Data persistence and persistent data: Understanding the differences
Data persistence and persistent data may sound like exactly the same thing, and while they apply to the same area of data storage, they refer to slightly different aspects.
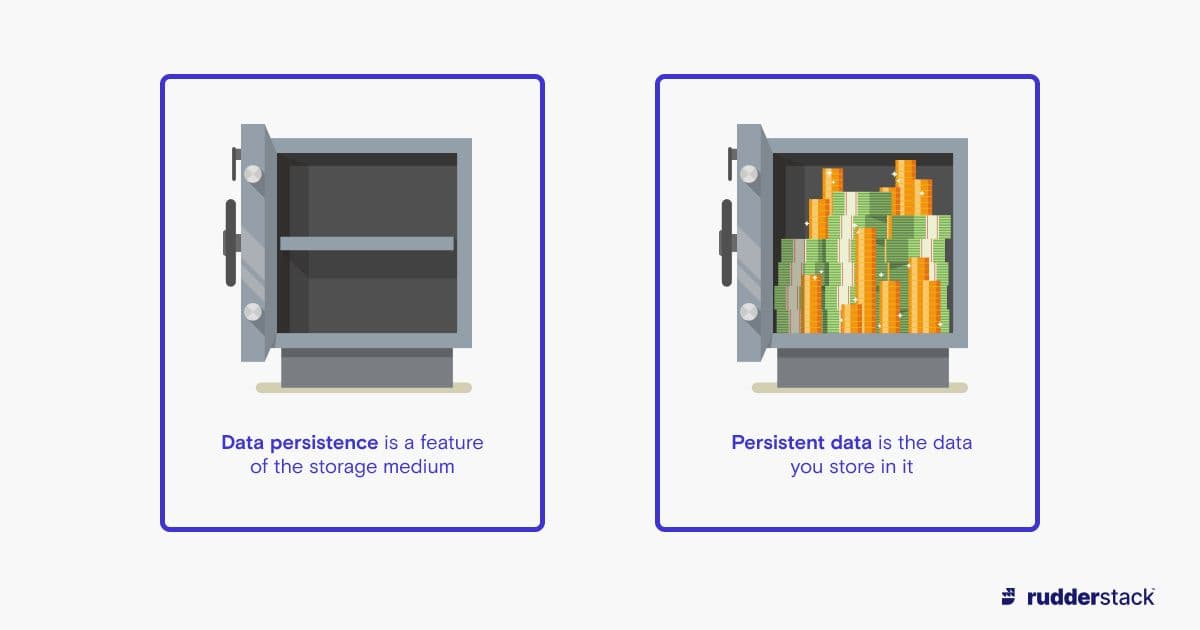
Persistent data is data that is stored on a persistent (long-lasting) storage medium so that it can be retained for long-term use. Data persistence refers to the concept of keeping data for long-term use, as well as the longevity of storage methods and mediums.
This article will explain the difference between persistent data, data persistence, and other related terms. We will also explain the importance of data persistence and outline best practices for handling the data your business will need to maintain for future use.
What is data persistence?
Data persistence is a term that refers to the characteristics of data or data storage methods that allow data to exist after the process of creating it has stopped. For storage to support data persistence, it must be a non-volatile storage medium, such as flash memory (SSDs, USB sticks), hard disks, magnetic tape, and optical media. In contrast, RAM has a low data persistence as the data stored on it is lost when power is removed.
In short, a data persistence definition could be: the field of persisting data as well as the volatility of a data storage method.
What is persistent data?
Persistent data means any data stored on a persistent storage medium where the data remains intact after it has been written until it is overwritten.
Any data that needs to be used after the process that created it has been completed must be stored on a persistent storage medium. For example, invoices are generated during the process of a business making a sale to a customer through their online shop, and need to be kept after that purchase transaction has been completed.
A persistent data definition could be any data, including files and applications, that is saved to non-volatile storage in order to continue being available once the device it was created on is no longer active.
Persistent data vs. non-persistent data
Non-persistent data, also known as ephemeral data, is the opposite. This temporary data is only required by the process that creates it. Ephemeral data can be stored in volatile storage media like computer memory (where data does not survive once the power is removed), which is not suitable for long-term data storage.
For example, while the invoice generated by the sale process for an online shop needs to be retained as persistent data for long-term use, other data, like the user’s shopping cart and the order they sorted the list of products by while browsing, does not need to be persisted. These things are ephemeral data that can be discarded when the sale process has been completed.
Clearing up terminology
Data persistence vs. persistent data
Static data
The term persistent data is sometimes confused with static data. These terms do not refer to the same thing.
Static data refers to the purpose of the data — it describes data that is not intended to be changed (it has become static), rather than the nature of how it is stored. Static data will most likely be persistent data, but not all persistent data is static data.
Dynamic data
Dynamic data is the opposite of static data. It is data that is likely to change — for example, customer records will have the addresses updated when someone moves. Dynamic data can also be persistent data if it is stored on a persistent medium for ongoing use.
Why is data persistence important?
When developing applications like e-commerce platforms, social media apps, or data pipelines, you need to consider how the different data you are generating and collecting is going to be used and stored.
Any data that needs to be available for use after your application’s process has completed must be stored on persistent storage. This goes beyond just holding onto sales transactions. Your business generates highly valuable first-party data throughout its lifecycle that may have future utility. You need to discover which of this data is most valuable, and ensure it is persisted, while data that is only required temporarily can be safely used and discarded.
Persistent data storage can become costly as you generate more and more data and your user base grows. Useless data can also make it difficult to manage your data, hindering analysis. Deciding what data to persist and what not to persist requires careful planning.
For example, when dealing with customer data and data pipelines that consume and format data from multiple sources, the data will most likely undergo transformation, with intermediate data being generated to achieve a final, consistent format. The data in these intermediate steps probably won't be needed again, while the final results will need to be stored on a persistent medium so that they can be capitalized on in the future.
Exploring industry data persistence examples
To better understand data persistence, let’s look at some examples of where it is used in different industries.
E-commerce
The shopping carts on e-commerce websites use data persistence to keep any items you add in the cart until you check out. Thanks to data persistence, items will stay in the cart even if a customer closes their browser or logs in on another device. This makes the shopping experience seamless for the customer and increases the likelihood of sales for the e-commerce business.
Banking
Online banking portals use persistent data to keep transaction and payment records. Users expect to be able to view their transaction details at any time, and wouldn’t have much faith in a bank that ‘forgot’ this sort of data. The use of data persistence means that users can also easily spot fraud, as unexpected payments will show up in the transfer history.
Healthcare
Healthcare institutions rely on data persistence to keep patient medical records accurate and up-to-date. Medical records need to last as long as a patient's life and will be updated by numerous individuals and departments. Data persistence ensures that none of this information is lost and that it can also be accessed by whichever medical professional needs it next.
Social networking
In the context of social media sites, such as Facebook, LinkedIn, and X, the data persistence meaning is the way in which likes, shares, comments, and more are saved for individual users. Even if you log into your account on a different device, you will find your account data. This creates an uninterrupted user experience.
Best practices for data persistence
The goal of data persistence is making sure your data remains available and accessible. The first step toward this is identifying the data that needs to persist. This data will most likely include:
- Master data: Your core business data like employee and customer records, and financial transactions.
- Data from in-house processes: Examples include the raw text and images used by an online magazine to create their content, or data gathered from industrial equipment logging its operation.
- First-party data: Data that you have collected directly from your customers.
- Third-party data: Customer data that has been shared with you through an intermediary (provided you are allowed to store it).
Once this data has been identified, it should be organized and labeled. This will help you find it again in the future, and by marking sensitive data you can ensure that any relevant regulation that applies to it can be met.
When working with databases, normalize your data to reduce redundancy and improve integrity. Unwieldy datasets both waste storage resources and are difficult to work with.
Choose the right level of data persistence
Generally, end users do not need to worry about persistent storage. Consumer-grade applications provide appropriate means to store data for continued use — be it as a file for desktop applications, or on an online platform for cloud apps.
Increasingly, developers are also largely relieved of implementing data persistence at a low level. Most modern application frameworks provide the tools and libraries required to read and write data to a variety of both non-volatile and volatile storage back ends.
If you are developing your own application and deciding between storage options (for example, e-commerce platforms often offer different database back ends for you to choose from), you need to consider the nature of the data you are handling and decide on an appropriate storage medium:
- Pure in-memory storage is offered by many caching solutions for high-speed storage of ephemeral data, with zero persistence.
- In-memory storage with periodic snapshots serves a similar purpose to the above, with limited persistence (for example, so that job queues aren't lost between reboots).
- Disk-based and commit-log-based databases that write their data to disk (for example, MongoDB and SQL databases).
- File systems stored on disk for storing regular files like documents and images, or flat-file databases like CSV and JSON data.
When choosing the data you wish to store, and the way you will be storing it, you will need to weigh the cost of retaining the data on that medium against the ongoing usefulness of the data. Third-party customer data goes stale quickly, as demographics and audience demands change, while first-party data specific to your business is usually valuable for a longer period.
For long-term storage with ready availability, especially of analytics data, data lakes and data warehouses make a good choice.
Make use of cold storage
Cold storage refers to storage that is not kept online when it is not in use. Data is transferred to the cold storage medium, and then it is disconnected and stored in a secure physical location. For example, transferring data to a portable hard disk and keeping it disconnected in a safe is considered cold storage.
Cold storage on hard disks or tape is a cost-effective way of storing bulk data long-term, as the storage can usually be purchased cheaply and does not have to be in continuous operation.
Cold storage on a reliable, highly-persistent storage medium is also appropriate for protecting vital data that does not need to be readily accessed (for example, backups of your core business and first-party data). As it is offline, it cannot be hacked into or interfered with, unlike data that is constantly available on your device or network.
Many cloud providers provide an equivalent of cold storage. For example, AWS Glacier provides read-only long-term archiving of large amounts of data, with retrieval times spanning milliseconds to hours. These cloud facsimiles of cold storage provide similar levels of data security and reliability without requiring local infrastructure.
Ensure persistent data is secure
Regardless of whether you’ are an end user, building your own data solutions, or something in between, you are responsible for the safety and security of your data. You must ensure that it is secure from data loss, unintended disclosure, and data breaches.
Back up your data, and regularly test your backups. You should have backups of your data in (at least) three separate locations. If you are working with data stored in a public cloud and do not wish to implement local backups, you should mirror that data to another public cloud provider in case access is lost. You should test the integrity of your backups, and run through your full disaster recovery process periodically to make sure that it works. Disasters happen, and losing all of your data could mean the death of your business.
Even non-volatile storage has a use-by date or lifespan, so if you’re managing your own physical storage media, make sure you are rotating out your backup devices. If using optical or magnetic media, regularly replace your discs and tapes as they can become easily scratched or damaged.
Maintain an edit history for all of your data, so you know who has changed what, and when. If data is lost or interfered with, you can restore it and identify the party responsible.
Retaining stale data is wasteful, and personally identifiable information (PII) will often have limitations on how long it can be kept for. You should decide on, and implement, retention policies that state how long the different data you handle needs to be kept for. Ensure that your teams know what data is important and is intended to be kept so that it is not accidentally deleted or modified.
If your data contains sensitive information, ensure that measures such as access control and PII masking are implemented to protect it. Consider the security implications of persisting sensitive data, and how and where it is persisted—to comply with privacy laws and data governance policies, you may not be able to store PII on offshore cloud hosts, and you may be required to update or destroy all copies of a user's personal data within a certain time period or at their request.
Data persistence, persistent data, and customer data platforms
Customer data platforms (CDPs) take customer data from multiple sources and process it into a consistent format for analysis and storage, while identifying PII to enable the responsible and reliable handling of customer information. Much of this data will be first-party and appropriate for long-term use, so must be stored in a persistent manner that ensures availability and integrity.
When choosing a CDP, ensure that it provides the tools to format your data consistently with no loss of meaning, ready for long-term storage and use. Most CDPs will provide multiple persistent storage options so that you can choose the one that is best for your requirements and budget.
With long-term insights from your persisted first-party data, your analytics teams can build the audience profiles that allow you to target your products and marketing to your most valuable, attentive customers.
RudderStack is a Warehouse-Native CDP that provides flexible and secure, end-to-end customer data management. Start your free trial today.
Further reading
In this article we explained persistent data and the terminology surrounding it. There are security and compliance considerations that should be made when persisting potentially sensitive customer information, which we cover in the following articles:
- What is a Customer Data Platform?
- What are the Benefits of a Data Warehouse?
- Managing Data Retention
- Data Warehouses versus Databases