Guide to the Modern Data Stack: the Data Maturity Journey


The world is grappling with how to fully harness the customer data explosion spanning the last few decades. More data than ever before is available to companies, and with it, even more ability to handle and use that data in ways that was previously only available to an elite few. The new technology and tools that help fueled the expression, became known as the modern data stack.
Watch the video on the modern data stack
At RudderStack, we engaged with hundreds of companies across industries and sophistication levels, and we have recognized a trend. Companies across the spectrum still struggle to best apply their data to inform decision-making, build better products, and ultimately delight customers.
What is a modern data stack?
The modern data stack refers to a collection of technologies and tools used to collect, handle, process, and analyze data.
A modern data stack is designed to meet the needs of scalability, flexibility, and efficiency required by businesses to make informed decisions based on vast amounts of data.
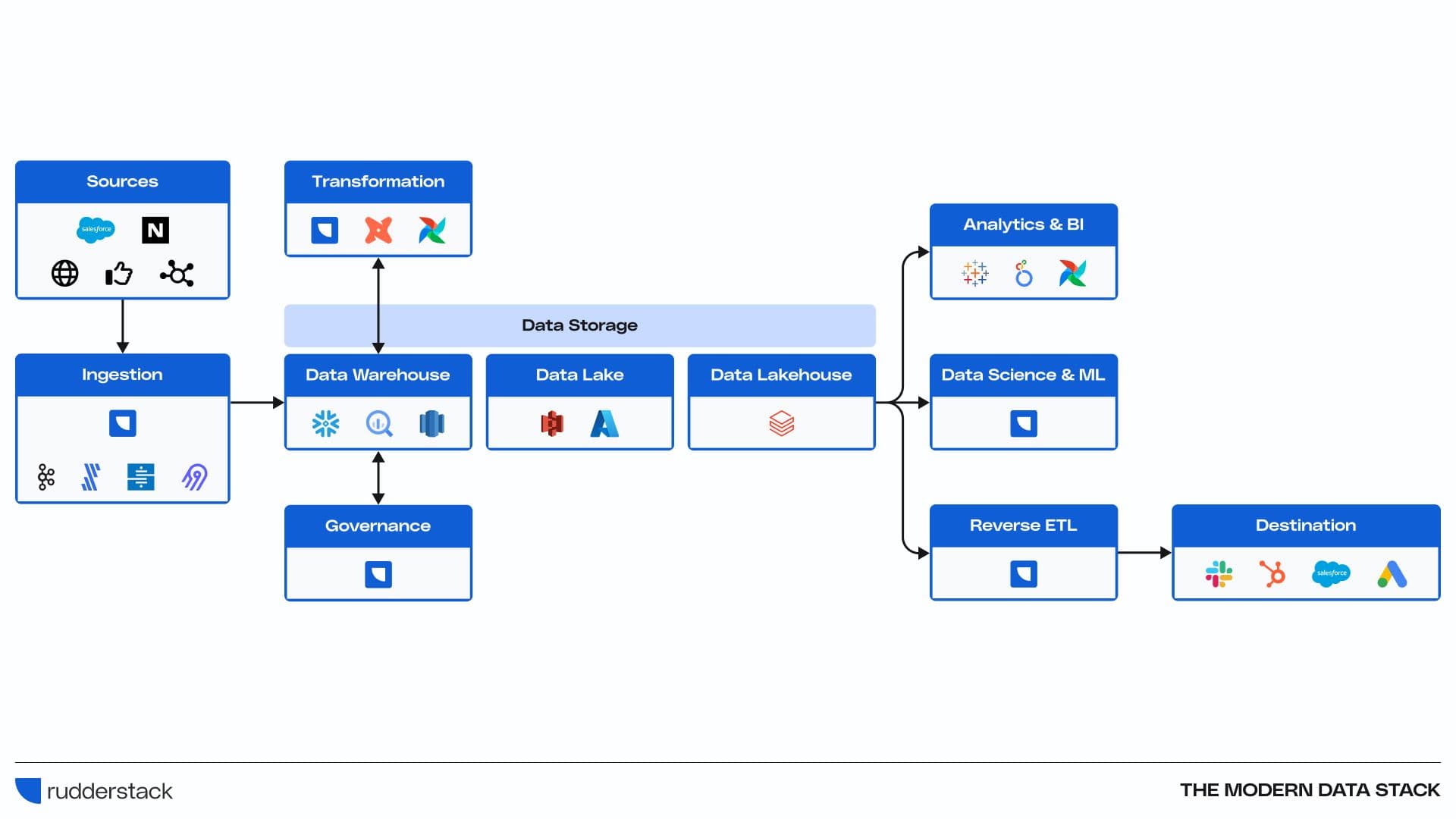
Here are some of the core components typically involved in a modern data stack:
- Data Sources: These are the origins of data, which can include internal systems like CRM (Customer Relationship Management), ERP (Enterprise Resource Planning), web analytics, as well as external data sources such as social media, third-party APIs, etc.
- Data Ingestion Tools: These tools are used to collect, import, and integrate data from various sources. RudderStack is a prime example, and serves as a robust alternative to tools like Apache Kafka, Fivetran, Stitch, and Airbyte, focusing on real-time data streaming and integration. RudderStack simplifies the consolidation of data into a central repository, ensuring that information from various channels is seamlessly unified.
- Data Storage: Once data is ingested, data must be stored effectively to facilitate analysis and access. RudderStack integrates with data lakes such as Amazon S3 and Azure Data Lake for unstructured data, as well as data warehouses like Snowflake, Google BigQuery, and Amazon Redshift for structured and semi-structured data, ensuring that data is efficiently organized and ready for use.
- Data Transformation: Data often requires transformation (cleaning, aggregating, and restructuring) before analysis. Tools like dbt (data build tool) are popular for this purpose, allowing for the transformation of data within the data warehouse.
Transformations in RudderStack serve a dual purpose. First, they act to cleanse, aggregate, and restructure data as it flows through the data pipeline. This ensures that by the time the data reaches its destination—be it a data warehouse, data lake, or operational system—it is already in an optimized format for analysis or operational use. Second, transformations enable the activation of this data by seamlessly integrating it into various business applications and systems, a core feature of Reverse ETL.
The concept of Reverse ETL—taking processed data from a data warehouse and sending it back into operational systems—is inherently built into RudderStack's approach to transformations. RudderStack allows for the customized transformation of data to fit the specific requirements of target systems, ensuring that data not only integrates seamlessly but also triggers actions, updates, and personalizations in real-time. This capability transforms static data into dynamic assets that can directly influence customer experiences, operational efficiency, and strategic decision-making. - Data Analysis and Business Intelligence (BI): For analysis and visualization, BI tools like Tableau, Looker, Power BI, and Metabase are used to create dashboards and reports that help in decision-making. RudderStack can feed processed and refined data into these tools, enabling the creation of insightful dashboards and reports that drive strategic decision-making.
- Data Science and Machine Learning: For more advanced analytics, we can stay ahead of data with predictive modeling and AI. With RudderStack for example, data teams can rapidly generate churn and lead score models on clean data, and enable their data science teams to accelerate more complex projects.
- Data Governance and Compliance: With increasing data privacy regulations, tools for data governance, data quality, cataloging, and compliance have become integral to the modern data stack.
Breaking down the modern data stack journey
In this write up, we describe the components of the modern data stack at each stage of the data maturity journey. Companies at the early stages of their data journey typically deploy a simple architecture focused on data collection and activation. On the other end of the spectrum, the most sophisticated B2C companies leverage machine learning to deliver real-time user experiences.
Here, we provide a simple framework to help you identify the right data infrastructure components for your company based on complexity of needs, level of data sophistication, maturity of existing solutions, and budget. Our framework focuses on customer data, as it's arguably the most valuable data a company possesses, and frames the data stacks along four phases:
- Starter
- Growth
- Machine Learning
- Real-Time

Naturally, there are overlaps among the phases since each organization has its own unique evolution path.
Phase 1: Starter Stack
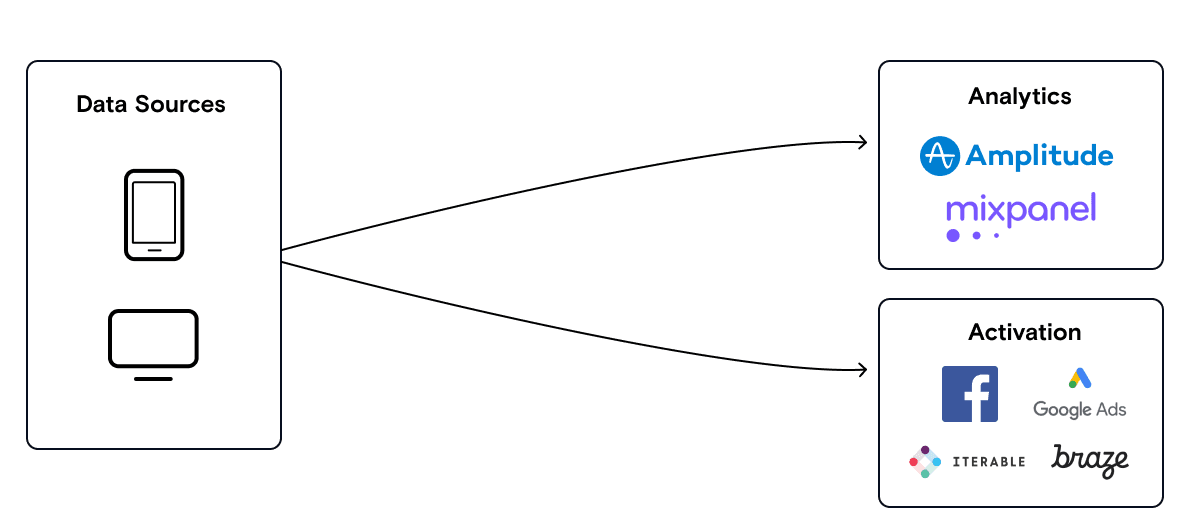
In this phase, you’re collecting data from your websites and apps and sending it to multiple downstream destinations (such as Amplitude and Braze). Integration requests are typically lodged to IT or engineering from two teams:
- Marketing: A marketer wants to send data to an analytics tool like Google Analytics or an ad network such as Facebook or send personalized emails to customers
- Product: A product manager wants to get better insights on how customers interact with particular features on their application
The ad-hoc nature of these requests for point-to-point integrations creates a strain on your engineering and IT teams. This is where one-time integrations from RudderStack or Segment significantly eliminate engineering bottlenecks.
The Starter stack is right for companies at the beginning of their data journey. That is, companies with simple data use cases and limited budgets. Startups that are less than 2 years old or prior to Series B often fall into this category. The rapid adoption of this stack over the last decade has fueled the success of providers that pipe data into SaaS tools (e.g., Segment), SaaS tools that consume this data (e.g., Amplitude and Braze), and tools that provide analytics (e.g., Amplitude and Mixpanel).
Common starter stack challenges:
- Different teams want data delivered to their preferred applications
- Brittle data integrations create drain on the engineering team
- Multiple SDKs slow website and app performance
Phase 2: Growth Stack
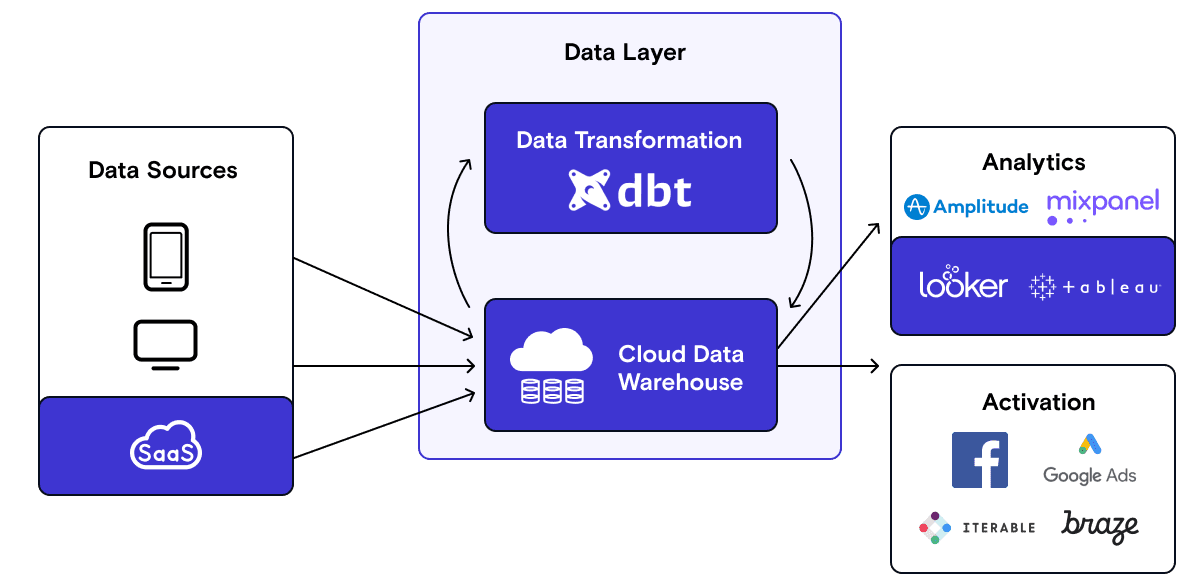
As your company grows, the proliferation of data destinations leads to data silos. You’ll probably hire Data Analysts to make sense of the data across a wide range of business functions. Out of necessity, your company invests in centralizing data into a warehouse. The warehouse soon evolves into the single source of truth for analytics. To answer complex questions, the Data Science team starts making use of transformations in the warehouse and sending the insights into downstream destinations.
In this phase, the warehouse becomes the center of your data stack. This warehouse-centric model catalyzed Snowflake’s success, the most successful cloud IPO to-date, along with the companies that facilitate the movement of data into the warehouse (e.g., Fivetran, Stitch Data and RudderStack.). The emergence of the data warehouse as a data source also sparked the creation of companies that move data from the data warehouse to downstream apps. The prominent examples here are Census, Hightouch and RudderStack.
Declining warehouse storage costs mean companies can now load data into their warehouse first and then run transformations on data (instead of summarizing the data first to reduce storage costs). This led to the rise of dbt as the industry standard for data warehouse transformations. RudderStack helps you deploy your dbt models on customer data (i.e., operationalize dbt models) and pull data from the warehouse into downstream destinations via Reverse ETL.
The Growth Stack is ideal for companies with growing data complexity and commensurate sophistication in data engineering. At this stage, the organization starts hiring data analysts. This stack is common among startups 2 to 5 years old going through a series B to pre/early IPO growth phase. GitLab is a good example of a company in this phase.
Common growth stack challenges:
- Point-to-point integrations create data silos
- Better business intelligence and more personalized customer activation requires data transformation in the warehouse
- Data transformed in the warehouse (e.g., customer cohorts) needs to be delivered to downstream destinations
Phase 3: Machine Learning Stack
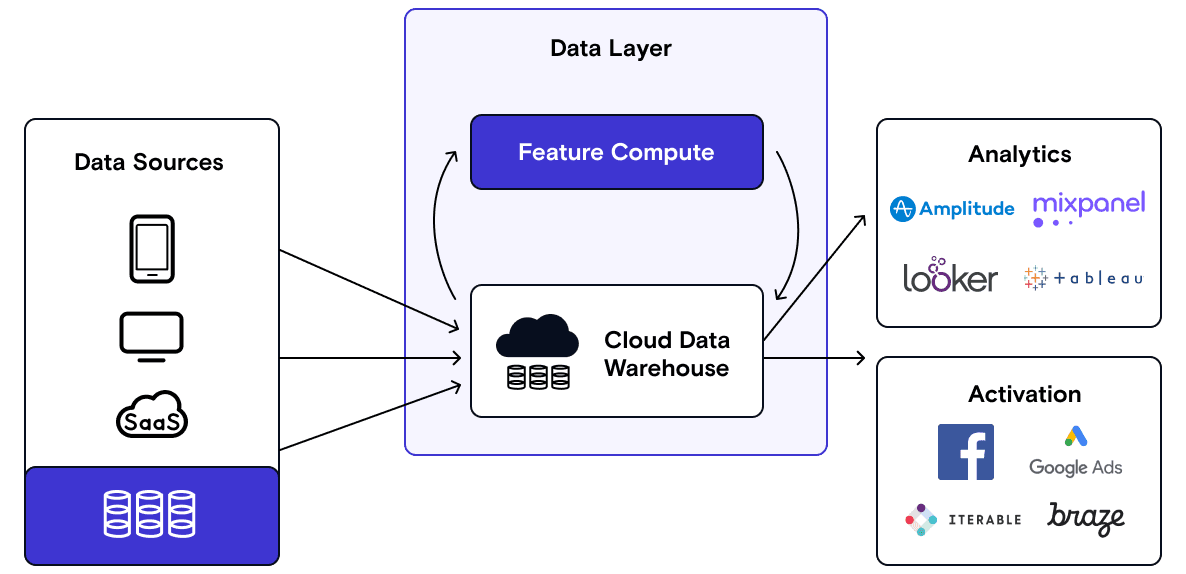
Once the warehouse fulfills your organization’s need to answer business questions and serve as a guide for historical data, the need for predictive analytics arises.
Predictive analytics allow you to predict expected user behavior based on early signals and optimize marketing activities accordingly. For example, you might want to predict which users are at risk of churn and send them an “engagement offer” email.
In this phase, we see the emergence of data lakes, such as Databricks, that are optimized for the storage of unstructured data and machine learning workloads. In addition, a wide variety of ML ops stack companies have emerged here.
In this phase, there are two typical (idealized) workflows:
Training Flow
- Batch data from the warehouse and streaming data from user applications are ingested into the data lake. Features are defined using SQL or Python
- Features values are generated on training data
- An output label (e.g., has a user churned or not) is generated
- A model is built to predict output from features
Production Flow
- Feature values are generated from input data
- The model is used to predict on the feature label
- Label is synced to some downstream destination (using Reverse ETL) to take action (e.g., send an email with a discount for customers labeled as being likely to churn
At this stage, the organization is heavily investing in data engineering resources. Also, beyond the feature tuning that is done by data scientists, machine learning engineers start playing an important role to deploy and operationalize tools such as Spark. RudderStack will soon allow you to deploy your Spark models on customer data (i.e., operationalize spark) and send it to downstream applications via Reverse ETL.
Typically, companies of meaningful scale are able to invest and utilize the value of the machine learning stack because the optimization multiplier on their large customer base is often a good reason to do so. These companies also have the resources and volume of data to make substantial improvements through use of machine learning. B2C companies often transition faster to the machine learning stack because of their scale of users. However, it is not uncommon to see a large B2B business invest heavily in the machine learning stack.
Common ML stack Challenges:
- Marketing wants to predict user behavior (e.g., likelihood to churn) for better personalization
Phase 4: Real-Time Stack
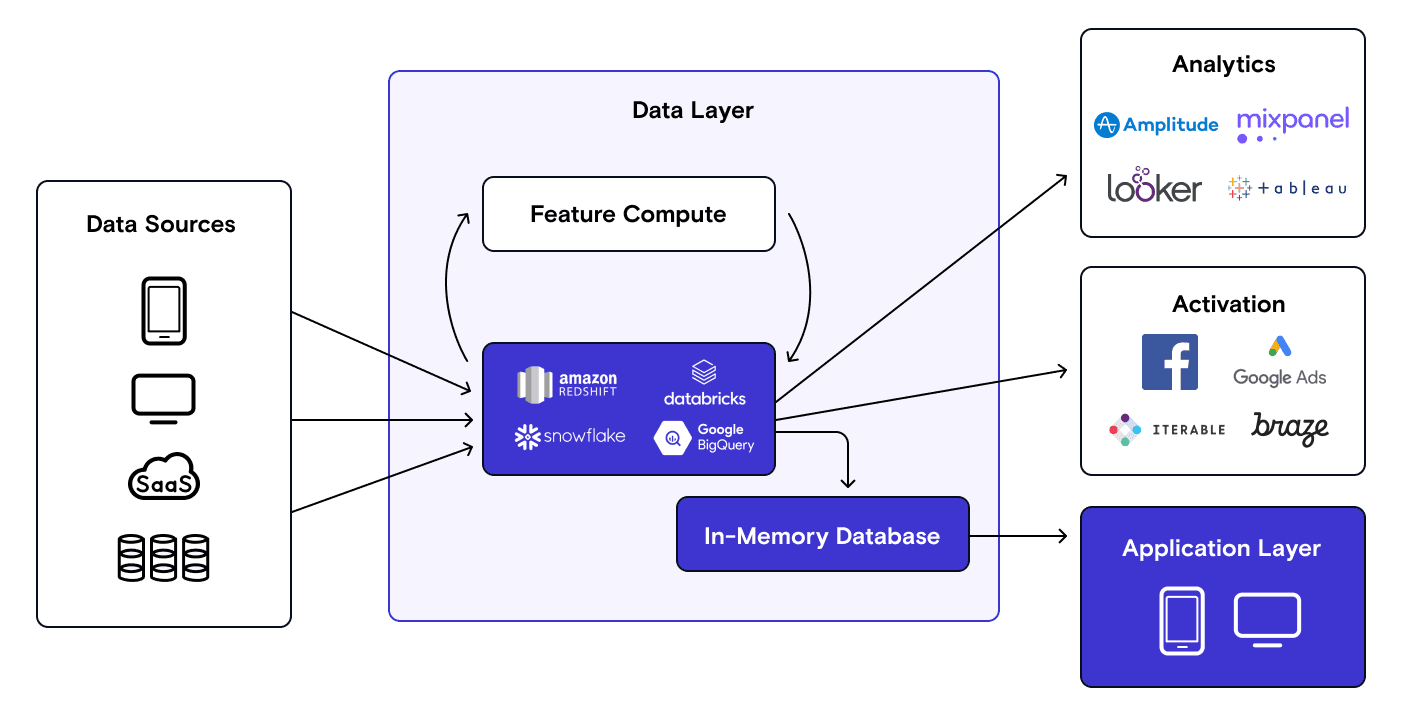
For some of the most sophisticated companies that serve millions of customers, their business models require predictive model results along with insights from the data warehouse to be delivered back into the application. This means features and query results not only need to be stored in the data warehouse, but also need to be stored in an in-memory database to power applications directly with the data.
During this phase, the data starts flowing through not only the “offline” pipeline into the data warehouse but back into application services. This is often coupled with Kafka as a streaming bus (for coordination with other services) and Redis as an “online” in-memory store (to serve the application). RudderStack is able to sync this data into an in-memory store such as Redis to power your application.
An illustrative use-case is an e-commerce application that uses browsing history to compute and serve product recommendations directly in the app. Doordash, Stripe, and Uber have invested heavily to make offline and online predictions on user data and then serve them back into the application to customize the user experience. The important thing to note here is that real-time is less about real-time computation of insight – it’s about serving insights back into the application in real-time. We acknowledge that real-time might be overloaded here to a discerning engineer.
Common real-time stack challenges:
- Marketing wants to deliver personalized experiences in real-time to the application layer (e.g., in-app product recommendations)
At this point, you are collecting the data, analyzing it and using both historical and predictive pipeline to power both your marketing, analytics and directly your application. Congrats! It is time for a cold beverage ;)
RudderStack is built for the modern data stack
Schedule a demo with our team today to learn how RudderStack can help you build your data foundation to turn your customer data into competitive advantage.
Published:
June 13, 2022

Event streaming: What it is, how it works, and why you should use it
Event streaming allows businesses to efficiently collect and process large amounts of data in real time. It is a technique that captures and processes data as it is generated, enabling businesses to analyze data in real time


How Masterworks built a donor intelligence engine with RudderStack
Understanding donor behavior is critical to effective nonprofit fundraising. As digital channels transform how people give, organizations face the challenge of connecting online versus offline giving.


How long does it take you to see a customer event? If it's over five seconds, you're missing out
Access to real-time customer data is no longer a luxury. This article explains how a modern, modern, real-time infrastructure can help you close the gap between customer intent and action—before it’s too late.



