Blog
What is the Real-Time Stack?
What is the Real-Time Stack?

Eric Dodds
Head of Product

Soumyadeb Mitra
Founder and CEO of RudderStack
21 min read
July 5, 2022

This is part IV (the final installment) of a series breaking down each phase of the Data Maturity Journey, a framework we created to help data teams architect a practical customer data stack for every phase of their company’s journey to data maturity.
As always, let’s do a quick recap of how far we’ve come in the data maturity journey. In the Starter Stack, you solved the point-to-point integration problem by implementing a unified, event-based integration layer. In the Growth Stack, your data needs became a little more sophisticated—to enable downstream teams (and management) to answer harder questions and act on all of your customer data, you needed to centralize both clickstream data and relational data to build a full picture of the customer and their journey. You solved these challenges by implementing a cloud data warehouse as the single source of truth for all customer data, then using reverse ETL pipelines to activate that data.
As the business grew, optimization required moving from historical analytics to predictive analytics, including the need to incorporate unstructured data into the analysis. To accomplish that, you implemented the ML Stack, which included a data lake (for unstructured data) and a basic machine learning tool set that could generate predictive outputs like churn scores. Finally, you put those outputs to use by sending them through your warehouse and reverse ETL pipelines, making them available as data points in downstream systems (i.e., email marketing, CRM, etc.).
For many companies, the ability to act proactively based on future predictions is game-changing, and it’s the last stop on their data maturity journey.
For some companies, though, and especially at scale, there are use cases where pushing attributes to downstream tools in batches isn’t enough, in large part because the use cases are often limited to ad-hoc email or text message blasts (or, on the advanced end of things, more intelligent marketing automation).
The holy grail of the machine learning stack for those companies is personalizing interactions with every customer and, where possible, customizing their experience in real-time. At RudderStack we often call real-time personalization the “last frontier” of using customer data.
This post will be a bit different than the last three posts because, as crazy as this sounds, very few companies have actually built an effective, end-to-end real-time personalization engine. Most of the popular success stories come from companies with thousand-plus person engineering teams and unlimited resources to build custom tooling.
That technology has begun to trickle down, though, and today it’s possible for many more companies to build powerful real-time personalization use cases by using the right tools.
Still, there’s a high level of complexity on the software engineering side in order to modify user experiences in apps and websites in real time—what we call the “last mile” of delivery. Delivering the last mile also varies significantly for every company due to their proprietary code and software infrastructure.
To that end, this post will be less prescriptive and instead explore suggested architectures for use cases where the output of ML systems can be leveraged in real time. Our goal is to help data engineers think creatively about how they could enable real-time use cases in partnership with other teams.
What is the Real-Time Stack?
The ML Stack we outlined in the previous post allowed us to provide inputs to a model and use the outputs. Because timeliness wasn’t a primary concern, a batch job on some schedule was sufficient. The goal was to have the ability to take action proactively based on predictive user traits (i.e., likely_to_churn). Also, the destinations for the outputs were cloud SaaS tools used by downstream teams like sales, marketing and customer success, which made sending updated user traits easy (because we already had the integration infrastructure set up).
The Real-Time Stack delivers on the same basic outcome of modifying the user journey but takes it two steps further:
- First, this stack enables use cases where delivering personalized, real-time experiences is critical
- Second, this stack delivers results directly to the user experience in the website or app, literally modifying and customizing what they see
What do we mean by real-time?
Much like the term machine learning, real-time is an often mis-understood and abused term in the world of data. For some companies, going from multi-day jobs to 1-hour jobs for key reporting can feel like a massive jump to “real-time” data. For other companies, real-time means real-time in the literal sense, where something is modified on a sub-second timeline (often measured in milliseconds).
In this post, we will consider use cases where the user experiences personalization in real-time, but, as you might expect, that experience can happen in different ways depending on the user's actions.
In general, real-time personalization comes in two flavors:
Next behavior personalization
This use case delivers personalized results when the user takes some future action. TV streaming services are a great example: you don’t know exactly when a user will log in next, but when they do, you want to serve them the most relevant content possible based on what they’ve recently consumed.
This means that the user experience is modified in real time from ML outputs that are accessed in real time. However, the entire data loop doesn’t have to run in real time because there is some amount of time between user actions. Said another way, this is real-time personalization for the user, but not necessarily real-time ML.
In-session (or next-page) personalization
This use case is the bleeding edge of real-time personalization. It involves collecting inputs from a user in real time, routing them through an ML model that runs in real time, and using the model’s outputs to customize that particular user’s experience while it is happening. This requires the data loop itself to run in real time (or, practically, on a sub-second/millisecond timeline). One good example of this is real-time personalized search results. When a user searches your site or app using certain terms, you want to provide recommended results that they are more likely to purchase. Those ML-derived recommendations need to be calculated and delivered when the search is executed before the results load.
Below we’ll cover examples of each use case, but first, let’s look at how we’ll augment the ML Stack to make the Real-Time Stack.
So, what is the Real-Time Stack?
The Real-Time Stack introduces a few new components that enable real-time delivery of outputs back into apps and websites.
Remember, in this phase data tooling is one part of the equation. The last mile of delivering a personalized experience actually occurs in your software–be that a website or app–so achieving these use cases requires collaboration across data engineering, data science, and product engineering teams.
One significant implication of this architecture is that your product engineers have to write custom code in your software that accesses the outputs from your ML models to incorporate them into the user experience. Building this last mile has gotten easier, but it varies depending on the company’s stack. This is why we are focusing on the data flows in this post.
The Real-Time Stack addresses two fundamental challenges to delivering real-time experiences:
- Data freshness: real-time personalization requires inputs that are happening right now, meaning you can’t wait for compute jobs to run or tables to be materialized, then delivered
- Latency: how do you activate the output of your ML model while your customer is using your app?
The Real-Time Stack solves these problems by:
- Introducing an online, in-memory store that makes outputs available in real-time
- Introducing more robust machine learning infrastructure to enable modeling with real-time inputs
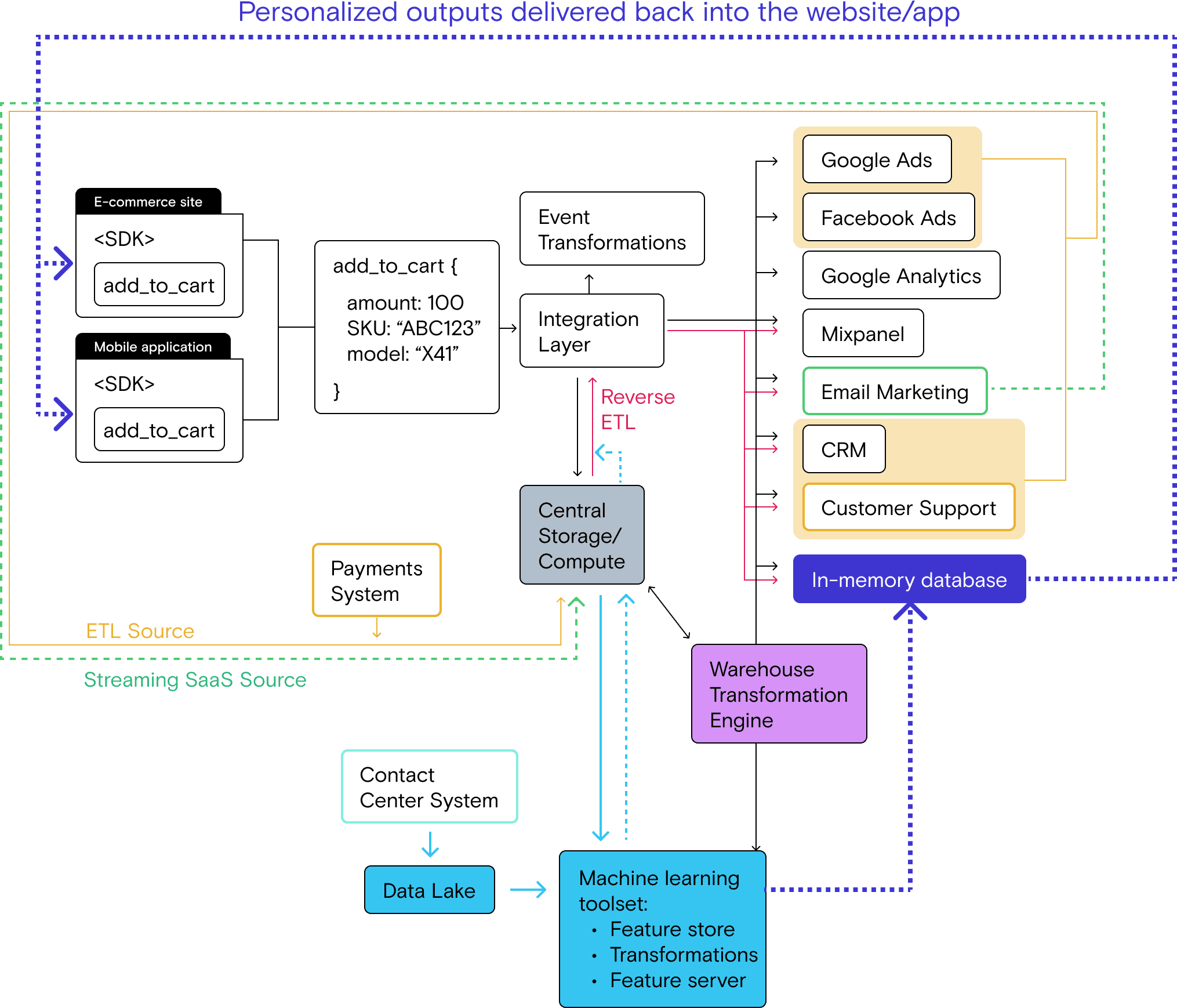
As you can see in the high-level architecture below, the Real-Time Stack looks similar to the ML stack, with the addition of the in-memory data store. What’s not represented here is the work that goes into the dashed purple line connecting ML outputs with the app and website themselves–the last mile delivery.
Also note the additional machine learning toolset: a feature store, transformation functionality, and a feature server that can serve outputs in real time. The ML box in the diagram intentionally over-simplifies the ML setup because we aren’t digging into the specifics of ML ops systems here.
When do you need to implement the Real-Time Stack?
We’ll be clear at the outset: some companies will never need to build the infrastructure required to deliver experiences in real time. So before you get started, remember that avoiding the temptation to over-architect your stack always pays dividends. That said, for some companies the Real-Time Stack is imperative for driving additional growth. Let’s take a look at practical indicators that you might need to implement this infrastructure.
Symptoms that indicate you need the Real-Time Stack
Similar to the ML Stack, the need to optimize key points in the customer journey is the trigger for exploring real-time use cases. That said, implementing architectures like this one make sense only when you’ve exhausted the utility of other kinds of personalization efforts. Here are a few example symptoms:
- Relatively small percentage gains (i.e. >1%) in key metrics like retention or churn mean significant impact on the bottom line of the business
- Downstream teams have hit the ceiling of personalization features available via batch delivery of outputs activated through their SaaS tools–conversion rates are as good as they will get without introducing the element of timeliness and modifying the app/website experience
- You work in a business that is particularly sensitive to timeliness such as delivery, media, eCommerce, or IOT
What your company or team might look like
Up to this point in the Data Maturity Journey, we were careful to make the point that each stack might be used by a company of any size. However, the Real-Time Stack generally only makes sense for larger companies because of the dedicated product engineering investment required to deliver the last mile. Most often that means consumer brands with millions of monthly customers or users.
If you’re exploring the real-time stack, you likely:
- Have a mature data science practice operating in your company
- Have access to significant engineering resources
- Have implemented successful A/B testing programs at scale in your website or app
Returning to our example company
Let’s return to the example company we’ve been following to see how they’re approaching the need for a Real-Time Stack:
You’re now a large eCommerce company.
Your website, mobile and marketing teams focus on driving digital purchases through your site and app, but you also have a sales team supporting wholesale buyers. Many of the sales team’s prospects are long-time repeat digital purchasers who would benefit from opening an account.
After launching a subscription program 6 months ago, your teams noticed a concerning trend in cancellations. By leveraging the ML Stack, you were able to flag customers who were likely to cancel, enabling the marketing team to reduce churn by emailing offers proactively.
Excited by the success of using predictive analytics to reduce churn, the marketing team now wants to explore delivering real-time recommendations to various users as they interact with the site and app. A sharp data analyst does an analysis showing that a 1% increase in basket size could drive $10M in revenue - a much needed boost in a highly competitive market.
Here’s the ML Stack you’re currently running, which introduced a storage layer for unstructured data and a modeling and analysis toolset, allowing the company to unlock predictive analytics.

This ML Stack is great for delivering model outputs in batches that aren’t time-sensitive, but it can’t facilitate real-time use cases.
The data stack and the data challenges
In the previous phases of the data maturity journey, the introduction of new systems and data types created challenges that required you to implement additional tooling. In the case of the Real-Time Stack, there aren’t new systems producing net-new customer event or relational data.
The primary concern of the Real-Time Stack is the computation and delivery of ML outputs directly into your app or website in a timely fashion. At this point you aren’t mitigating pain, you’re seeking to capitalize on untapped opportunity.
In order to solve the delivery problem, there are several new components that need to be added to the stack:
- A real-time, in-memory data store: this a repository of outputs made available for consumption in real-time (most often via an API on top of the in-memory store)
- More robust machine learning tooling: in order to enable real time, our ML toolset needs to include:
- A feature store (for easy access to inputs)
- A transformations layer to make developing and working with features easier
- A feature server, which can run analyses in real time and deliver outputs to the in-memory data store
- Last mile code that can consume outputs in real time: this is code in your website or app that can access the in-memory data store to pull outputs and incorporate them into the customer experience
In practice, the transformations layer and feature server often operate as a single model serving layer that takes care of both functions. We’ve opted to break the functions out in this post so readers don’t get caught up in nomenclature.
Again, we’re intentionally leaving out a significant amount of detail here. You can implement all kinds of ML tooling and last-mile code depending on your specific stack and needs. Our goal is to highlight the high-level data flows as they relate to the existing infrastructure of the Growth Stack and ML Stack.
Here’s an example of what this architecture could look like:
One thing to note about this proposed architecture is that the in-memory database is fed by multiple sources: the real-time event stream, reverse ETL pipelines, and the ML toolset. In a sense, the in-memory store takes your full view of the customer and makes it accessible to other parts of your stack in real-time.
Guide: two example data flows for the Real-Time Stack
Instead of diving into the specifics of implementation, let’s dig into the two primary data flows mentioned above to explain the different data flows required to deliver each.
Use-case 1: recommendation engine (batch computation, real-time serving)
This use case enables next behavior personalization. Going back to our example company, you want to personalize their experience on the next visit or log-in to increase the value of a user’s potential transaction. Specifically, you want to drive additional purchases by recommending products at the top of the page (ML outputs) that your customer is likely to purchase based on what you know about them, such as purchase history, purchase frequency and demographics (ML features).
In this case, the model features can be computed from historical data (vs. real-time data) and reflect likely customer preferences. The primary goal is making the outputs available to serve in real time when the user takes their next action.
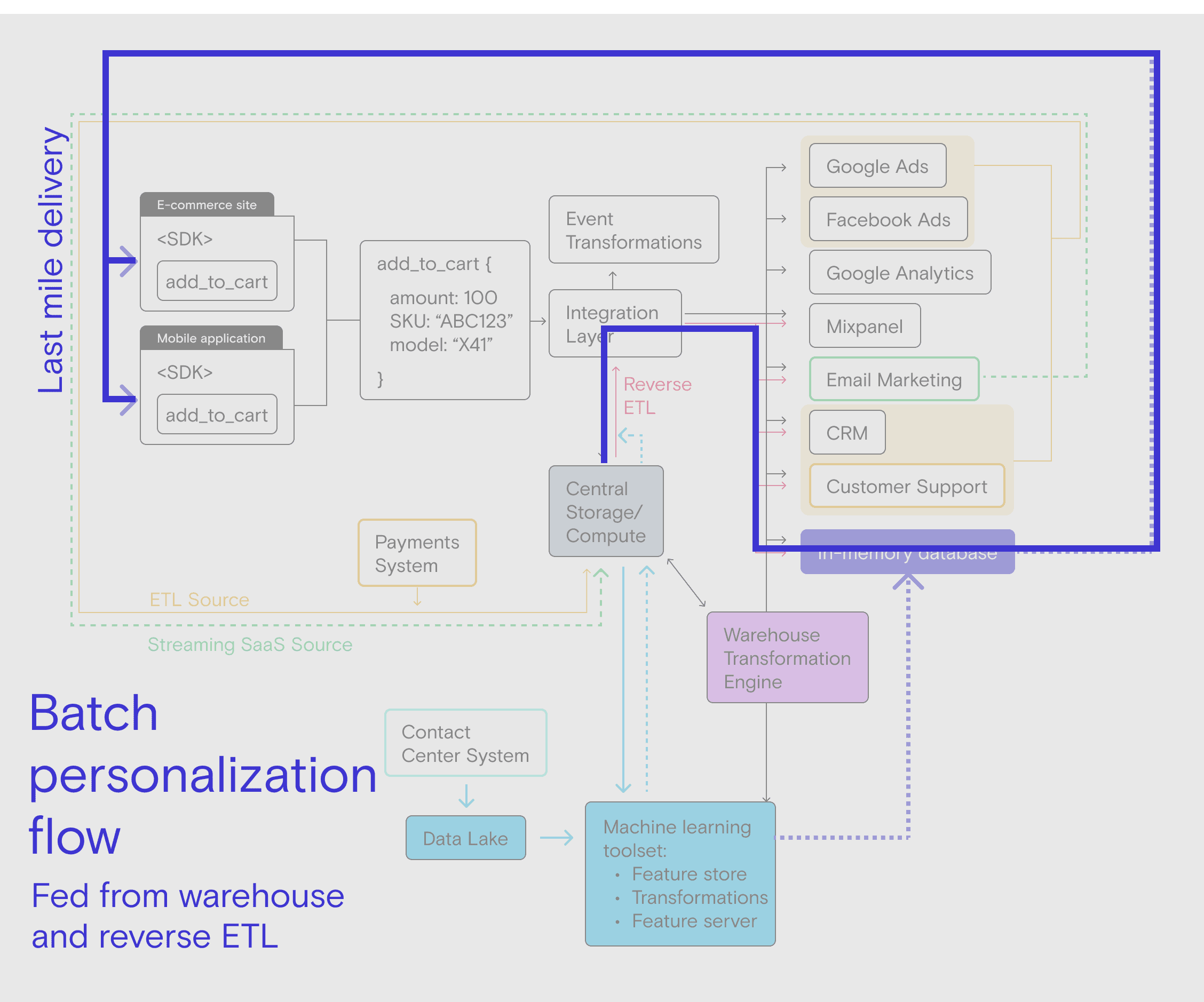
Because there is some amount of time between user actions, you have the luxury of leveraging much of your existing infrastructure to deliver an experience that is personalized in real-time for the user. Practically, this means that you’re computing outputs in batch on some schedule and pushing them to the online store to be consumed. If this sounds familiar, it is—this is the exact same flow from the ML Stack:
ML tooling → data warehouse → reverse ETL → online data store
The primary difference is that the ML outputs are made available in some kind of an online store that can be accessed when the user next visits or logs in (you experience this data flow as a user every time you log into services like Netflix). The online store is required because data warehouses and data lakes, where your batch outputs are stored, aren’t designed for real-time online lookup. Also, depending on their data types and stack architecture, some companies choose to route outputs through their data lake instead of their warehouse.
As we said above, this use case enables real-time personalization, but doesn’t require real-time ML. Just because it’s a batch flow doesn’t mean that it can’t run fast, though. We’ve seen customers run certain batch jobs like this on a 15-minute schedule for their personalization use cases.
The other thing to note about next behavior personalization is that it doesn’t require additional ML tooling. You can use the same modeling mechanisms, you just deliver the results to an online store in addition to the data warehouse. Next behavior personalization is also easier to implement in your app or website, another reason many companies start here for modifying in-app or web experiences.
Here’s what this high-level data flow looks like:
Use-case 2: in-session personalization (real-time computation, real-time serving)
There are certain use cases where even a fast cadence of batch jobs isn’t adequate, and real-time ML computation is required. Let’s look at a few examples.
Returning to our example company, let’s say we want to deliver recommendations in search results based on the terms typed by the user. In order to deliver personalized recommendations in the results, we would need to:
- Feed the search terms as inputs into the ML model
- Run the model and produce outputs
- Incorporate the outputs into the search results in the website or app
…all of this between the time the user clicks “submit” and the search results load. This is real-time personalization and real-time ML.
Another great example is fraud detection. Let’s say you are an online bank and you want to detect fraudulent activity based on the end user’s browser properties and browser behavior. This requires the ML system to make predictions based on the current live user activity and user traits and run a model on those inputs in real time.
Real-time computation may also be required where it is impossible to make batch predictions for all possible combinations of inputs. Think about a use case for showing a user similar products to the one they are viewing. Let’s say we want to tune the similar product recommendation engine not just based on the last product viewed/clicked by the user in-session, but also the user’s historical behavior. If we were to use a batch-ML system for this scenario, it would require pre-computing the output recommendations for every combination of product and user options. With a few thousand products and 10 million users, this would require tens of billions of combinations. Pre-computing predictions for that many combinations is not only infeasible, but storing the computed results would be prohibitively expensive.
A much better approach is to design an ML system that takes the user’s historical profile and their live behavior as input in real-time and returns relevant products for that specific combination.
One small step for personalization, one giant step in infrastructure.
While the jump from batch ML to real-time ML may feel seamless to the end user, the system required to achieve in-session personalization is substantially more complex.
First, let’s look at the high-level data flow that can feed an ML system with live data. Then we’ll dig a little deeper into the additional ML system functionality required for real-time computation.
Here’s the data flow for real-time ML:
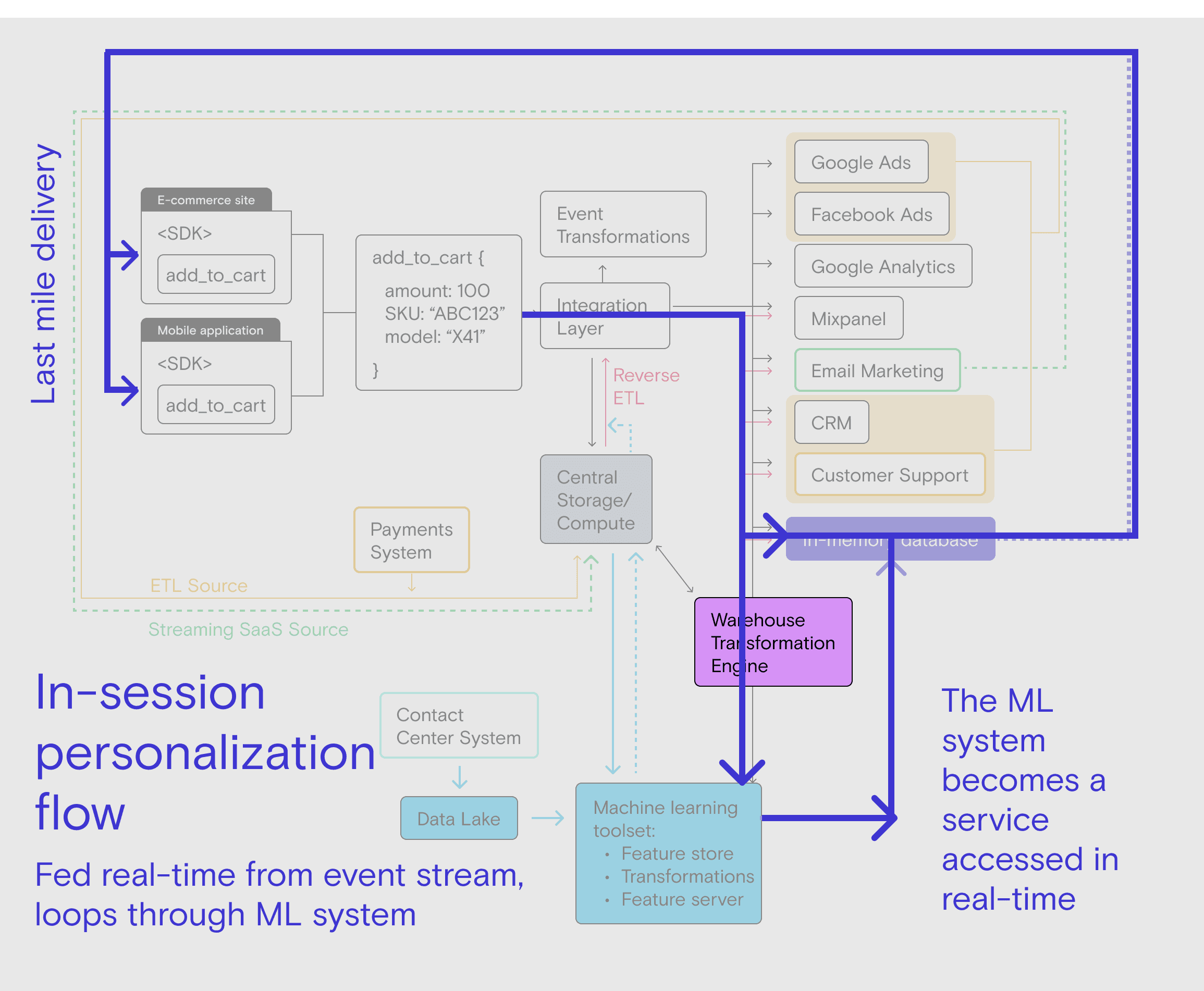
The most important thing to note about this architecture is that the ML toolset itself must become a service that can be accessed in real-time. This makes it possible for the ML system to receive real-time data and make the real-time computations required for delivering in-session personalization.
To explain this further, let’s take one step deeper into the machine learning tool set box in the diagram in the context of our “show similar product” recommendation engine.
Our example requires two data sets as inputs:
- Historical user behavior
- Live data on the products or links the user just viewed/clicked
The basic data flow for the live data piece is straightforward once the ML system is set up as a service. Real-time behavioral data is fed to the ML system from a real-time event stream. If you’ve built your stack following the data maturity journey, you already have this in place.
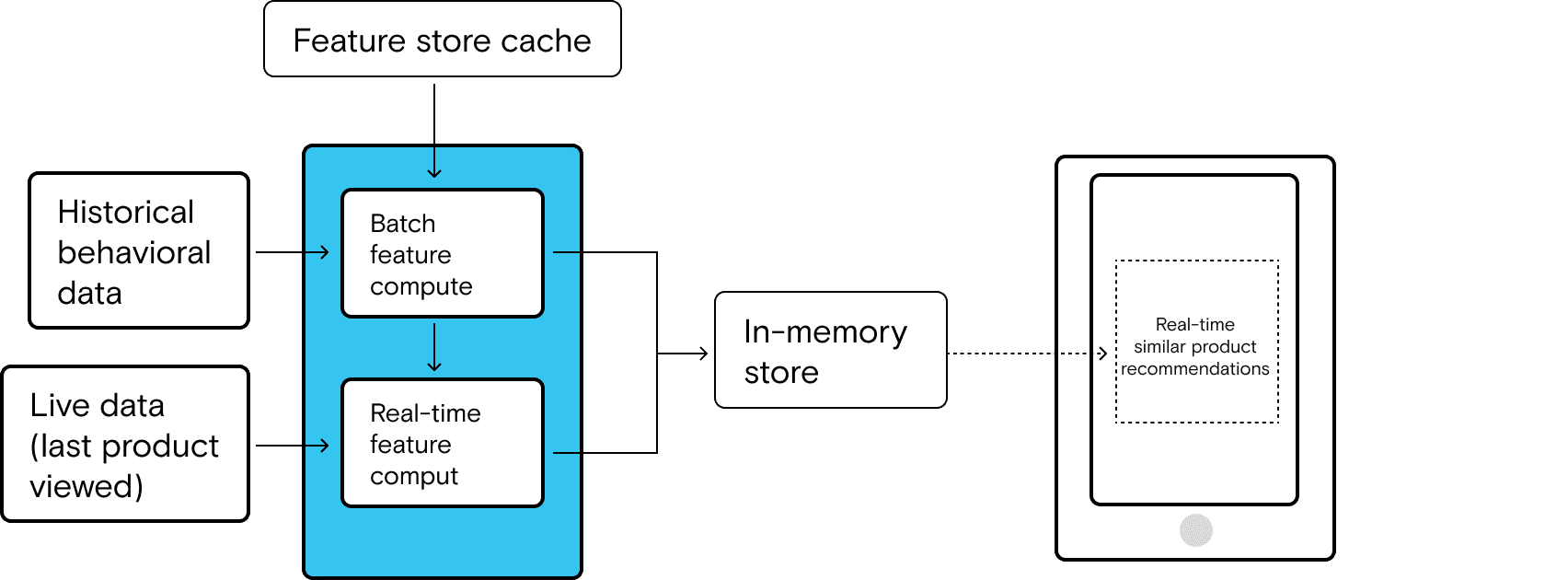
The historical data is trickier because that data has to be collected and updated on some interval, meaning that it runs as a batch job on some schedule (for example, historical behavior up through the last 6 hours). But the data also needs to be available for use by the ML system for the real-time computation.
To make the data available, the batches must be sent to an online cache that is readily accessible by the ML computation service. In the ML workflow, this is often called a feature store.
In the full flow, a user’s real-time pageviews and clicks are fed into the ML service in real time. The ML service then combines these inputs with inputs from the feature store cache in order to run the full model and deliver the outputs–all in real time. Here’s a high-level overview of what this specific piece of the architecture might look like:
Tooling and technical review
The Real-Time Stack adds three key components to the stack. One is a key piece of the puzzle no matter your stack, while the other two are highly subjective based on your specific tool set and product software infrastructure:
- An Online, in-memory data store (required to make outputs available in real time)
- An ML toolset enabling ML computation as an online service
- Software infrastructure in your app or website to access outputs in the online data store
Outcomes from implementing the Real-Time Stack
While it’s technically complex to implement, both from an ML and last-mile delivery standpoint, the Real-Time Stack delivers the infrastructure to modify any part of the digital journey in your websites and apps in real-time. Our examples focused on things like increasing basket size, but the use cases are endless. They span the spectrum from fraud detection to feature adoption and beyond.
When these projects succeed, they can directly impact the bottom line in a major way.
The data maturity journey is never over
Thanks for taking this journey with us. We hope the content has helped you cut through industry buzzwords to better understand the practical fundamentals of data stack architecture.
Remember, the data maturity journey is continual. New use cases will arise, and new tools will be adopted by downstream teams. Your data tooling itself will change, new flows will be unlocked, and occasionally tools will become outdated. Through it all, your goal as a data engineer holds steady–to build and run the most flexible, efficient stack to meet the needs of your business today while preparing for the needs of tomorrow. To infinity and beyond!
Published:
July 5, 2022
More blog posts
Explore all blog posts
Event streaming: What it is, how it works, and why you should use it
Brooks Patterson
by Brooks Patterson

From product usage to sales pipeline: Building PQLs that actually convert
Soumyadeb Mitra
by Soumyadeb Mitra

RudderStack: The essential customer data infrastructure
Danika Rockett
by Danika Rockett


Start delivering business value faster
Implement RudderStack and start driving measurable business results in less than 90 days.


