What is PII Masking and How Can You Use It?
Customer data is an essential component of modern business, but its collection and usage requires some tending. Data needs to be organized and indexed to be useful, so companies are incentivized to build the most efficient possible library of customer information, especially of data about individual customers. Unfortunately, the value and fraud potential of these collections attracts theft.
This article extends our previous articles on personally identifiable information (PII) masking, a safeguard for important data that can help promote the security of customers and your brand.
The importance of PII masking
In 2017, American personal credit agency Equifax was breached, leading to the theft of 140 million social security numbers — essential identifying information used throughout US society. Equifax has paid out at least 300 million dollars in claims and subsequently agreed to allow direct government oversight of its data management.
Beyond this well-known case, data breaches are a constant risk in modernity. Working to protect your data from intrusion is a necessary step in preventing this kind of outcome, but it is impossible to ensure total data security, and the low threshold for data breach attempts means it is likely your data will eventually be accessed.
Assuming that data breaches are inevitable but that you still need personal data to create value, how can you protect customers from fraud? An important second-line defense of data is PII masking — concealing or obfuscating data even when it is accessed from inside your own systems.
By implementing sound PII masking, you will be able to reassure your customers in the event of a data breach, minimize legal or reputational damage, and in some cases even protect the proprietary value stored in your customer data.
What is personally identifiable information?
There are many types of customer data that you may be interested in managing, not all of which can or must be masked. Personally identifiable information is any specific data collected by companies about someone's life, which could be used to identify or impersonate them.
While “personally identifiable information” is a standard term for data that could identify a person, there are various similar terms that cover the same concept and may carry different regulatory significance. For example, the EU’s General Data Protection Regulation (GDPR) uses a broader concept under the term “personal data.”
For the purposes of this article, we define ‘personally identifiable information’ as any real details of human lives or status, which could be used to identify or impersonate that person.
Common examples of PII are dates of birth, IP addresses, passport numbers, or full names.
Importantly, not all personal data is considered PII. Information like a customer’s nationality, age range, gender, or which bank they use is generally insufficient to resolve the identity of that customer. This distinction can be important, as masking data can inhibit its usefulness.
You could use a heuristic for deciding when biographical information constitutes PII by asking the question: “is there a system that relies on this information to reset a lost password?” Even apparently innocuous details like the names of family members, pets, or birthplaces could constitute PII that should be masked.
In any case, the safest way to determine which data should be masked is by assessing your legal exposure from a breach of that data.
What is data masking?
Data masking is a technique used to protect vulnerable PII while retaining some of its usefulness. Masking consists of somehow changing the actual PII in the database, either by rearranging data or replacing it entirely with synthetic data. The trick to data masking is: rather than simply inventing new data, the “shape” of masked data should remain as similar as possible to its unmasked state. This ensures that when the data is used for development, testing, or analysis, it can simulate real conditions as accurately as possible.
As an example, we might mask a name field by shuffling first and last names between entries and, while using that data in testing, find a bug related to non-Latin fonts. Someone replacing name data with random English words would not have found that bug, but anyone breaching the data has no useful information, just a jumble of disconnected names.
Situations where data masking is useful
In general, PII should be masked in any situation where the specific details aren’t absolutely needed. However, most data pipelines are very complicated, and it isn’t always clear which data must be available. Some teams need test data that accurately approximates real conditions; others may need genuine PII to contact customers or validate customer identity. Complicated demands on PII mean that data masking is just one more situation where having a clear organization of your data’s flow and usage is extremely helpful.
Static versus dynamic data storage
One way to think about data use cases is in terms of dynamism. Does this database need to be updated and current to be useful? If the data is being used to train, test, or preview systems, the answer is often that a static, masked database is sufficient for most purposes, as long as data fields match actual production.
Widespread internal usage
Data masking is very important even when that data is being consumed internally. Information central to your business, stored in a data warehouse, often needs to be accessed by employees in any department, all with different needs in terms of masked and unmasked PII. This is a good thing: enhanced internal access empowers your business with insights and value generation. But it also means an enhanced risk profile for your data.
Data masking therefore requires flexible layers of application, much like permission management. Different teams and individual employees need different access levels.
Data at high risk in a breach
Although security failures are almost by definition unpredictable, there are certain areas that are more likely to be exposed in a breach. Data that is accessible from public-facing servers is much more likely to suffer a breach than data that is safely tucked away on an internal system.
Exposure to third parties
Any time your company gives up custody of your data, it should certainly be masked as comprehensively as possible. Contractors, clients, researchers, or other third parties may legally and legitimately use your data, but PII should always be at an absolute minimum even beyond any regulatory controls. Remember — your data is valuable, and once it has left your control it is much harder to ensure it remains proprietary.
Data masking techniques
Given the demands on data masking — that it comprehensively protects PII, can be customized according to access level, and doesn’t overly disrupt data shape — it can be tricky to select the appropriate procedures to mask data. That has led to the development of a wide menu of masking approaches.
Shuffling and scrambling
The least disruptive forms of data masking, shuffling and scrambling, retain almost all of the data’s shape by simply rearranging existing data in a field or column. Scrambling rearranges data in a specific field, like a telephone number or house number. This persists the form of a data field (length, segmentation, or special characters), while obscuring the particular data. On the other hand, shuffling swaps all or part of a field with other rows in the data, so that precise data shape is preserved but is not identifiable with a particular individual.

In scrambling, data is rearranged within a single entry.
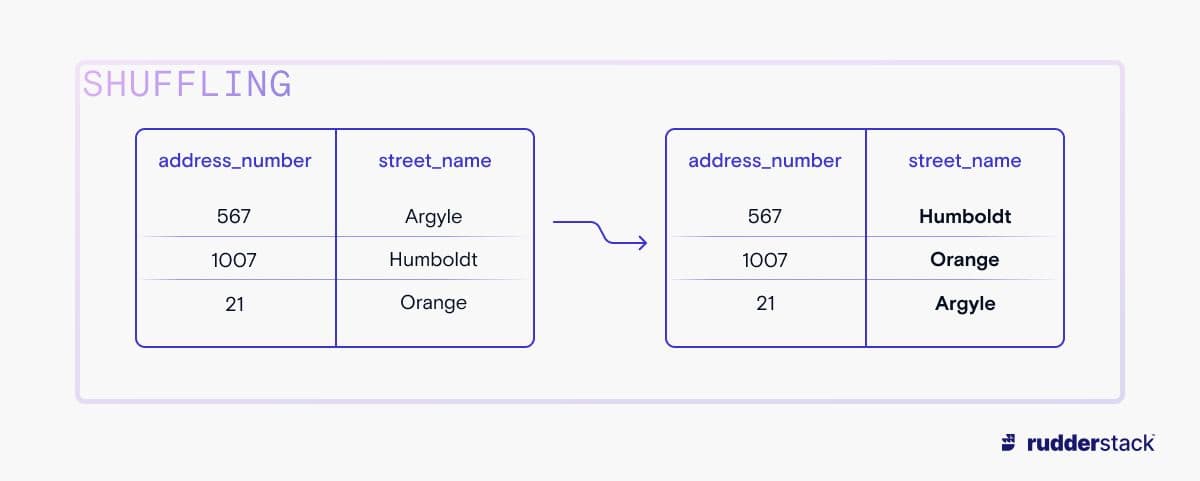
During shuffling, data in a given field is swapped around.
Shuffling and scrambling are not applicable to all types of data. Complex fields like medical status cannot be easily scrambled, and categorical variables may not have enough categories for
shuffling to effectively disguise data.
Substitution and variance
Substitution-based approaches opt for completely changing a data field to synthetic data not present anywhere in the original dataset. Substitution replaces data with an alternate entry that shares the data type of the original, whereas variance changes existing (usually numeric) fields by a random factor, thereby preserving their general distribution.

In this example, the variance approach ensures that heights are masked but remain within a reasonable range.
Hashing
Although subject to some debate about its core efficacy, a hashing function is a common and well-accepted method for masking PII. Hashing is essentially a (theoretically) non-reversible encryption, where a one-time key is used to transform a piece of data into a complex, usually 256 digit, code. Because the algorithm creates a complex end code, and because it is designed to avoid creating duplicate codes, your data is still generally unique — that is to say, if a column of social security numbers is hashed, an analyst could still test for duplicate values or use the hashed SSN as an identifier to work with other data, all without ever having access to the original SSN.
Nullification
At the most extreme end of PII masking, it’s possible to drop some information from the database entirely. This is generally undesirable, as nullifying a field removes almost all of its utility for testing or understanding the data. Nevertheless, for some extremely sensitive types of data, or for data that is not “need to know,” nullification is a sensible option.
How to incorporate data masking into your stack
Successful data masking requires a solid data stack, especially in terms of the company organization around that stack. Although your data stack might not be perfect from the start, it’s important to mask your PII as standard practice throughout the development of your pipeline.
The first step is identifying the shape and flow of your data. Understand what requirements you have for data masking by devoting resources to assessing the regulatory environment, the level of data integrity your brand needs to demonstrate, the value of different sections of data, and the risks from intrusion or internal breach.
Ensure as well that your data pipeline has no existing leaks — masking data after it is already exposed is not helpful. Your pipeline should be standardized and centrally planned as PII management comes into play.
Equipped with the map of your data pipeline and the landscape of regulatory needs, plan your data governance. Different teams and employees require different access levels to do their jobs. Managing this also means having a system for updating access privileges — always a pain point in new systems. Consider the possibilities of new data, new employees, or new tasks, and ensure a flexible and coordinated data governance schema is in place.
Throughout these touchups to your data stack, the data should be masked. However, only once all these elements are in place does data masking provide its full utility. Ensure that all existing fields are masked, and that new data that comes online is masked appropriately.
You can check out our documentation for a detailed walkthrough on what data masking looks like in code. Rudderstack Transformations use JavaScript or Python to mask data on its way through the pipelines of our customer data platform.
Data safety without imposition
PII masking provides companies with a system for maintaining their store of value without sacrificing customer trust, regulatory compliance, or internal data utility. Although it is a widespread practice that is even mandated by some jurisdictions, it’s still important to research the available methods and find the best approach for your company.
Beyond simply masking PII, it is important to understand the fundamentals of personal data management. In this article we covered PII masking]. To continue learning about customer data management check out these other articles from our learning center.