Blog
What is reverse ETL? Improve your warehouse data activation with this ultimate guide from RudderStack
What is reverse ETL? Improve your warehouse data activation with this ultimate guide from RudderStack

Brooks Patterson
Head of Product Marketing
14 min read
November 4, 2024
Businesses need to consolidate and analyze vast volumes of data to stay competitive. Cloud data warehouses provide a powerful solution for data centralization and analysis, but this warehouse data must be sent downstream for business teams to maximize its value. Reverse ETL pipelines make this process easy.
With reverse ETL, it’s easy to sync data from the cloud data warehouse into downstream operational systems, eliminating data silos and enabling data activation.
What is reverse ETL?
Reverse ETL flips the traditional flow of data in an Extract, Transform, Load (ETL) process. In a typical ETL process, data is extracted from operational systems, transformed and processed, and then loaded into a data warehouse for storage and analysis. However, in reverse ETL, data flows in the opposite direction, moving from the data warehouse back into operational systems or other data stores.
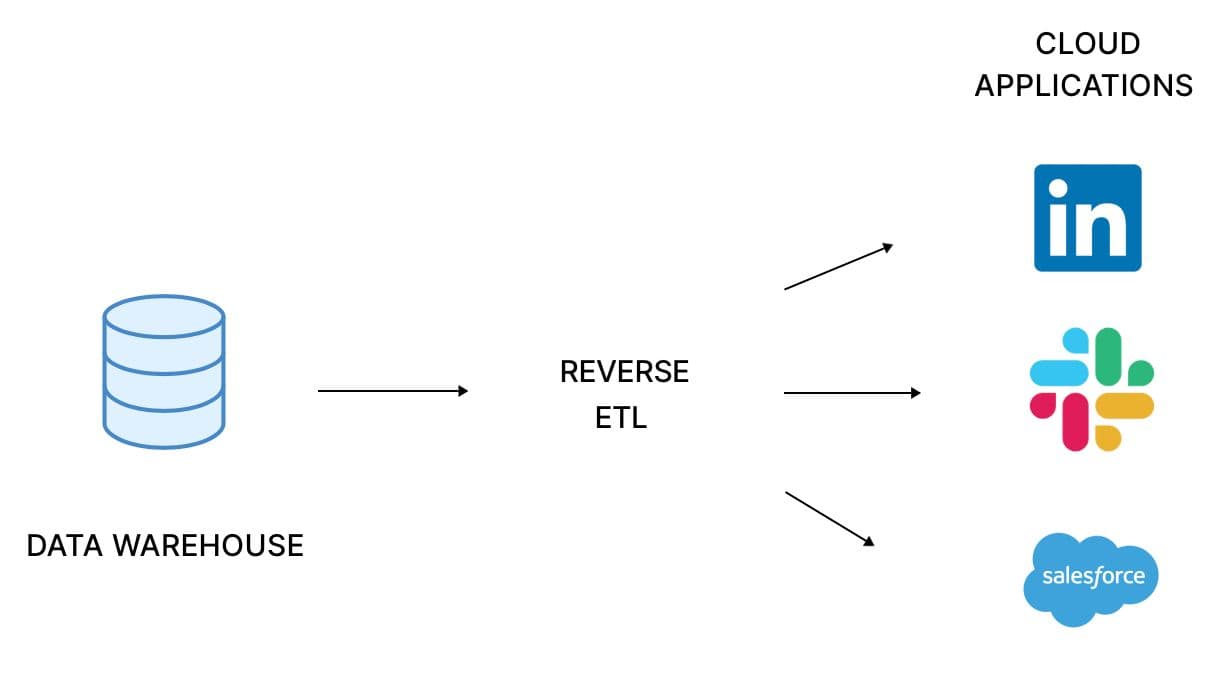
A diagram showing the reverse ETL data flow from the data warehouse to operational systems.
Reverse ETL solves data access issues common in traditional warehouses by delivering processed data to operational systems. This enables swift, data-driven decision-making and performance optimization.
Below are a few practical applications of reverse ETL:
- Convert lead data from Salesforce into a format easily imported into marketing platforms for further marketing automation processes.
- Update master customer profiles in your CRM by combining data from multiple sources (e.g. orders placed on your website, support tickets opened in Zendesk, or subscription activations in Salesforce).
- Convert transaction data into machine learning training sets. For example, you could use reverse ETL to convert purchase history data into training records for a custom deep-learning model that predicts customer lifetime value.
ETL vs. reverse ETL: Understanding the differences
The key difference between ETL and reverse ETL lies in the direction of data flow.
ETL extracts and transforms data from source systems before loading that data into a data warehouse. Reverse ETL involves extracting data from the data warehouse and loading it back into operational systems and SaaS tools for real-time data availability. While the steps are the same in both processes, the direction of movement from the data warehouse is opposite.
Here’s a detailed breakdown of reverse ETL vs ETL:
1. Direction of data flow: In ETL, the data flow follows a traditional path. Data is extracted from source systems, transformed according to business rules and requirements, and loaded into a data warehouse or data lake.
In reverse ETL, the data flow is reversed. It involves extracting data from the data warehouse or data lake and loading it back into operational systems or other data stores.
2. Purpose: The primary purpose of ETL is to consolidate data from various source systems, transform it into a consistent and structured format, and load it into a centralized repository (data warehouse or data lake) for analytical purposes.
The main purpose of reverse ETL is to ensure that relevant and up-to-date data from the data warehouse flows back to operational systems or other data stores, enabling near-real-time data availability for operational processes and decision-making.
3. Data transformation complexity: In ETL, data transformations play a significant role. This involves cleaning, aggregating, integrating, and enriching data to ensure its consistency and suitability for analysis in the data warehouse.
In reverse ETL, the focus is more on data synchronization and formatting to meet the requirements of the operational systems or data stores. The emphasis is on delivering the data in a usable format rather than extensive transformation.
4. Data volume and frequency: ETL processes typically deal with large volumes of data from various sources. Data extraction, transformation, and loading often occur in batches or at scheduled intervals, depending on the specific requirements.
Reverse ETL processes generally involve smaller subsets of data, focusing on delivering relevant, fresh data to operational systems. The frequency of data delivery can be set, or even triggered by certain events, to ensure the operational systems have the most recent data.
5. Data destination: The primary data destination in ETL is the data warehouse or data lake, where data is stored for analysis, reporting, and business intelligence purposes.
In reverse ETL, the data destination is the operational systems, data stores, or other SaaS tools that require access to up-to-date data for operational processes, decision-making, or customer-facing applications.
How does reverse ETL fit into the modern data stack?
In the modern data stack, Reverse ETL is the link between the data warehouse/lake and the operational systems. Here's a simplified representation of a modern data stack:
- Source systems: These are the systems where data originates, such as transactional databases, SaaS applications, or external data sources.
- Event stream: This is the process of capturing, processing, and delivering real-time event data from websites, applications, and server-side sources to various destinations, including data warehouses/data lakes.
- Extract, Transform, Load (ETL): The traditional ETL process involves extracting data from source systems, files, and APIs, then transforming it to meet specific requirements and loading it into a data warehouse or data lake.
- Data warehouse or data lake: This is the central repository where structured or unstructured data is stored for analysis and reporting. The data warehouse provides a consolidated view of data from different sources. Examples of this are Snowflake, Amazon RedShift, and Google BigQuery.
- Analytics and business intelligence (BI) tools: These tools consume data from the data warehouse or data lake and are used to analyze data, generate insights, and create visualizations or reports for business users. BI tools like Hex, Looker, or Tableau enable teams to explore and present data effectively. Data teams often use data transformation tools like dbt to create SQL models that prepare and structure the data before it is consumed by BI tools for visualization and reporting.
- Reverse ETL: Reverse ETL comes into play after data in the data warehouse or data lake has been analyzed and enriched to add valuable insights that can be used to make business decisions. It involves extracting relevant data from the warehouse and loading it back into operational systems or other data stores. Learn more about RudderStack Reverse ETL.
- Operational systems: These are the systems used by operational teams to carry out day-to-day business processes, such as customer relationship management (CRM), marketing automation, and customer support systems. Examples of this are Salesforce, HubSpot, Customer.io, and Slack.
- Applications and end-user interfaces: These are the interfaces through which end-users interact with the operational systems and consume the data for their specific needs.
Exploring reverse ETL use cases
The results of implementing reverse ETL can be far-reaching and impactful for organizations. By enabling easy sync from the data warehouse to operational systems, reverse ETL facilitates the generation of deeper insights and unlocks the potential of various business tools and platforms:
1. Activation Customer Data Platforms (CDPs): Reverse ETL enables activation CDPs to use valuable data from the data warehouse to ensure that information like customer preferences, behaviors, and engagement history is accurate and up-to-date. This enables more effective customer segmentation, personalized marketing campaigns, and improved customer interactions.
2. Sales and Marketing Automation: Reverse ETL keeps sales and marketing platforms like Salesforce, HubSpot, and Marketo in sync with enriched data from the warehouse, powering lead scoring, personalized outreach, and automated workflows based on the latest customer insights.
3. Customer Support Tools: By syncing data to platforms like Zendesk or Help Scout, Reverse ETL ensures support teams have fresh customer profiles with critical data from the warehouse, including past interactions and product usage data, allowing them to deliver more personalized and effective support.
4. Marketing and Product Analytics: Reverse ETL syncs enriched, consistent data from the warehouse into tools like Amplitude, Mixpanel, or Google Analytics. This approach provides a holistic view by combining behavioral data with context from other sources, unlocking deeper insights. Marketing teams can better optimize campaigns, while product teams use comprehensive metrics to improve user experiences and guide feature development.
There are several reverse ETL tools available in the market that can facilitate the process of extracting data from a data warehouse and loading it back into operational systems through built-in connectors.
RudderStack’s Reverse ETL software can operationalize warehouse data and enable data teams to easily send warehouse data tables, features, and metrics to different marketing, sales, and support tools like Salesforce, Customer.io, and Zendesk.
Reverse ETL: Paving the way for operational analytics
Data warehouses are designed with analytics in mind. They're meant to store and organize large amounts of data to be queried and analyzed to uncover trends, make predictions, and inform business decisions.
The operational systems used by sales, marketing, and support teams—such as CRMs, customer engagement, and customer service platforms—are built differently to support day-to-day interactions and workflows. They are designed to facilitate seamless communication, manage customer relationships, and drive immediate actions rather than long-term analysis.
Historically, these systems have been separate and siloed, but with so much valuable data in the warehouse, there’s a push to make the data warehouse a central source of truth that can fuel the operational systems used to drive growth with more valuable, complete customer data.
Reverse ETL enables data to flow from data warehouses and other data stores into operational systems so businesses can use it to improve and automate their processes. In other words, reverse ETL is the glue that ties together data-driven operations, or what many call the last mile in the data pyramid.
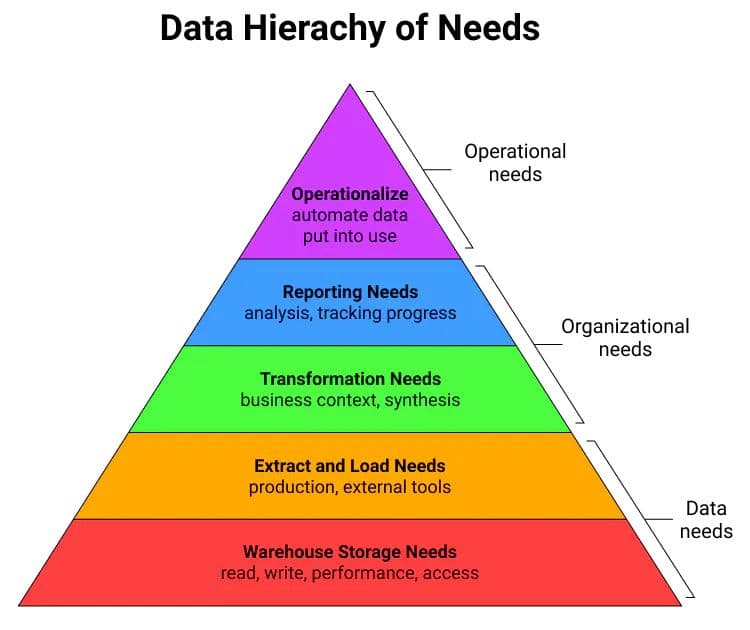
A diagram of the Data Hierarchy of Needs.
This data pyramid shows all the work involved in preparing, analyzing, and operationalizing data to enable truly data driven processes and automations. Reverse ETL is a critical part of the final stage of effective data management: putting it to use.
The benefits of reverse ETL extend beyond data activation. By automating data delivery into the tools business teams use, data engineers have more time to work on strategic initiatives.
What are the benefits of using reverse ETL?
Reverse ETL transforms a data warehouse from a passive data store into a powerful engine for action, enabling businesses to leverage their data more effectively. Here are the key benefits:
Activation with richer dataA data warehouse holds valuable, consolidated information that often goes untapped. Reverse ETL brings this data to life by syncing it with operational tools used by sales, marketing, and support teams. This activation ensures teams have access to up-to-date insights—such as customer behavior, product usage, or lead scoring—empowering smarter and more impactful interactions.
Enhanced personalizationReverse ETL ensures fresh, critical data reaches customer-facing platforms in a timely manner, enabling businesses to more deeply personalize experiences across channels. From tailored marketing campaigns to customized sales outreach, reverse ETL helps teams deliver more relevant and engaging experiences, boosting customer satisfaction and conversion rates.
Alignment around a single source of truthData silos lead to inefficiencies and inconsistencies. Reverse ETL addresses this issue by syncing enriched warehouse data to operational systems, providing every team with access to the same accurate information. This aligns sales, marketing, and support teams around a shared understanding of the customer.
Increased productivity for data and business teamsReverse ETL automates data delivery into business tools so business teams can use insights from the warehouse without having to file a ticket with the data team. This democratization of data accelerates decision-making and allows teams to act swiftly, and enables data engineers to focus on more valuable work.
Challenges with reverse ETL
While Reverse ETL can deliver major benefits for a business, there are a few key considerations to be aware of when considering a Reverse ETL tool:
- Data quality and consistency – Reverse ETL relies heavily on the quality of data in the warehouse. If the data is incomplete, outdated, or inconsistent, it can lead to inaccurate insights and poor decision-making. Businesses must invest in strong data governance practices to maintain data quality and ensure consistency across all systems.
- Complex business logic – Syncing data isn’t always straightforward. It may require applying complex business logic to transform and format the data for operational use. This can add complexity to the data pipeline and require constant monitoring and adjustments to ensure accuracy and relevance.
- Security and compliance concerns – Transferring data between systems introduces security and compliance risks. Sensitive information must be handled carefully with robust data privacy practices to maintain customer trust and ensure compliance with regulations like GDPR or HIPAA.
Comparing reverse ETL with other data pipeline solutions
There are many ways to move data around, which can be confusing and costly, depending on your setup. However, finding what might work best for your organization is much easier if you directly compare reverse ETL with other data flows.
Reverse ETL vs CDP
Reverse ETL and Customer Data Platforms (CDPs) can each play important roles in a company’s approach to managing and activating data, but they’re used for different purposes.
Traditional CDPs are SaaS platforms used primarily by marketing teams. They are designed to build customer profiles and make them accessible for personalized marketing and engagement. They handle data ingestion, identity resolution, and audience segmentation. Many support journey orchestration and offer customer engagement capabilities within the platform. Traditional CDPs provide powerful tooling for marketers, but they operate independently from the data warehouse, creating a data silo and restricting the broader organization's ability to use data cohesively.
A modern warehouse-native approach to the CDP eliminates data siloes by leveraging the existing data warehouse as its foundation, using the warehouse to store and unify all customer data into complete customer profiles.
In this setup, Reverse ETL becomes a crucial component, syncing customer profiles from the data warehouse downstream for business teams to use. This approach enables businesses to take full advantage of their data warehouse's power and flexibility while seamlessly delivering insights to the teams and tools that need them.
It gives data teams greater control, allows for more sophisticated data activation, and ensures that all business functions operate with consistent, up-to-date information.
Reverse ETL vs iPaaS
iPaaS (Integration Platform as a Service) connects applications, systems, and data sources across an organization, automating data flows to streamline processes. It’s a versatile solution for integrating data in multiple directions, but it doesn’t rely on a central data warehouse. It handles integration directly between various platforms, such as syncing a CRM with an ERP.
Reverse ETL is a more focused solution for customer data activation that centers on the data warehouse as the primary hub. It syncs warehouse data to operational systems like CRMs or marketing tools so business teams can use enriched, unified data from the warehouse for personalized marketing, real-time sales insights, and better customer support.
iPaaS is used broadly for operational efficiency, connecting diverse business systems. Reverse ETL is laser-focused on empowering customer-facing teams by activating and operationalizing customer data from the warehouse.
Activate your customer data with RudderStack Reverse ETL
RudderStack Reverse ETL enables companies to sync data from their data warehouse to over 200 destinations with prebuilt integrations. To see Reverse ETL in action and learn about RudderStack’s Warehouse Native Customer Data Platform schedule a demo with our team today.
Published:
November 4, 2024


Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
