, but collections require that checkbox consent.
Surveys
Tailored customer market research is a superpower of customer data collection. Although very expensive compared to most of the methods detailed in this article, it yields highly specific, customizable data to meet your needs.
Customer surveys can be conducted in a distributed and automatic fashion, as in prompting users for reviews, or can be a highly developed focus group survey conducted for you by an outside marketing research firm.
Especially when you commission a survey and recruit participants, take care about the collection of customer surveys. Survey data is not consistently generated, so recognize that the data constitutes a specific timeframe and may not be renewable.
Public third-party platforms
As an alternative to custom surveys, you can also gather customer data on your company from the same place that customers do. Looking at review sites, reading social media interactions, or using sentiment analysis on customer communications around your brand can generate a customer’s-eye view of your products. This perspective shift is very useful for market research, and can yield unique insights.
Trawling for information on your social media pages doesn’t require explicit customer consent, but it is only possible if customers are actively generating interaction data. This often means your brand needs an active presence, including comment-section responses to encourage additional communication from customers.
Sentiment analysis is also a useful but intensive approach to automatically sort through public commentary. This can allow you to automate much of the work of fishing out and interpreting public data, essentially moving this type of data collection into the passive category.
Bringing it all together
Collecting customer data takes many forms. Often it’s as simple as consulting your existing libraries of data with a discriminating eye, but some types of specialized data may require focus groups or specialized research projects. By mapping out what you want, you can extract any number of valuable insights from a sound data collection program.
If you’re looking to learn more about customer data collection best practices, it can be useful to consult big ideas in customer data. Our Learning Center can help you learn about topics like: