A top-level guide to data lakes
A top-level guide to data lakes
Modern organizations need a lot of data (i.e big data). Previously, this data used to only come from a few data sources, now it comes from virtually everywhere. Some of it comes as structured data — in predefined formats and fields, like phone numbers, dates, time stamps or sql tables. But, increasingly, much of it comes as unstructured data, in undefined formats and fields — like images, audio files, or documents.
While storing and analyzing big data is critical, it’s easy to get overwhelmed. In the past, the default place to store your data was a data warehouse, but over the past decade, a new data storage option has emerged: data lakes.
In this article, we’ll cover everything you need to know about data lakes. You’ll learn:
- What is a data lake?
- How is a data lake different from a data warehouse?
- Benefits of a data lake
- Best practices for using data lakes
What is a data lake?
Data lakes are an open-ended form of cloud storage that allows organizations to easily collect and store data from various data sources in different formats (both structured and unstructured data). Instead of processing data as it comes through, it’s stored and can be processed as needed. Storing data this way is efficient, simple, and cost-effective.
The founder of Pentaho, James Dixon, coined the term “data lake“ in 2010. He was working at Hadoop at the time and offered the following analogy: “...the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
Many data scientists or data engineers in most organizations use the data lake as the first point of landing for all raw data — like a staging area. Then when a use case (like analysis, reporting, or machine learning) and schema have been defined, significant data is cleaned up and moved to the data warehouse. There it’s easy to find and ready to use.
How a data lake differs from a data warehouse
While data lakes can store various types of data (structured, semi-structured, and unstructured data), a data warehouse only stores structured or semi-structured data. The format (schema) in which data can be stored is predefined before storage. This creates a lot of upfront work and limits what types of data can be stored. Compared to a data lake that ingests data from different data sources in different formats, a data warehouse needs all incoming data to be cleaned up or processed into a consistent format before storage.
You can think of data lakes and warehouses as complementary rather than competing tools. Since the introduction of the data lake, many organizations have adopted data lakes in addition to data warehouses.
Over the past few years, more and more platforms have been using data lakes. But as this approach has risen in popularity in recent years, it’s still often misunderstood and sometimes even confused with data warehouses. Make no mistake: These are two totally different tools for data storage, each with unique advantages and challenges.
Data lake architecture
One of the ways data lakes stand out is that they forego a hierarchical folder system for flat architecture.It also uses object storage to store data. It is schema-less write and schema-based read. This aids in the development of up-to-date patterns from data in order to grasp applicable intelligent insights without relying on the data.So instead of a data warehouse that sorts data into neat categories as it’s collected, data lakes store data in its native format. Where a data warehouse is more of a constructed space with a strictly categorized system for storing, a data lake has a nature-inspired approach — hence the term.A typical data lake architecture has 5 layers: ingestion, distillation, processing, insights and operations layer.
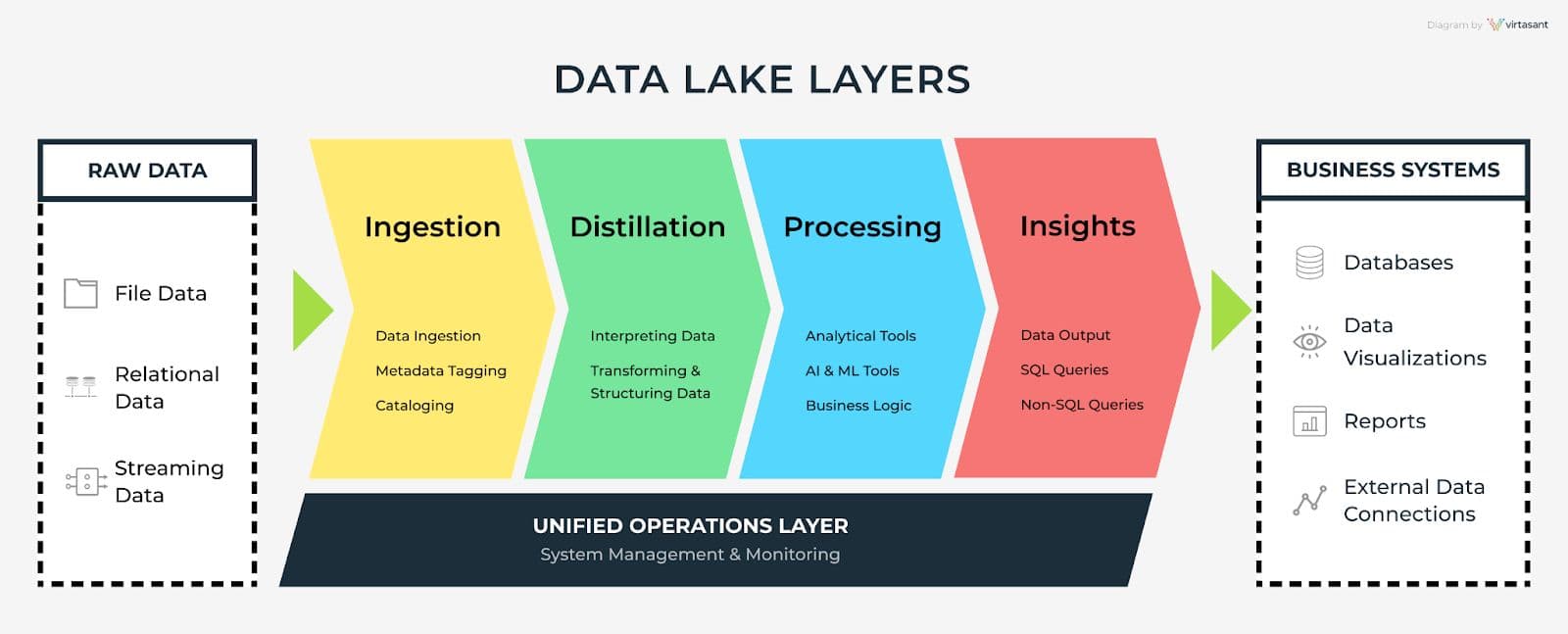
Data Lake Layers
- The ingestion layer ingests data from various data sources.
- The distillation layer converts the data ingested and stored by the distillation layer into structured data when need for further analysis arises.
- The processing layer runs queries and analysis on the structured data generated by the distillation layer to generate insights.
- The insights layer is the output interface layer. Here SQL or non-SQL queries are used to request and output data in reports or dashboards.
- The operations layer takes care of system management and monitoring.
The benefits of data lakes
Data lakes are a useful time-saving intermediary system that works in conjunction with a more traditional data warehouse approach. Data lakes are low-cost when compared to data warehouses. They’re a cost-effective storage option for companies with petabytes of historical data.
Organizations that use data lakes preserve data in its unaltered or raw form for future analysis. Raw data is held until it’s needed, unlike a data warehouse which may strip vital data attributes at the point of storage. Essentially this means you don’t have to know exactly how you want to use the data before you store it in a data lake. Organizations that use data lakes have more flexibility later on.
Data lakes are also valuable because of their scalability — when you need more storage capacity, it’s easy for a data lake to scale. Without all the structure and upfront work data warehouses require, data lakes can scale fast. This makes them attractive options for growing organizations and data science teams.
Best practices for data lakes
Since data lakes accept data in any form, it’s very easy for the data quality to become unmanageable. But, if you follow these practices, you’ll be able to prevent common issues.
First, prioritize data quality. Data lakes don’t do any data processing before storage. While this enables speed and flexibility, it becomes an issue when the quality of the data you’ve collected is too low to use. As a data scientist or data engineer, you can prevent this altogether by setting your data quality standards from the beginning. It takes a little planning and affects what data you accept, but it will prevent headaches later.
Next, it’s important to curate data in the data lake to prevent it from turning into a swamp. What’s a data swamp you ask? A data swamp is data that isn’t secured or cataloged. Without any organization or oversight, it’s difficult and time-consuming to use. Vet your data as it comes through, and catalog as needed.
Finally, store data according to defined data governance goals. Though one of the benefits of a data lake is that it’s flexible, the lack of structure can work against you if you don’t define goals early on. Data lakes give you the option to sort data later on, but you’ll need to do some sorting eventually. Make sure you have some idea of what you want to get out of your data lake.
To create a sustainable data lake you have to think ahead. Working smarter now can save you from having to work harder later.
RudderStack can help implement your data lake strategy
Because we’ve seen these issues appear time and time again with organizations hoping to optimize their data management with a data lake, we’re proud to announce that we’re launching data lake support with Delta Lake as a destination in addition to data lakes on Amazon S3, Microsoft Azure, and Google Cloud Storage. This service integrates the simplicity and flexibility of data lake storage with the organization and quality of a data warehouse. It’s the best of both worlds: The ease and flexibility of a data lake with the usability of a data warehouse.