How to Move Data in Data Warehouses
Business Intelligence (BI) alone may be unsuitable or ineffective in indicating the next steps for your business. While BI enables you to analyze data and surface trends that help you arrive at actionable insights, the sourcing, moving, and storage of the data it uses is equally important. When it comes to BI, garbage in = garbage out. In order to develop a data-led culture and make BI operational, companies need to ensure that the data accessed is accurate, unified, and as close to real-time as possible. It’s here that data warehousing is invaluable.
Data warehousing systems have been a traditional part of business intelligence suites for no less than three decades now. However, they have taken on a life of their own evolving with the emergence of new data types and data hosting techniques. A data warehouse is like any physical warehouse. it’s a container for data from multiple sources. It’s beneficial to use a data warehouse if you have to make data-informed decisions, consolidate or merge data from multiple sources, or analyze historical data.
In this article, we’ll explore the various ways data enters, moves through, and exits a data warehouse. We’ll also look at how this data is formatted and stored. Finally, you’ll learn how a successful data warehouse strategy helps businesses understand their current position and set measurable benchmarks to drive sustainable long-term growth.
A high-level overview of how data passes through a data warehouse
A data warehouse, or formally, an enterprise data warehouse (EDW), is a go-to repository of information in an organization. It is almost always separate from the data sources that are used for day-to-day business logic and transactions. This central repository exists to ease access to information for analysis to bring about informed decision-making.
How does using a data warehouse make collected data more useful?
When organizations collect data, the process usually involves several sources. A data warehouse is a consolidating tank for all those data streams, including transactional systems and relational databases.
However, the data isn’t quite ready for use at the time of collection. In a nutshell, the purpose of a data warehouse is to provide one comprehensive dataset with usable data that’s aggregated from these various sources. There are several types of collecting tanks that a company could decide to use to achieve this final data product. Therefore, it’s important to differentiate common data collection entities, such as data warehouses, databases, and data lakes and discuss their places in this process.
First, for a business to thrive in the face of modern competition, it must pay attention to data and analytics. As a result, dashboards, reports, and analytics tools have become prevalent for mining insights from their data, monitoring business performance, and supporting decision-making. For more advanced users, this data store also enables data mining, artificial intelligence (AI), and machine learning applications, in addition to pure data analysis.
A database captures and stores data in tabular format using a schema. Data could be the details of an e-commerce transaction, for instance. This includes items in carts, email addresses, credit card information, and physical addresses. So, for each customer, you can have a database of all their purchases along with the corresponding payment and shipping information. Databases store data by rows since the application logic usually requires an entire row and not just a few fields.
Data warehouses are the engines behind analytics tools, dashboards, reports, machine learning applications, and more. They store data efficiently in a way that minimizes data I/O (input and output) and concurrently deliver query results to a large number of users, ranging from hundreds to thousands. Data warehouses store data in columns since data engineering and analytics processes often require whole columns of data, but not full rows (e.g. counts of distinct orders, sums of purchase amounts vs. a singular complete transaction record).
On the other hand, a data lake is a data container designed to hold data in its native or raw format. A data lake supports scalability for massive amounts of data. There are three broad classes of data in a data lake:
- Structured data
- Semi-structured data
- Unstructured data
In order to store and secure large amounts of these three classes of data, many opt to use data lakes based on their analytic performance and native integration.
Having considered tabular databases and free-form data lakes, we can now revisit the concept of data warehouses. One may call them a hybrid of sorts, since data warehouses need all data organized in tables to allow the use of SQL to query the data. But, not every application needs tabular data. Big data analytics, full-text search, and machine learning can access unstructured or semi-structured data.
In the data warehouse, processing, transformation, and ingestion occur before users access the processed data using BI tools, SQL clients, and even simple spreadsheets.
Thus, a data warehouse allows companies to analyze their customers more thoroughly. As a convenient repository for data analytics, it involves reading large amounts of data to detect relationships and trends. Using a data warehouse automatically means you have to consider every possible source of information in terms of volume and type. Furthermore, data mining patterns become easier to spot when using a data warehouse, leading to better sales and profits.
How Do Data Warehouses Receive and Manage Data?
It used to be common to have a data warehouse located on-premise, typically on a mainframe computer. Its primary functionalities were data extraction from other sources, data cleansing, data preparation, and loading and maintaining the data in a RDBMS (Relational Database Management System).
Modern data warehouses run on a dedicated appliance or in the cloud. This enables remote administration of the data warehouse and makes it easier for authorized personnel to carry out their work functions outside the confines of the office. Cloud Data Warehouses also allow for easier integration of third-party ETL services that handle extraction, transformation, and loading of data from source systems into the data warehouse. Since data warehouses are optimized for low frequency but large amounts of I/O, the actual loading of data into the warehouse is often done in batch processes rather than a large number of individual INSERT statements.
Variations on how a data warehouse can receive and return data
Better decisions are possible with more data sources; this is the crux of analytics and business intelligence. It is essential to explore how businesses can receive and return data from data warehouses.
Data ingestion describes the process of moving data from different sources to a storage medium, such as a cloud object storage service or the data warehouse itself, where it can be accessed, used, and analyzed by the organization.
Data ingestion precedes data digestion. The ingestion layer is the core of any analytics architecture because consistent and accessible data is crucial to downstream reporting and analytics.
There's an assortment of options to ingest data. These range from simple plug & play ETL services to completely custom ETL scripting pipelines. Which option is used usually depends on the source system data is to be extracted from.
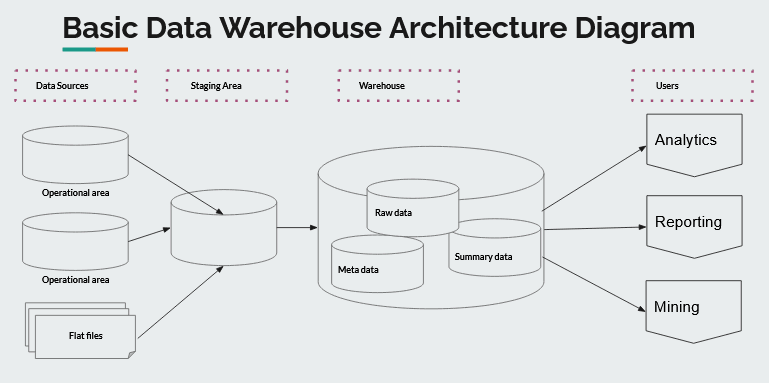
Basic data warehouse architecture diagram
Data ingestion methods
Specific business requirements and constraints determine the appropriate data ingestion layer to use. This supports an optimal data strategy, and businesses will choose the appropriate model for each data source depending on how quickly and how often they’ll need analytical access to the data.
Batch processing
Batch processing is the most common data ingestion type. Here, the ingestion layer collects and groups source data periodically and then sends it to the destination system. The processing of data groups depends on any logical ordering, activation of specific preconditions, or a simple schedule.
Where near-real-time data is not paramount, batch processing is a logical option. It's more accessible and more affordable than streaming data ingestion, so it’s the default way of ingesting data into a data warehouse. However, many cloud data warehouse vendors also support streaming data.
Stream processing
Also known as streaming or real-time processing, stream processing requires no grouping. Data sourcing, manipulation, and loading happen as soon as the data is created or recognized by the ingestion layer.
Stream processing is more expensive than batch processing because it’s significantly more resource-intensive. It requires systems to monitor sources continuously and accept new information, but it works great for analytics requiring continually refreshed data.
Choosing between batch and stream processing should come down to how quickly your use case requires access to new data. Is instantaneous access to new data actually required, or are 30-60 minute batches fast enough?
Micro batching
Some streaming platforms, such as Apache Spark Streaming, use a variant of batch processing that involves smaller ingestion groups or smaller preparation intervals (typically a few minutes), but with no individual processing.
Imagine a large e-commerce company that wants to know how the recent overhaul of its web user interface impacted user behavior. Waiting for hours or even a full day as you might with batch processing may not be feasible, because reduced conversion rates could mean lower revenues or profits. In this case, micro batching could be a suitable alternative.
With micro batch processing, your data is available in near real time. Some data architecture descriptions use the term interchangeably with event stream processing (which we’ll talk about more later), however, many analysts consider micro batch processing a distinct category of data ingestion. If you need fresh–not quite real-time— data for uses such as web analytics or user behavior, you probably need to look no further than micro batch processing.
Loading raw files into a data warehouse using Python and PostgreSQL
Another way to accomplish data ingestion in a data warehouse is by loading data via automation with software code. One way to achieve this is using the open-source Python programming language and PostgreSQL database together. Once you install PostgreSQL, you’ll need to provision a database by creating one. The command is simply CREATE DATABASE lusiadas;.
Then, you’ll install the sqlalchemy package to connect your database through Python. Type the following code into your shell program or Anaconda prompt:
>>> pip install sqlalchemy
Then download, install, and import all the libraries you'll need in your Python script:
from sqlalchemy import create_engine import psycopg2 import pandas as pd import streamlit as st
Now establish a connection to your records_db database. Also, create a table in which to store arrays and records.
You’ll also need to create a separate connection to the datasets_db database that your data sets will go into:
engine = create_engine("postgresql://<username>:<password>@localhost:5432/records_db") engine_dataset = create_engine("postgresql://<username>:<password>@localhost:5432/datasets_db") engine.execute("CREATE TABLE IF NOT EXISTS records(name text PRIMARY KEY, details text[]")
Note that Postgres’s naming conventions require table names to begin with underscores or letters only. Additionally, they may not contain dashes and must be less than 64 characters long.
Your records table needs a name field that’s a text data type. Declare it as a PRIMARY KEY. Another details field should be added as text to tell Postgres that it's a single-dimension array.
You'll use the primary key name field to search records when interacting with the data.
As a side note, it's more secure to store database credentials in a configuration file and then invoke them as parameters in your code.
Now, you can create five functions to write, update, read, and load raw data to and from your database:
def write_record(name, details, engine): engine.execute("INSERT INTO records (name, details) VALUES ('%s', '%s'" % (name, details)) def read_record(field, name, engine): result = engine.execute("SELECT %s FROM records WHERE name = '%s'" % (field, name)) return result.first()[0] def read_record(field, name, new_value, engine): engine.execute("UPDATE records SET %s = '%s' WHERE name = '%s'" % (field, new_value, name)) def write_dataset(name, dataset, engine): dataset.to_sql('%s' % (name), engine, index=False, if_exists='replace', chunksize=1000) def read_dataset(name, engine): try: dataset = pd.read_sql_table(name, engine) except: dataset = pd.DataFrame([]) return dataset def list_datasets(engine): datasets = engine.execute("SELECT table_name FROM information_schema.tables WHERE table_schema = 'public' ORDER by table_name;") return datasets.fetchall()
Comparing data sources and how they inform data warehouse architecture
Every data warehouse architecture consists of tiers. The top tier is the front-end client that enables the presentation of results through analysis, reporting, and data mining tools. Tools for accessing data warehouses include analytics applications and SQL clients.
The middle tier comprises the analytics engine helpful in accessing and analyzing data.
The bottom tier of a data warehouse architecture is the database server, where data is loaded and stored. Data may be stored in fast storage (such as SSD drives) for frequent access, or in a cheap object store like Amazon S3 for infrequent access.
The data warehouse will automatically move frequently accessed data into fast storage to optimize query speed. Most data warehouse architectures will deal with structured data. Most will come from streams but others will result from transformation processes such as ETL and reverse ETL. Let’s take a closer look at each of these data sources.
Event stream
Like event-driven architecture, event streaming centers around events. An event is a record of a past occurrence. It could be a mouse click, a keystroke, a purchase, or a successful loading of a program.
In event streaming services such as Apache Kafka, streams of events are published to a broker. The consumers of event streams can access each stream and consume the events they want. The broker retains those events.
Some view event stream processing as a complement to batch processing. But, the latter focuses on taking action on a large set of static data or data at rest, whereas event stream processing takes action on a constant flow of data or data in motion.
Event streams work when you need instant action on data; therefore, you'll hear experts call it "real-time processing." Streaming data warehouse architecture would then comprise software components built and wired together to process streaming data from several sources as soon as the data is available or collected.
It's essential to consider the characteristics of the data streams when designing event stream architecture. They usually generate massive volumes of data and require further pre-processing, extraction, and transformation to be of any significance.
Event streams are prevalent in data warehouse implementations such as big data integration, natural language processing (NLP), tactical reporting, and auditing and compliance.
It is common practice to utilize event stream processing to perform preliminary data sanitation and then output the data to a cheap storage medium that the data warehouse can access as needed, while reserving the data warehouses storage and compute capabilities for further transformation and analysis.
ETL
Extract Transform Load (ETL) is a three-step data integration process for synthesizing raw data from a data source to a data warehouse or other destination such as a relational database or data lake.
ETL blends data from multiple sources to build the data warehouse. That is, you take data from a source system, transform (convert) it into an analysis-friendly format, and load (store) it into your data warehouse.
The idea behind ETL is to push processing down to the database and improve performance. It provides a deep historical context for the business when combined with an enterprise data warehouse. It also makes things easier for business users to analyze and report data essential to their work.
ETL codifies and reuses processes that move data, but doesn't require coding skills. There are a variety of ETL service providers that specialize in plug & play integration of ETL from source systems (CRMs, marketing automation, payment providers, etc.) to a variety of storage destinations like data lakes, warehouses, or even databases.
Reverse ETL
While ETL moves data from source systems into the data warehouse, there are times when it’s necessary to move data out of the centralized data warehouse. Reverse ETL involves copying data from the data warehouse into systems of record across a company.
One of the purposes of a centralized warehouse is to eliminate data silos, which prevent information sharing and collaboration across departments, but It’s possible for the data warehouse itself to become a data silo. Reverse ETL offers a solution to this problem, and it also allows your business's core definitions to live outside the data warehouse.
With reverse ETL, there are a few prominent use cases:
- Operational analytics, to feed insights from analytics to business teams for improved decision-making
- Data automation, such as when your finance unit needs to issue invoices using a CSV
- Data infrastructure, as a general-purpose software engineering pattern to handle the growing number of data sources in modern business
- Identifying at-risk customers and spotting signs of potential customer churn
- Driving new sales by correlating data from the CRM and other interfaces
Generally speaking, reverse ETL is useful when your data originates in one system but needs to be in another system to add additional value. For example, a customer’s billing and renewal information likely lives inside your payment processor’s (e.g. Stripe) system. This information would be invaluable in a helpdesk tool where account value, transaction summaries and more could help properly route and prioritize support tickets. With reverse ETL, it’s possible to share the data from the payment system with the helpdesk tool.
Processing Data in a Data Warehouse
Imagine that a company needs to coordinate and manage its data transformation workflows. Some data analysts might schedule queries on tools such as BigQuery for transformation workflows before testing the transformed data.
However, many lack a comprehensive infrastructure to automate the building, compiling, testing, and documenting of SQL models. This limits the scalability of the process, but it's precisely where dbtshines. Let’s take a closer look at this tool that helps data analysts and engineers to transform data in a reliable, fun, and fast way.
dbt
dbt stands for data build tool. It is a command-line utility that enables data analysts and engineers to transform data in their warehouses using simple select statements. The analysts can use it to clean data and minimize time spent on manual checks. Thus, a company can write transformations as queries and efficiently orchestrate them.
One advantage of using dbt is that non-engineers can also use it, promoting shared data knowledge between engineering and non-engineering teams. It also supports a highly flexible data model, so it's easy to recreate data and backfills.
dbt also ensures that data warehouse-level transformations are a piece of cake, allowing you to count on in-built data quality testing. Plus, it includes reusable macros and an online, searchable data catalog and lineage.
Other Third-Party Tools
Besides dbt, other third-party tools for processing data in a data warehouse include:
| Tools | Use(s) |
|---|---|
BigQuery | Cloud data warehouse tool |
CloverDX | Data integration platform for full control |
Dundas | Dashboard, analytics, and reporting tool |
Hitachi Vantara | Open-source tool for analytics and BI |
PostgreSQL | Open-source object-related database system |
QuerySurge | RTTS-developed solution for ETL testing |
SAS | Accessing data from various sources |
Sisense | BI tool for real-time analysis and visualization |
Solver | Reporting, data storage, and interactive dashboards |
Tableau | Data visualization in BI |
Teradata | Displaying and handling large quantities of information |
Conclusion
A data warehouse provides an efficient way to manage multiple-source data. Businesses invest in a data warehouse architecture because of the edge it offers them in terms of analytics, data mining, insights, and decision-making. To win and retain customers, paying attention to data generated during the buyer journey is essential.
In closing, It’s important to note that it's not enough to move data into the data warehouse, deploying an active maintenance routine is equally important. This ensures that column, table, schema, and database names are straightforward and consistent, and that only authorized users will run simple select statements using the root user account.
Proper maintenance also ensures that the public schema and public role of a the data warehouse are used sparingly and ownership, privileges, and lineage are clear. These factors combine to enable the use of a data warehouse to efficiently provide answers to business questions and data administration questions.