What is Data Mapping?
Data mapping is a crucial part of a wider data strategy, offering benefits like improved consistency and integration. The process can be automated, semi-automated, or manual. A typical data mapping process includes identifying data fields, standardizing them, creating rules for transformation, testing these rules, and finally, executing data-related tasks. In this article we’ll look at data mapping definitions and the benefits of implementing a data mapping strategy.
What is Data Mapping?
Data mapping is a key process in managing business data, where information is tracked as it moves from its origin to its final destination. This involves detailing the data fields involved, the transformations they undergo, and the protocols followed, ensuring accuracy and preventing errors.
Data mapping is a process used by businesses to track and manage the journey of their data from its original source to its final destinations. It delves into specifics like:
- Identifying the specific database or software fields that the data will occupy.
- Determining necessary data transformations for appropriate formatting.
- Establishing protocols to prevent errors such as data discrepancies.
Essentially, data mapping serves as a detailed set of guidelines for efficiently transferring data across the various databases and tools within an organization.
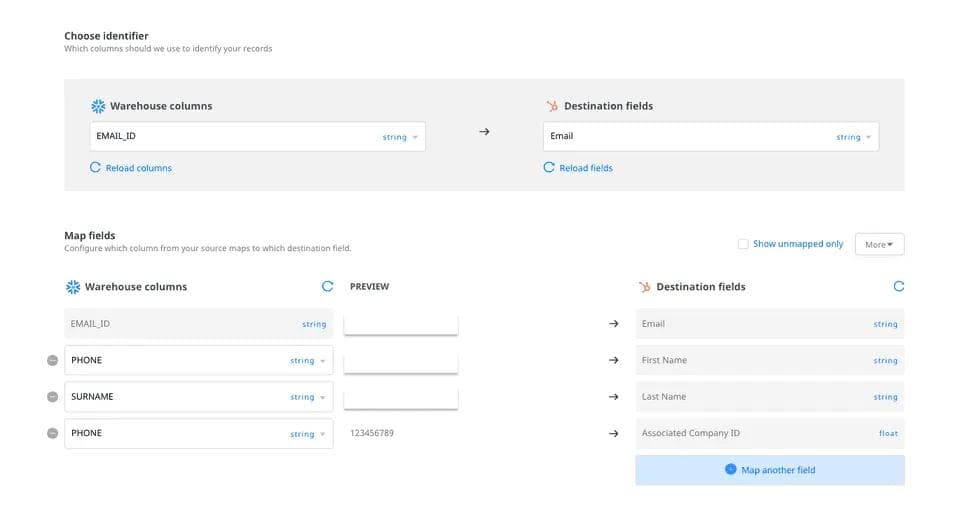
Visual data mapping in Rudderstack
Data mapping plays a pivotal role in shaping your overarching data strategy framework, serving as the foundational element that sets the stage for various critical data-related processes. Here's a detailed breakdown of how data mapping seamlessly integrates into your broader data strategy:
1. Data Integration: Data mapping serves as the cornerstone for successful data integration efforts. This process involves harmonizing disparate data sources, bringing them together into a centralized repository, and ensuring data consistency. For example, imagine the collaboration between your marketing and sales teams. They might each have their own lists of leads with varying data formats and naming conventions. Data mapping enables the reconciliation of these differences by identifying common data elements, eliminating duplicates, and transforming the data into a uniform structure. This consolidation facilitates more efficient decision-making and analysis.
2. Data Migration: Data mapping is indispensable during data migration projects. As businesses evolve, they often need to shift their data from one location or system to another. This could involve moving data from on-premises servers to cloud platforms like AWS or Azure, upgrading database systems, or transitioning to a different storage format. Data mapping ensures a smooth transition by meticulously defining the data mappings between the source and target environments. It allows for data transformation, schema adaptation, and ensures data fidelity throughout the migration process, minimizing disruptions and data loss.
3. Data Transformation: Data mapping is instrumental in the process of data transformation. This refers to the conversion of data from one format or structure to another, often necessary to suit specific business requirements or analytics tools. For instance, consider the task of converting data from an XML format to a more user-friendly CSV format. Data mapping in this context involves deciphering the XML schema, identifying corresponding elements in the CSV format, and mapping the data accordingly. This transformation makes data more accessible and usable for downstream applications and analysis.
In summary, data mapping serves as the linchpin of your data strategy framework, enabling seamless data integration, facilitating smooth data migrations, and empowering data transformation efforts. It ensures that data flows cohesively across your organization, fostering data-driven decision-making and enhancing the overall efficiency and effectiveness of your data-related processes.
Benefits of Data Mapping:
Enhanced Data Consistency and Reconciliation
Data consistency is crucial for the accuracy and reliability of information across different systems and databases. Consider a scenario where a business has multiple, conflicting customer profiles for the same individual. This inconsistency can lead to various operational challenges, such as inconsistent customer experiences, internal misunderstandings, and poor decision-making due to unreliable data. Data mapping addresses these issues by aligning corresponding fields across systems, ensuring both accuracy and synchronicity. It helps in reconciling duplicate entries and flagging incomplete records, thereby maintaining a high standard of data integrity.
Streamlined Data Integration Process
Data integration involves consolidating diverse data from multiple sources into a cohesive, unified format. Data mapping is integral to this process, providing a clear framework for how data should be transferred and transformed between different systems. By defining the relationships between data fields in various systems, it ensures that data populates correctly in its target system, thereby streamlining the data integration process.
Robust Data Governance
Effective data governance encompasses setting policies for data management, which includes standardizing naming conventions, appointing data stewards and stakeholders, promoting data democratization, and ensuring compliance with privacy regulations. Understanding the movement and storage of data within an organization is critical for preventing the mishandling of sensitive information, such as personally identifiable information (PII). Data mapping plays a vital role in this aspect by providing clear visibility and control over data flow, thereby reinforcing data governance initiatives.
Data Mapping Methods
Data mapping is a versatile and context-dependent process, with its implementation varying based on factors such as available resources, data volume, system compatibility, and scalability requirements. Here are three widely-used data mapping techniques, each with its unique advantages and applications:
1. Automated Data Mapping:
Automated data mapping leverages specialized software to align new data with an existing structure or schema. These tools often utilize machine learning algorithms to continuously refine and enhance data models. The benefits of this approach are manifold:
- It facilitates the seamless integration of data from a vast array of sources.
- Enables personnel without deep technical expertise to manage complex data operations using intuitive user interfaces.
- Offers dynamic visual representations of data flows.
- Provides real-time alerts for emerging issues, aiding prompt resolution.
- Simplifies troubleshooting with targeted repair mechanisms.
2. Semi-Automated Data Mapping (Schema Mapping):
This technique represents a middle ground between fully automated and manual data mapping. Developers utilize software designed to establish connections between various data sources and their respective targets. After the initial mapping by the software:
- Team members manually review and refine the mappings, ensuring accuracy and relevance.
- This approach is particularly effective for handling smaller data sets or for basic data integration, migration, or transformation tasks.
- It's a cost-effective solution for smaller teams or organizations with limited budgets, providing a balance between automation and manual oversight.
3. Manual Data Mapping:
Manual data mapping is more hands-on, requiring developers to explicitly code the rules for transferring or transforming data from one source field to another. While increasingly challenging in the context of modern business data volumes, it still has its place:
- Ideal for one-off projects or smaller-scale data warehousing initiatives where the data volume is manageable.
- Provides a high degree of control and customization, allowing for specific, tailored data handling.
- Though labor-intensive, it can be a viable option when automated solutions are not available or feasible, particularly in situations with unique or complex data mapping requirements.
The Data Mapping Process
The process of data mapping involves several key steps, each critical to ensuring the accuracy and effectiveness of the data handling. Here's a rephrased and expanded version of these steps:
1. Identify Necessary Data Fields: The first step requires a thorough assessment of which data fields need mapping. This varies greatly depending on the project’s goals. For example:
- Integration: Assess the volume and variety of data sources, and the frequency of integration. Complex and frequent integrations typically necessitate automated tools, while simpler, one-time tasks might be manageable manually.
- Migration: Evaluate the data at the source and determine what is needed at the target location. The larger the data volume, the more beneficial automated software becomes.
- Transformation: Identify the desired format for your target destination. While automated tools are generally needed for modern, large-scale transformations, smaller projects might be feasible manually.
2. Standardize Data Formats Across Sources: This involves harmonizing the format of data across different sources. For instance, if one department records monetary values with symbols (e.g., $, €) and another uses codes (e.g., USD, EUR), decide on a uniform format for the target data.
3. Establish Data Transformation Rules and Schema Logic: The approach here depends on the method of data mapping:
- Automated Mapping: Utilize user-friendly interfaces that facilitate easy mapping, accessible even to those without technical expertise.
- Semi-Automated Mapping: Leverage software to form initial connections between data sources and their targets, followed by manual verification by a knowledgeable developer or data scientist.
- Manual Mapping: Engage a skilled software engineer to create and implement detailed mapping rules or schemas.
4. Test the Mapping Logic: Before full implementation, test a small data sample to check for errors. Automated mapping tools often come with verification features and alerts, but manual checks are advisable for assurance. In manual mapping, rely on experienced professionals for validation.
5. Execute the Migration, Integration, or Transformation: Once the logic is tested and validated, proceed with the full process. The complexity of this step depends on the desired outcome and the tools utilized.
Each step in this process is critical for ensuring the data's integrity and usefulness, and the choice between manual, semi-automated, or automated methods will depend on the specific needs and resources of the project.
Streamline and enhance the efficiency of your data handling processes using Rudderstack
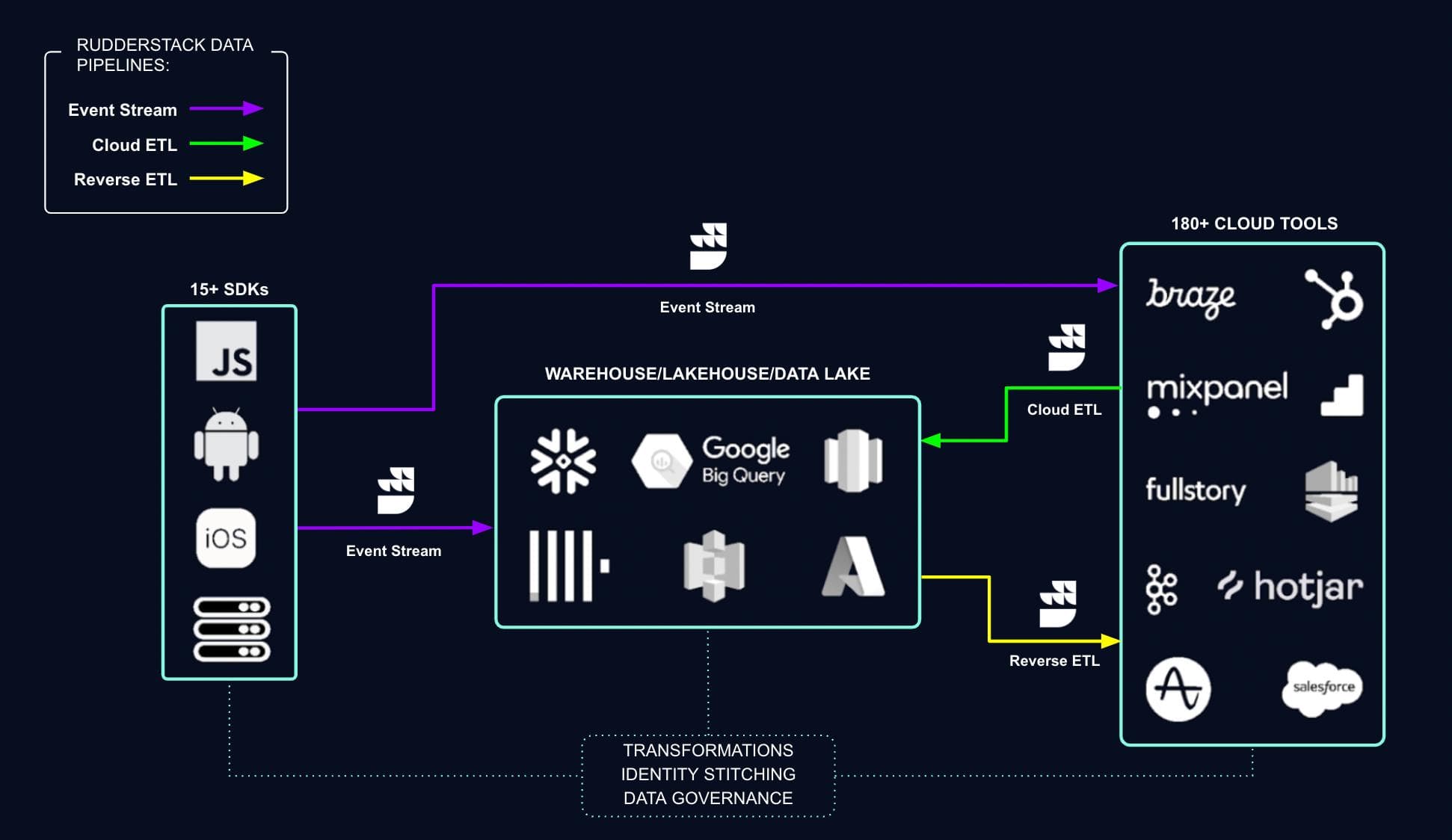
A CDP, unlike traditional data management tools, is built to eliminate data silos by collecting and organizing data from multiple 1st and 3rd party data sources to create complete customer profiles.
Customer Data Platforms typically perform three key functions: data collection, data unification, and data activation.
Data mapping is primarily tied with data activation. For example, with Reverse-ETL you can leverage all the existing tables in your warehouse and easily map data to the appropriate fields in downstream destinations like marketing automation software, Google Ads accounts, analytics dashboard or a CRM for activation
Rudderstack’s warehouse native CDP allows Collect, unify, and activate your customer data with event stream, profiles and reverse ETL, making a CDP a key tool in your data mapping arsenal.