Data Warehouse Best Practices — preparing your data for peak performance
Smart business practices require increasingly high volumes of data. As technology advances and your business scales, you will require increasingly advanced solutions to remain competitive in the data landscape. One of the best modern tools for maximizing the observability and analytic power of your data is the data warehouse. This article will guide you through best practices for building a data warehouse and illustrate how you can get the most value from the tool.
If you are not already familiar with a data warehouse, be sure to first read our introduction to data warehouse. To quickly review: data warehouses are high-powered repositories for collecting, contextualizing, and clarifying data from complex sources. They are designed to help you make informed business choices while retaining and distributing valuable insights throughout an organization.
As useful as they are, data warehouses don’t pop out of the box fully formed and ready to power decision making. This article will overview the steps to data warehouse development, and give you tips on keeping the implementation and design of your data systems friction-free from the beginning.
Step 0: understand your use case
Before getting started, it’s important to understand how improving the observation of your data will increase revenues or lift key metrics. This allows you to set expectations for how data warehouse design and implementation will benefit your business, set goals accordingly, and keep them in mind throughout the data warehouse development process.
A strong understanding of the fundamentals of data warehouses will help you understand how your business can benefit from a warehouse. Common reasons for developing a data warehouse include:
- Automating and expanding data analytics & data collection
- Unifying and sanitizing data from multiple, potentially complex sources
- Segmenting front-facing production from resource-intensive internal operations
- Reducing current or future technical debt with a data system designed to scale
- Expanding data access to internal teams and reducing the technical knowledge required to gain insight
In general, data warehouses increase available data insights, reducing the labor costs of those insights while increasing strategic organization to provide across-the-board efficiency boosts. You can likely find a way to apply these advantages, but it’s also worth considering other tools that you can use to accomplish the same goals. Before jumping into a data warehouse, it’s worth considering other solutions at a smaller scale (a relational database) or a larger scale (big data). You know your business best — take the time to find the right tool for the job.
Step 1: build a data model
Once you’ve decided that a data warehouse is the right tool for your business, it’s time to build a comprehensive understanding of the data that will be involved in your data warehousing project. To do this, you’ll use a data model. A data model is a document that describes your varied data sources, shows how they are connected, and illuminates dependencies. At this stage, It’s vital to capture a complete picture in modeling your data. This will lead to good database and data warehouse design, help synchronize different teams, and allow you to get the most from your data systems. Taking the time to do this well at the start will help you avoid costly retraced steps in the future.
The time you spend building a comprehensive data model for your warehouse will pay itself off several times over. By reflecting on how different datasets relate to each other, you will be able to better standardize, collate, and interpret that data. A data model should also allow you to better anticipate the expected inputs and outputs of the model — that is, the specific expectations of the analysis produced by the warehouse.
Documenting your data model has additional tangential benefits. Many people find that they gain a new understanding of the complexity of their data space while documenting their models. A solid data model can also help coworkers generate related artifacts like API documentation or sketches of marketing funnels. Even if you find you do not need a data warehouse after building a data model, you’ll likely determine that the learnings gained during the process were worth the effort.
Step 2: draw your flow diagram
A common method for rendering your data model is a format like a data flow diagram (DFD). The DFD is a high-level flowchart that allows you to record your own understanding of the data system you are instrumenting while also creating clear documentation that’s legible to non-experts.
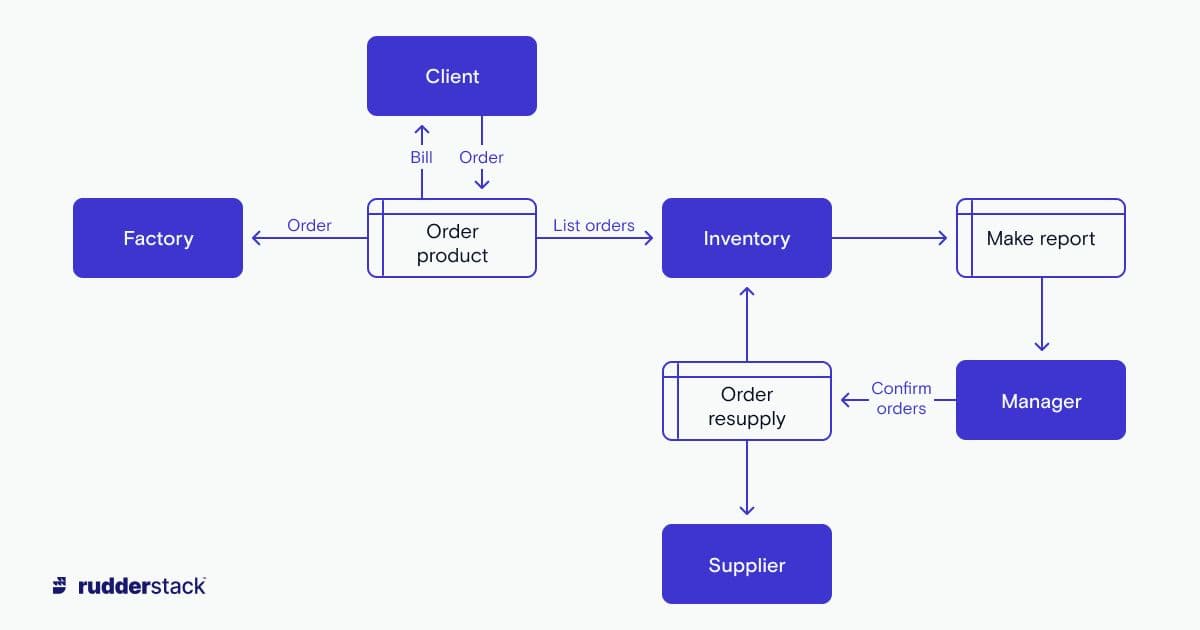
From PowerPoint to diagrams.net, there are a variety of tools for creating a DFD.
Building a warehouse also requires an understanding of potentially diverse data sources. By enumerating your inputs and their locations in the company data structure, you are preparing yourself for when the time comes to gather all those threads in the warehouse.
At the same time, visualizing the flow of data through your company enables you to design changes. One of the best practices in data warehouse design is pruning messy data flows to reduce technical debt while you are improving your data infrastructure. A DFD is a valuable step in this process. It enables you to visualize the process for yourself and helps you convince others of the benefits of retooling their data systems.
Here it is often most helpful to combine the DFD with a user flow diagram. As you map out the way users flow from various properties like websites, web apps, mobile apps, etc. you can naturally abstract customer actions into the data points they generate (e.g. signing up, using features, making purchases). This kind of diagram should also include actions taken external to the user like changes made in the CRM system by an account executive. Creating these two diagrams in tandem gives you a full picture of which user data is generated in what places.
Step 3: define the nuts and bolts of your warehouse architecture
Once you have both a good view of your data and concrete expectations of your data warehouse system, it’s time to think about the actual implementation of your warehouse. Data warehouses are an established and mature technology. As such, there are a variety of different warehouse products that provide different benefits and specializations. Below, we will outline some of the common decision points in data warehouse design that you should keep in mind as you select a particular warehouse system.
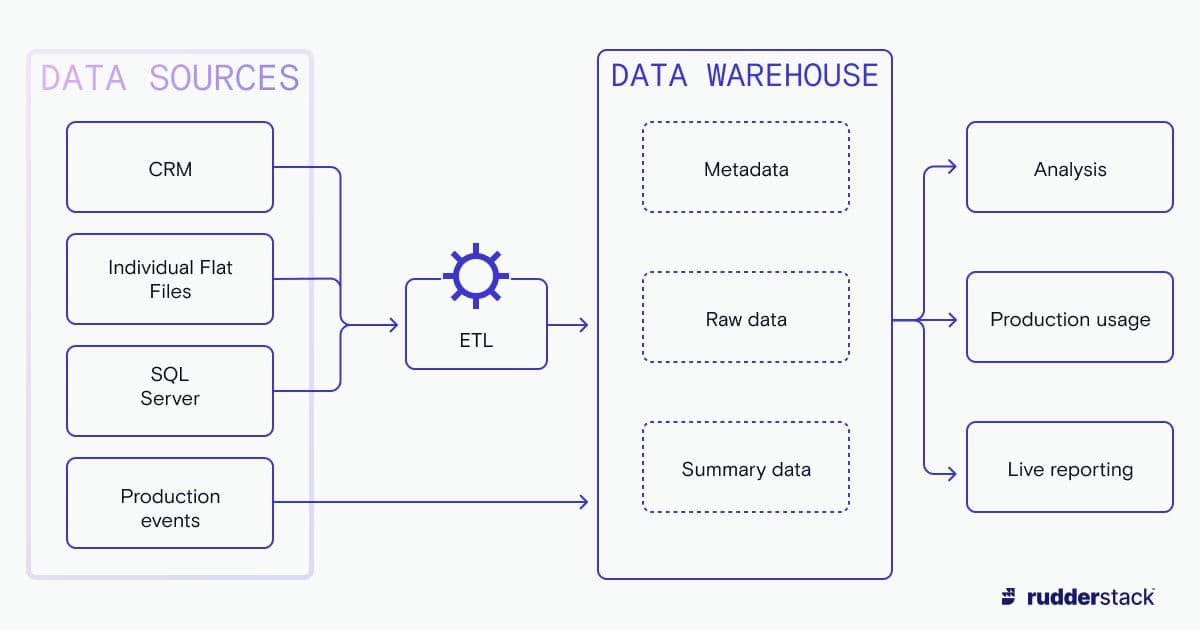
A generalized diagram of data warehouse design
Incorporating uncertainty in your integration layer
Your data warehouse starts with a set of (likely) relational databases, which are ready to be centralized into the data system. An important component of your data warehouse is the interface that funnels these diverse sources into your loading systems and eventually the warehouse. In order to cover varied data sources and scale well into the future, this integration layer should be completely source agnostic, accommodating read operations on any of your existing data sources and responding well to any data sources you could imagine adding.
ETL versus ELT — some loading considerations
Once properly sourced, data has to be sanitized and stored in your warehouse system. There are two schools of thought here: ETL (extract, transform, load) and ELT (extract, load, transform).
ETL
ETL is a more traditional version of loading. ETL transforms (sanitizes, joins, and otherwise prepares) the data on a dedicated server before it enters the warehouse and is made accessible to the data user. ETL used to be a universal standard because the computer systems running warehouse software would be too bogged down by the transformation process to operate efficiently. ETL is still useful when computational resources are limited, vast on-site resources are available, or the data transformation stage is especially computationally expensive. Additional demands for ETL come from legal requirements to protect data or any requirement that certain data should never be exposed to warehouse users.
ELT
In cloud-based data warehouses, ELT is the preferred loading system. Loading data into the warehouse first and then doing transformations on the fly makes the warehouse more responsive and flexible to the end user. ELT does have higher computational costs, but due to massive increases in scalable cloud technology, it’s increasingly possible to accommodate ELT pressures in modern warehouse systems. For users with neither on-site resources nor unusual transformation demands, ELT is usually a better approach to loading.
Data deployment and resources
Like the split between loading procedures, it’s also important to consider the resources you have available for deploying and maintaining your warehouse. Different cloud data warehouse providers offer different levels of customization which in turn require different levels of technical expertise to set up and manage. For example a more hands on Cloud Data Warehouse, such as Amazon Redshift, requires more technical expertise but lets you customize everything from compute and storage types down to the query scheduler itself. A more fully managed solution, such as Snowflake, requires less technical expertise as you only have to decide how much compute you need at what time. At the far end of this customization / skill spectrum, a cloud data warehouse like Google BigQuery requires no capacity or compute configuration at all. With BigQuery you simply have a certain cost associated with each GB stored and each second of query execution time used. While some companies may require on-site data warehouse solutions, which afford the highest level of control over data security, cloud solutions are secure, easier to implement, and offer a more flexible approach for most organizations.
Step 4: researching your data warehouse
Now is a good time to review your data model, consider who the end users of your data warehouse will be, and think about the different systems it will need to integrate with. When you begin researching different warehouse vendors you should broadly consider the following things:
- Data visualization: If you have BI or dashboard tooling in mind, you’ll want to ensure the warehouse candidate supports the tool.
- Feature sets: Be sure to consider whether or not the warehouse has all the features you require. For example, do you require data lake, data modeling, or machine learning (ML) functionality in your warehouse, or do you use external tooling for that?
Pricing models: Consider storage vs. compute costs. Pricing models can vary depending on your loading frequency and volume, and on how much compute power is required.
Diving deeper into data storage
Applying data warehouse best practices is one thing, but understanding the complex and ever-updating landscape of data storage technology is another. Be sure to stay up to date with other articles from our learning center: