Machine learning vs deep learning
Machine learning and deep learning, two buzzwords frequently encountered in the sphere of artificial intelligence (AI), are often used interchangeably. Both concepts share commonalities and are subsets of artificial intelligence, but they each have unique attributes, techniques, and use cases.
Machine learning (ML) is a subset of artificial intelligence that allows systems to learn and improve from data without explicit programming. The process involves feeding data into a model – a mathematical algorithm that predicts outputs based on inputs. A learning algorithm is used to train this model, establishing the relationship between inputs and outputs. Once trained, the model can predict outputs from unseen inputs. Unseen inputs are simply inputs that were not a part of the training dataset.There are different types of Machine Learning methods that can be based on learning techniques which are broadly classified as supervised learning (using input and output data to learn the mapping function between them), unsupervised learning (only using input data), and reinforcement learning (learning to perform actions based on rewards and punishments). Key aspects of machine learning also include feature selection, data preprocessing, and understanding concepts like bias/variance trade-off, overfitting, and underfitting.
Deep learning, on the other hand, is a more complex and sophisticated subset of machine learning. It employs artificial neural networks – modeled on the human brain – to simulate human-like decision-making and learning abilities. In traditional machine learning, features are manually extracted from the data to feed into the model. However, deep learning algorithms automatically learn what features are important for a given task directly from raw data. This process is often called feature learning. It makes deep learning particularly effective for tasks where manual feature engineering would be hard, like image and speech recognition.
This article will guide you through an in-depth understanding of deep learning – its primary attributes, uses, and operational mechanisms. We will then delve into the key differences between machine learning and deep learning, outlining the contrasts in their functionalities, applications, and underlying mechanisms.
Whether you're a beginner who’s new to data science or an experienced professional in the field, the information presented will shed light on the distinct realms of machine learning and deep learning within the broader landscape of artificial intelligence.
If you’d like to get a better handle on machine learning first, check out What is Machine Learning. Now, let’s dive into deep learning.
What is deep learning?

A visualization of the relationship between Deep Learning, Machine Learning, and Artificial Intelligence | Source: Wikipedia
Deep learning is a subfield of ML, which is itself a subfield of AI. Deep learning is set apart by its use of neural networks with multiple layers to perform ML. Deep learning models are designed to automatically learn to represent data by training on a large number of examples and relying primarily on neural networks.
Machine learning is a broad umbrella that includes a variety of algorithms that learn to perform tasks by being trained on a dataset. These tasks may range from simple tasks like regression and classification to more complex tasks like image recognition and natural language processing. ML algorithms learn from the data, parse the information, and then apply the acquired knowledge to make informed decisions or predictions. Traditional ML typically requires feature engineering – where a human in the loop selects relevant features (attributes) from the data and feeds these to the learning algorithm as input.
Deep learning aims to automate this manual feature engineering process. Neural networks allow deep learning algorithms to learn increasingly complex hierarchical representations of data automatically, meaning deep learning models don't require explicit programming or human intervention to make decisions. Instead, they refine their performance through repetition and continuous learning, adjusting their internal parameters based on the data they are processing.
Deep learning algorithms require substantial datasets (big data) for training because of their innate complexity and the high level of abstraction they can achieve. The algorithms are also most powerful with larger, more diverse datasets because these allow for more detailed and comprehensive learning, meaning the models can achieve higher levels of accuracy and efficiency.While the goal of deep learning is to automate the process of feature extraction and representation learning, human involvement remains essential. Humans must participate in various aspects of data preparation, model architecture, tuning, and evaluation to ensure effective and responsible use of deep learning in real-world applications.
Neural networks: The foundation of deep learning
Deep learning relies on a computing structure – inspired by the networks of neurons (also called nodes) found in the human brain – known as an artificial neural network. While based on the human brain, these models do not exactly replicate its complexity.
These neural networks layer algorithms and computing units in a non-linear architecture comprised of an input layer, one or more intermediary layers (called hidden layers), and an output layer. Data in a deep learning system travels through a web of these interconnected algorithms. Each node in a layer takes in input, performs computations on it, and passes the output to the nodes in the next layer.
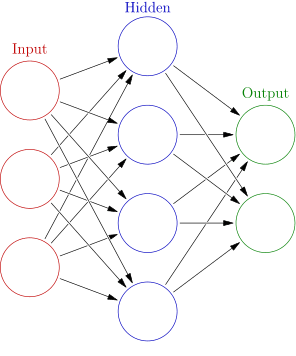
Artificial Neural Network Architecture | Source: Wikipedia
During training, the model automatically adjusts the mathematical operations performed within each node such that the final output of the model reflects the desired outcome as accurately as possible.
This unique non-linear data processing allows deep learning models to handle a broad range of tasks, including those requiring the interpretation of complex, high-dimensional, and unstructured data such as images, sound, and text.
Real-world deep learning applications
Deep learning's ability to handle large datasets and high-dimensional data has made it indispensable in various real-world applications. Here are some key examples:
Virtual assistants
Virtual assistants like Amazon's Alexa, Apple's Siri, or Google Assistant are excellent everyday examples of deep learning applications. These virtual assistants employ deep learning in their natural language processing (NLP) capabilities. They recognize and understand spoken language, respond intelligibly, and even adapt to individual speech patterns and accents over time, all due to the advanced capabilities of deep learning models.
Facial recognition
Facial recognition systems use deep learning to identify or verify a person's identity. These systems employ convolutional neural networks (CNNs), a type of deep learning model that is particularly effective at processing images. Deep learning algorithms can process and learn from a massive number of facial features and examples, allowing these systems to recognize individual faces with remarkable accuracy.
Chatbots
ChatGPT and Bard AI are two well-known chatbots that utilize Deep Learning. The chatbots are built on top of large language models (LLMs) which are trained and developed using deep learning. The models are pretrained on massive sets of text data to learn the patterns of natural human language which enables them to understand and respond to all types of queries. The deep learning architecture allows the applications to understand context, semantics, and even nuances in human language, driving sophisticated interactions between chatbots and users.
Driverless vehicles
Deep learning also plays an integral role in enabling the vision systems of autonomous vehicles. Technologies like Tesla's Autopilot leverage deep learning to recognize and interpret a vast array of objects on the road, including traffic lights, pedestrians, and other vehicles. Because they’ve been trained on millions of images and real-world scenarios, these deep-learning models enable accurate and instantaneous autonomous driving decisions.
In each of these applications, deep learning models provide the ability to learn from large volumes of data, making sense of complex patterns and nuances that would be difficult, if not impossible, for traditional machine learning models to handle. It’s this ability to learn and improve with minimal human intervention that makes deep learning a powerful tool for many use cases.
The difference between machine learning and deep learning
While deep learning is a subset of machine learning, it’s important to know the key differences between the two. At a high level, deep learning separates itself from machine learning by its use of neural networks to automatically learn hierarchical relationships instead of relying on the manual feature engineering required for ML. Next, we’ll break this down in more detail.
Human intervention
In traditional machine learning models, a considerable amount of human intervention is required for feature extraction and feature engineering, that is, deciding what aspects of the data the model should focus on to make accurate predictions.
Deep learning, though more complex to set up initially, automatically learns which features to extract from raw data, minimizing the need for human intervention in the long run. It’s particularly beneficial when dealing with high-dimensional, unstructured data like images or speech, where manual feature extraction is difficult.
Hardware
Machine learning programs are typically less resource-intensive and can run on conventional computers. Deep learning models require more computational power due to the complexity of artificial neural networks and the large volumes of data they process. High-end GPUs (Graphical Processing Units) are commonly used to train deep learning models, thanks to their ability to perform parallel processing, which is necessary for the numerous computations involved in deep learning.
Time
Machine learning programs are generally much faster to stand up because they involve simpler, more direct algorithms. However, training and optimization for these models can take considerable time depending on the complexity of the problem and the size of the dataset.
Deep learning, on the other hand, requires a substantial amount of time for initial setup and training, especially when dealing with large datasets. But once a deep learning model is trained, it can process new data and generate results faster because of its automated feature extraction and the ability to process data in batches.
Approach
Machine learning typically works with structured data and employs a variety of algorithms, such as decision trees or linear regression, to solve problems. It primarily relies on explicit programming and rule-based decision-making.
Deep learning uses artificial neural networks and can effectively handle both structured and large volumes of unstructured data. Its approach to problem-solving is more akin to human intelligence, as it can learn to recognize patterns and derive insights from raw data.
Uses
Machine learning has broad applications and is used in many everyday situations. It powers functionalities such as email spam filters, recommendation systems like those on Netflix and Amazon, and customer relationship management systems.
Deep learning, while also having diverse applications, is typically reserved for more complex and autonomous systems that require high-level pattern recognition and decision-making. This includes advanced applications such as large language model chatbots similar to ChatGPT, self-driving cars, voice-controlled virtual assistants, and advanced image and speech recognition systems.
While both machine learning and deep learning are subsets of artificial intelligence, they differ significantly in their requirements, complexity, approach, and applications. Understanding these differences is key to choosing the appropriate technology for different tasks and challenges.
Why use deep learning?
While traditional machine learning has brought significant advancements in various fields, there are certain situations where deep learning becomes a more attractive choice. Here's why one might prefer deep learning as their AI method of choice:
Handling complex situations
Deep learning excels in situations that require high-level feature extraction and decision-making. Tasks that involve understanding the context, such as sentiment analysis in text, object recognition in images, or speech recognition and generation, are often better handled by deep learning. Its ability to learn from unstructured data makes it especially valuable for these complex tasks.
Processing large datasets
The strength of deep learning grows with the amount of data it can learn from. Unlike traditional machine learning models that plateau after a certain amount of training data, deep learning models continue to improve their performance as they are fed more data. This makes them a better choice for scenarios where large datasets are involved.
Working with unstructured data
Deep learning algorithms are generally better suited to efficiently handle unstructured data, such as text, images, and audio because of their ability to automatically learn patterns and hierarchical representations. Traditional machine learning models are most efficient when using structured data with well-defined features in a tabular format.
Improved accuracy
Deep learning algorithms can reach higher levels of accuracy than most machine learning algorithms, particularly when dealing with large volumes of data, because of their ability to learn, represent, and model complex patterns in multi-dimensional data.
Automation
Deep learning models, unlike most machine learning models, can learn and improve independently. They require less manual tuning and feature engineering, making them more suitable for applications with massive datasets that require a high degree of automation and adaptability.
Conclusion: Machine learning vs deep learning
By now, you have a strong understanding of the distinction between machine learning and deep learning. On a practical level, you now know what situations call for which approach. When considering whether to use ML or deep learning, choose traditional machine learning when you have structured data, limited data size, interpretable models, and handcrafted features. Opt for deep learning when dealing with unstructured data, large datasets, complex feature engineering, and when you require state-of-the-art performance in pattern recognition tasks.