RudderStack's Data Stack: Deep Dive


A few months back we started an introspective series of blog posts highlighting how we use RudderStack internally (affectionately titled “Dogfooding At RudderStack”).
Because we routinely meet with customers who ask us for recommendations regarding one facet or another of their tech stack, or how they should go about building or augmenting their stack, we thought it might be helpful to take a deep dive into how a mid-sized SaaS provider might approach getting the right data to every team through cloud tools like Salesforce and more complex use cases like analytics on top of Snowflake or live enrichment via external APIs.
In this post we will use a sample funnel to outline the data, then dig deep into how we use RudderStack ourselves to connect all of the pieces of the stack. Last but not least, we’ll show you how we leverage the combined data in the warehouse to drive analytics and enrichment.
Dessert first: valuable dashboards
Typically in these posts we like to get into the technical guts of the matter as quickly as we can because, after all, we are data nerds and building world-class software is what we do. For this post, however, I’d like to come at it from a different angle. I’d like to start with one of the most valuable outcomes that results from a well-designed data structure and stack: the reports. Valuable dashboards that help drive clarity in business decisions are achieved through the combination of a clear business strategy, accurate data and thoughtful infrastructure execution—they aren’t an afterthought. For many companies, though, they are still an aspiration.
Once the business strategy is crystallized, a successful stack design must meet all of the requirements of the stakeholders, which include analysts, functional team leaders and the C-suite who rely on accurate reports to make strategic decisions about how to run the business. And, of course, the same data is acted on by the marketing and sales teams.
One of the best ways to architect a stack is by designing the data map first (just ask the folks at WaveDirect, who increased their leads 4X). That means designing your funnel (or what you believe to be your funnel), defining the questions that need to be answered at each stage, and then mapping the data points needed to answer those questions. Those are the essential ingredients of good reports. With that foundation, it’s much easier to build a roadmap for all of the various components of the data stack.
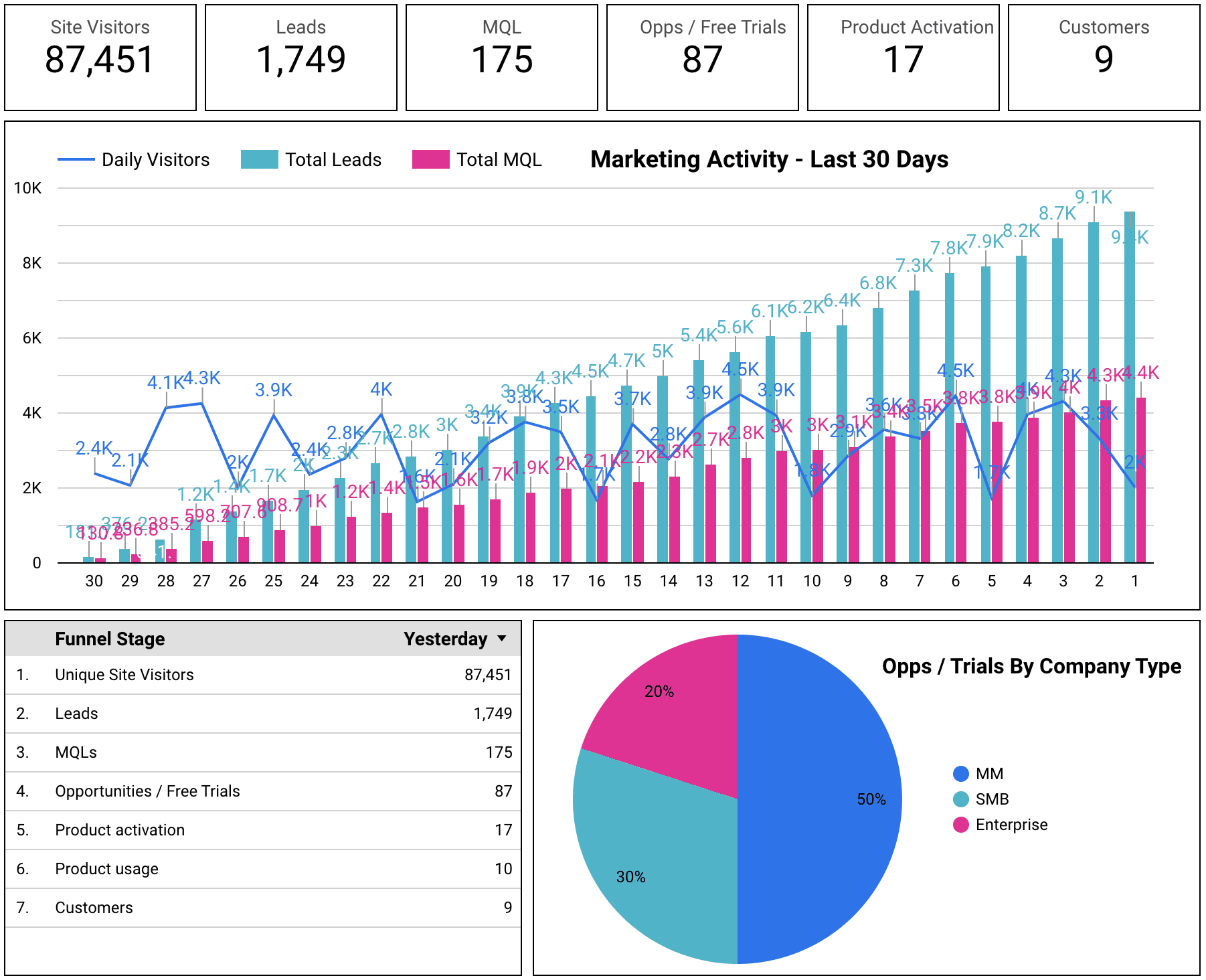
For example, here is a typical dashboard snapshot you might find at an early to mid-stage SaaS company. It provides an immediate view of the key KPIs in the marketing and sales funnel and allows stakeholders to quickly evaluate performance and identify both problems and opportunities. The metrics align with the teams’ daily, weekly and monthly objectives and represent stages and segmentation within the funnel.
Even though this dashboard seems simple, many companies struggle to combine their data to produce a basic, accurate dashboard like the one above.
In our stack, every bit of data in our reports runs through RudderStack (as you would expect), from behavioral data (website and product) to lead intelligence data pulled in from Salesforce and external APIs. But before we get into the technical details, let’s quickly show you how to map out the funnel and design your data.
Defining the funnel and designing the data
Looking at a high-level funnel rarely causes disagreement, but designing data means making explicit definitions, which are often hard to nail down across teams and are subject to change as the business grows. Even something as simple as defining new leads brings up questions like “do we count all new signups as leads even if they are from the same account?” These dynamics often mean that marketing and product report a different number for signups, but they are both right because they are using different definitions. Mapping your funnel helps drive clarity.
For this exercise, we’ll map a sample funnel and apply sharp data definitions to provide context for the walk-through of RudderStack’s stack.
Every business will have a slightly different funnel depending on their structure and strategy—a self-serve company will have a different customer journey than one pursuing top-down enterprise sales. In this example, we’ll use a basic funnel that includes customer journey steps common to most B2B SaaS businesses.
| Stage | Daily Target (Volume) | Conversion Rate |
|---|---|---|
Unique Site Visitors | 70,000 | 2% |
Leads | 1,400 | 10% |
MQLs | 140 | 50% |
Opportunities / Free Trials | 70 | 20% |
Product activation, PQLs | 14 | 50% |
Customers | 7 | 120% |
Product usage | 8.4 |
Let’s look at each step, one by one, and point out the common challenges companies face in delivering data that will drive real insights.
Unique visitors
Unique site visitors is a metric commonly reported directly from Google Analytics, but even extracting the GA data into our warehouse (which is extremely expensive and slow) will not provide us the user-level view of our data that we want to fully understand complex user journeys and performance of various cohorts. Also Google Analytics drastically under-reports data. As an alternative, we send RudderStack page calls from all of our web properties to collect step by step data points for each user’s browsing behavior. As a first step in our data design, we can count distinct users (anonymous and known users) across all page events and exclude our internal IP ranges.
Leads
Tracking leads sounds easy, but as anyone in a modern business can attest, there are many exceptions to the rule. Here are just a few of the challenges companies like ours face:
- Exclude not only internal users (via IP ranges & @rudder domains) but also our existing customers, industry partners, vendors, etc.
- Only count a lead once from the same company/account/domain but still differentiate between marketing attribution touchpoints and account mapping
- Incorporating lead and/or account intelligence that lives in other cloud tools (i.e, opportunity stages in Salesforce or opt-out statuses in Marketo)
To solve these challenges, many companies try to apply filters to report feeds, but this becomes cumbersome and requires an engineer or analyst to manage, meaning a growing body of painful work over time, because there are always more exceptions to the rule. We’ll dig into details below, but to give you a taste, at RudderStack we maintain a master exclusions list in Google Sheets, which we pull into our warehouse via ETL. We also add a domain rank for each lead, which allows us to easily deliver data that serves multiple teams, i.e., domain rank 1 for marketing vs. all signups by account for product. On the enrichment side, we leverage Transformations and external APIs for real-time enrichment and Reverse ETL for lead and account intelligence enrichment.
Lead qualification & product activation (MQLs, PQLs, etc.)
Lead qualification requires multiple disparate data points from marketing conversion type to account intelligence to product usage data. Pulling all of this information together is hard and many companies solve this with brute-force manual scrubbing, which isn’t scalable. The warehouse is the easiest and best place to do this work, and we recommend implementing the logic in dbt for flexibility and extensibility, especially as definitions change. At RudderStack, we use Reverse ETL to push the enriched results from our dbt models to all of our cloud tools, like Salesforce.
Opportunities, free trials, POCs, etc.
For many SaaS companies, Salesforce holds critical information about the status of opportunities, accounts and customers. Unfortunately, this is often trapped in Salesforce, meaning other reporting and other cloud tools, like marketing automation systems, don’t have access to the data. The best way to solve this is to pull the Salesforce data into the warehouse and create flags for the important statuses. At RudderStack we push these flags back to the stack using Reverse ETL, but you can also do it in real-time by hitting a RudderStack Webhook Source from Salesforce and sending a real-time identify call.
Bringing it all together
So, now that we have each stage defined and an understanding of the data we need at each step, let’s dive deeper into exactly what data elements will need to be created and tracked to produce our funnel. It may sound a little counterintuitive to think about specific data properties at this stage, but this is the best way to ensure we’re collecting the right data from the right source at the very beginning. And for those of you keeping score, yes, this exercise builds the foundation of your tracking plan.
Click here to learn more about our Tracking Plans beta, or check out our Data Governance API to help enforce these policies.
| Funnel Step | Data source | System of Record | Example metric definition | Comments |
|---|---|---|---|---|
Visitor | RudderStack JavaScript SDK | Snowflake | Count of Distinct Anonymous ID | Aggregated from all Page events |
Lead | RudderStack JavaScript SDK, RudderStack Node SDK, & RudderStack Webhook Source | Snowflake | Count of Distinct Email Addresses where exclusion is null and domain rank = 1 | We could also use Rudderstack User ID from the Identify Call as this is the same value |
MQL | Salesforce, Snowflake & dbt | Salesforce | Count of Salesforce Leads (not deleted) with MQL checked where exclusion is null and domain rank = 1 | Exclusion and Domain Rank are picked up from the snowflake table |
Opportunity / Free Trial | Salesforce | Salesforce | Count of Opportunities (in their various stages) where Opp Type = Initial | |
Product Activation | RudderStack JavaScript SDK, RudderStack Node SDK, RudderStack GO SDK | App | User has performed X and Y behaviors (for RudderStack, user has created a connection and sent data) | Indicates whether the user has done something to stream data |
Customer | Salesforce | Salesforce | Opportunity = Close Won | |
Product Usage | RudderStack JavaScript SDK RudderStack Node SDK RudderStack GO SDK | App | Total count of Z data points (for RudderStack, total event volume) |
Ok, we’ve mapped the funnel and defined the data with clear definitions, sources, and systems of record. Now it’s time to dive into RudderStack’s stack and show you how we use our product to drive the data for a funnel similar to the one above.
RudderStack’s stack
Believe it or not, with RudderStack and Snowflake at the center of the stack, defining the funnel stages, metric definitions, and sources of truth was the hard part.
Built on our warehouse-first approach, the spine of our stack consists of RudderStack at the core passing events to Snowflake, cloud business tools like Salesforce and Customer.io, and analytics tools like Google Analytics and Mixpanel. We also utilize Webhook Sources and destinations for a number of things, like streaming events from Salesforce for real-time enrichment.
Here’s a visual map of our actual customer data stack:
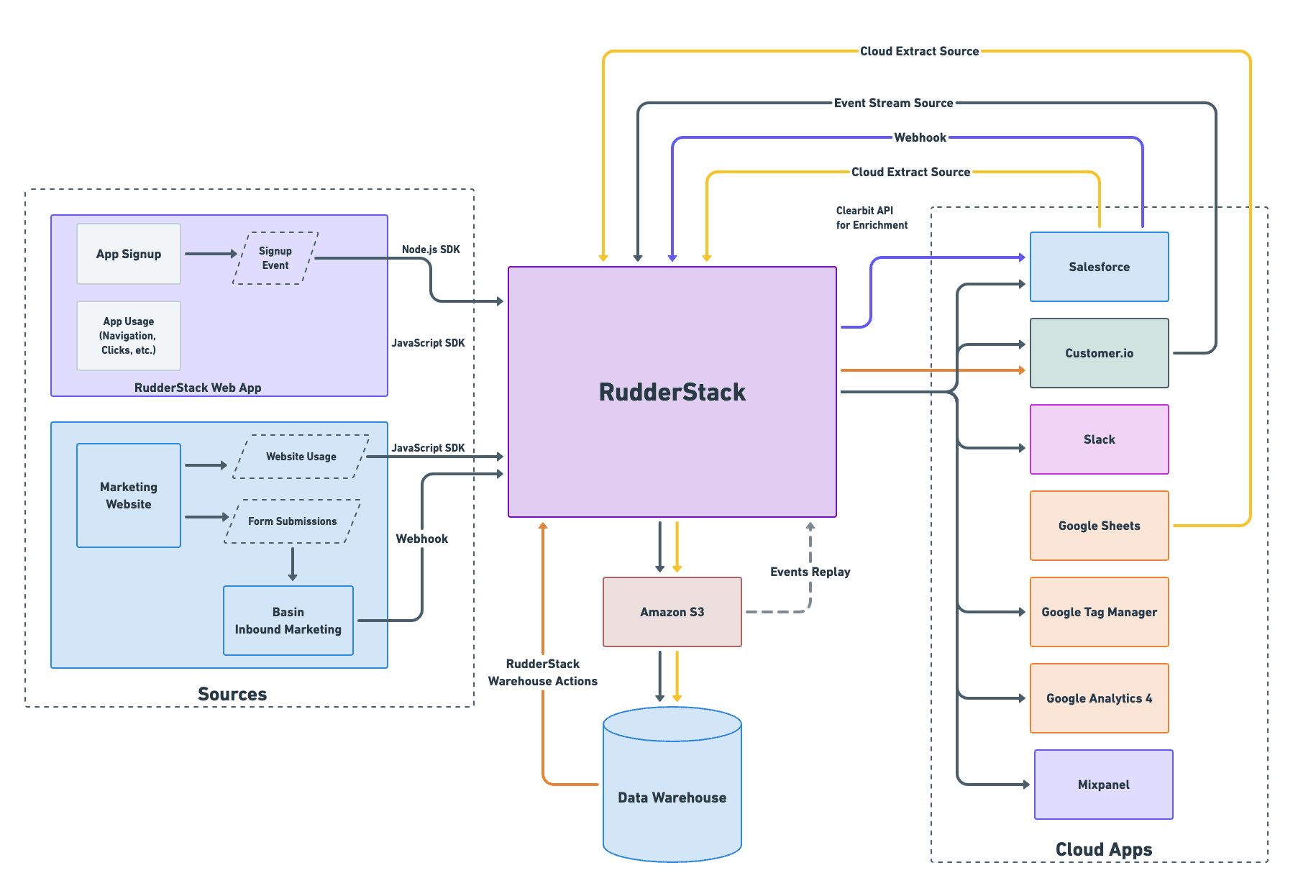
One thing to note is that with the core in place, almost every component of the stack can serve as both a source and destination for data. In fact, when companies or teams are choosing between customer engagement and sales tooling options, we recommend those with the ability to receive and send event data, though often you can achieve the same functionality with Webhooks and a few lines of code. This creates powerful ‘feedback loops’ for event data, like the ones you see in the diagram above with Salesforce and Customer.io. And, of course, we recommend pulling in structured batch data from cloud tools.
Storage
Our warehouse-first data stack is built around a Snowflake cloud data warehouse. We also send a copy of all data to S3 for object storage.
Marketing
Data collection
Let’s start at the top of the funnel. We’ve written in the past about how we use Sanity.io to drive our Gatsby website. (For those keeping score, we deliver the site via Netlify, which we love.) All behavioral data from the site is collected via the RudderStack JavaScript SDK, which is a Gatsby plugin. They also track app signups through the RudderStack Node SDK.
Another tool we use on the marketing site is Basin, which acts as a back-end form submission handler that isn’t susceptible to client-side browser blockers or JavaScript errors, meaning we capture leads no matter what. Basin routes data to a RudderStack Webhook Source.
Cloud tools
In terms of non-analytics cloud tools, the marketing team keeps it pretty simple, using Customer.io to send emails and drive behavior-based customer journeys.
Marketing platforms
The marketing team also sends conversion data to several marketing platforms like Facebook Ads and Google Ads. Where possible, they prefer sending server-side conversions so that they don’t have to add weight to the website with additional JavaScript.
Alerts
The marketing team sends alerts for new leads into a Slack channel using the RudderStack Slack destination and leverages a Transformation to filter out unwanted noise.
Product
This post is about the customer data stack, so we won’t dig into how our product team uses RudderStack in the development lifecycle. On the customer data side, the product team runs an almost identical setup to marketing for collection, using a variety of client-side and server-side RudderStack SDKs that feed the warehouse, product analytics tools and alerts via Slack.
Sales
As you’d expect, our sales team lives in Salesforce. Because we already capture all new leads and signups, sending the data to Salesforce is as easy as adding it as a destination to the marketing site and app SDK sources. One important note is that we always send leads and signups from server-side sources to ensure we never miss leads due to client-side issues or script blockers.
Enrichment
For real-time enrichment, we use the Clearbit API, which we hit via RudderStack Transformations. This ensures that the sales team has enriched lead records in real-time.
We also do batch enrichment with data from our own stack. We pull in structured data from Salesforce and email engagement data from Customer.io, then combine it with behavioral data from the marketing site and app to build lead and account intelligence. We then use Reverse ETL to push the results back to Salesforce and Customer.io so that the marketing and sales team can take action on the most relevant data.
Analytics
Because we have all of our data in Snowflake, it’s the most logical and elegant foundation for rich, accurate reporting on key business KPIs across functions. All of our modeling and logic live in dbt and drive key KPI dashboards in Looker for marketing, product and the executive team.
The marketing team also uses several additional analytics tools that are destinations in RudderStack:
- Google Analytics for high-level web stats (which they compare with Netlify analytics...more on that in an upcoming post)
- Mixpanel for user journey mapping and funnel analysis (time to value is way faster than trying to build user journey reports from scratch in SQL)
- HotJar for heat mapping and session recording
The sales team does reporting in Salesforce, which is made more powerful and useful with the enriched data delivered from Snowflake via Reverse ETL.
The product team uses a combination of Looker and Amplitude for product analytics.
Connecting the stack
As we said above, we use our own product to make all of the data connections. Once sources are set up, adding, removing, or testing new destinations is as easy as adding credentials, which the marketing team loves, but our data engineering team loves even more.
Below is a detailed breakdown of the connections needed based on the above components of the stack. Note the number of connections required to run a fairly simple customer data stack like ours.
| Source | Type | Transformation | Destination |
|---|---|---|---|
Marketing Site - Gatsby | RudderStack JavaScript SDK | Customer.io Transformation; Slack | S3 Google Analytics; Google GTM; Customer.io; Snowflake; Facebook Pixel; Slack |
Basin Inbound | Webhook | Ignore Rudder Emails (L); Salesforce (L); Customer.io Transformation; Slack | Snowflake Salesforce Customer.IO Slack |
RudderStack Application | RudderStack JavaScript SDK, RudderStack GO SDK | Google Analytics; Customer.io; Snowflake; Amplitude | |
Server-Side App Signup | Node (Server Side) | Ignore Rudder Emails (L); Salesforce (L); Customer.io Transformation; Slack | Salesforce; Customer.io; Snowflake; Slack |
Salesforce | Cloud Extract | Snowflake | |
Salesforce Webhook | Webhook | Clearbit API for Enrichment; Ignore Rudder Emails (L); Salesforce (L) | Salesforce |
Google Sheets (UTM Tagger; Email Exclusions List; Marketing Conversions) | Cloud Extract | Snowflake | |
Snowflake | Warehouse Action | Customer.io Field Consolidation | Customer.io |
(L) Designates a Transformation Library, where the same transformation code is imported from the library into individual transformations, making it simple and extensible to apply the same transformation across multiple destinations.
Here’s what a setup like this might look like in the RudderStack UI. You can see the warehouse-first approach: Snowflake is a destination for every source.



Data quality: instrumenting tracking plans
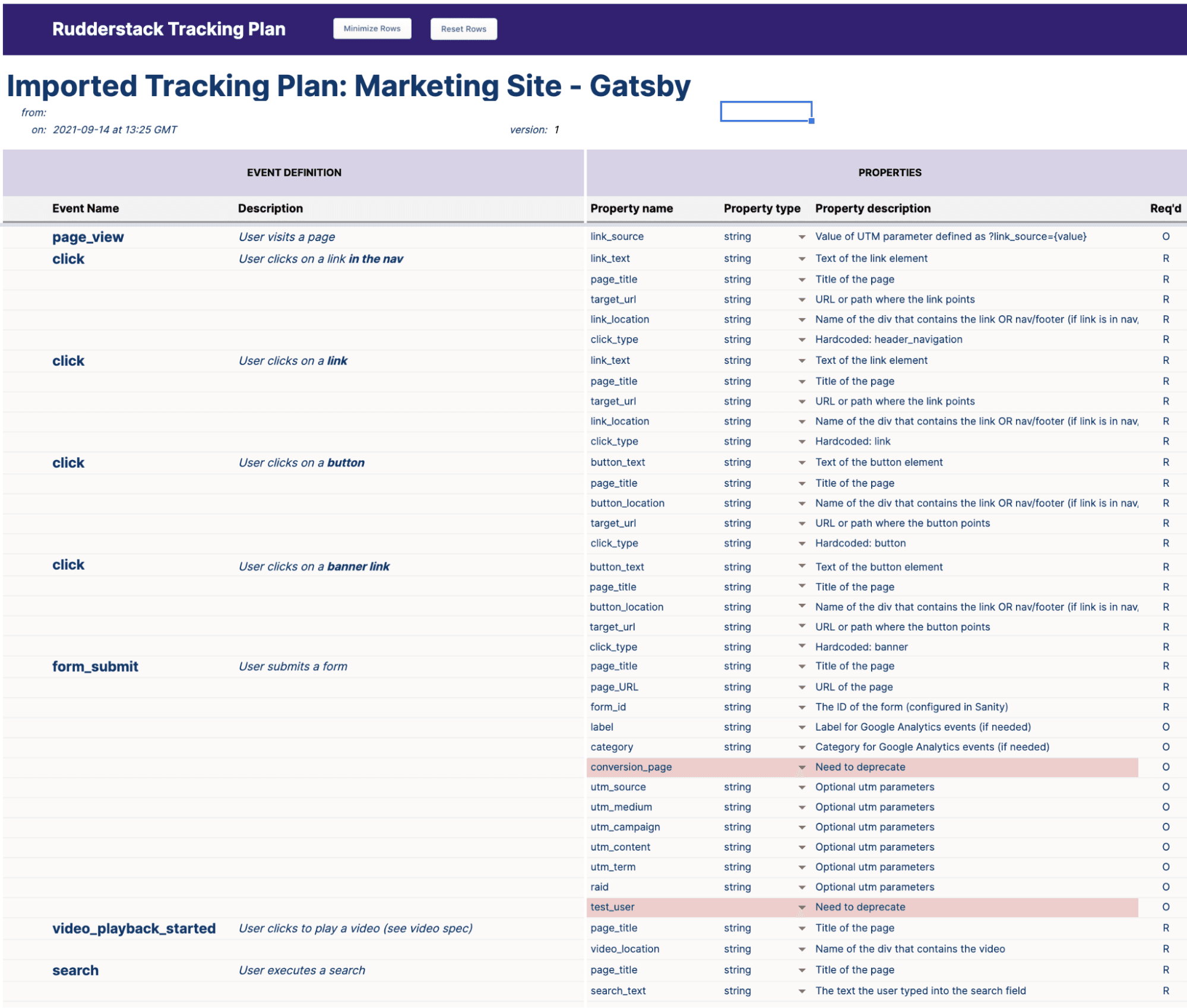
With the funnel, data, and connection requirements defined, it now makes sense to spend time creating a Tracking Plan for each source to ensure that we collect clean, quality data. You can read all about RudderStack Tracking Plans here, and even if you decide not to upload them into the app, having this event dictionary will benefit all of the teams involved with increased clarity and consistency. The output of this exercise will create a concise list of events and properties for each of your sources, which will greatly reduce confusion throughout the life of the stack.
Here’s an example of what a RudderStack tracking plan might look like:
Fine tuning data with transformations
Like our customers, we love the Transformations feature of RudderStack and its ability to edit the payload prior to it reaching downstream destinations. As any data engineer knows, regardless of how well you plan your data in the Tracking Plan and collaborate with engineers, web designers, app developers, etc., there are constantly tweaks that need to be made to data in flight, often because of issues or limitations in downstream cloud tools.
User Transformations allow destination-specific tweaks for specific downstream tool needs, the enrichment of data, masking or stripping of PII, etc. As we said above, Transformation Libraries make it easy to run the same code on multiple destinations.
Of course, we always recommend sending a copy of the original payload to a data lake like S3 to maintain a copy of the raw data and give you flexibility for event replay or event backfill (which can be incredibly useful when implementing a new analytics tool, for example).
If you have any ideas for cool Transformations or need help with a user Transformation in your organization, please hit us up on the support channel in slack. (Join us on slack if you haven’t already).
Warehouse-first data modeling
As simple as it sounds, one reason we are so bullish on architectures that build the CDP on the data warehouse is that having all of your behavioral and structured data in one place, with defined schemas, allows you to build analytics and derive insights that simply aren’t possible any other way.
Note that when sending events to a data warehouse via RudderStack, you don't need to define a schema for the event data before sending it from your source. Instead, RudderStack automatically does that for you by following a predefined warehouse schema. For specifics on exactly what tables are created per your warehouse destination, check out our Warehouse Schemas Documentation.
For ETL sources, we also provide defined schemas, which you can see by source in the docs.
Our data schemas
Digging in a little further, let’s revisit the table we created above to define our funnel stages along with the Rudderstack sources, but this time focus on the warehouse schemas and SQL required to aggregate the data and form the foundation of analytics and enrichment on the warehouse.
| Funnel Step | RudderStack Source | Events / Tables | Comments |
|---|---|---|---|
Site visitors | Marketing Site - Gatsby ( RudderStack JavaScript SDK) | Page | Aggregated from all Page events |
Leads | Basin Inbound Server Side App Signup (RudderStack Node SDK); Email Exclusions List (Google Sheets via Cloud Extract) | Track (form_submit, user_sign_up) Identify Cloud Extract Table | Form submits and app signups generate leads. We fire track calls for the behaviors and identify calls to create users. |
MQLs | Salesforce | Cloud Extract Table | |
Opportunities | Salesforce | Cloud Extract Table | |
Customers | Salesforce | Cloud Extract Table |
Site visitors
In the warehouse, unique visitors to the site are tallied by distinct anonymous ID. If we were using multiple schemas or databases, we could easily modify this script. In addition, we segment this data by page, referring URL and other data points as needed by the marketing team.
JAVASCRIPT
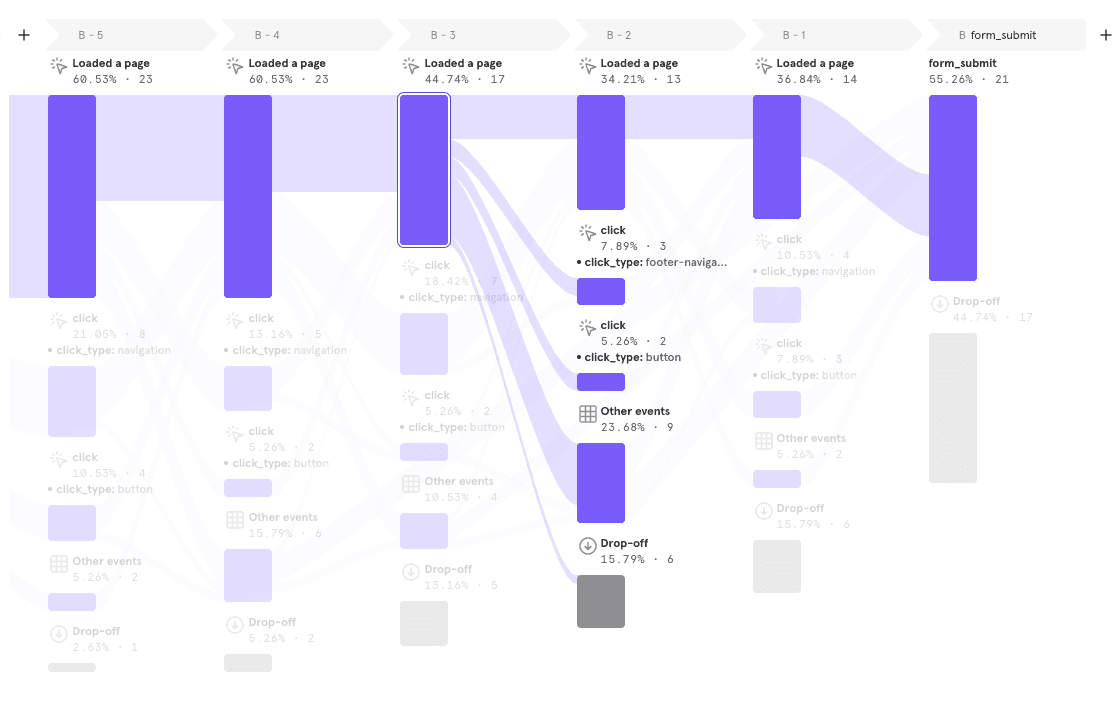
It’s also worth highlighting how Mixpanel fits into our analytics toolset. While the warehouse and Looker are excellent for comprehensive data, accuracy and flexibility, it requires a significant amount of SQL to build more complex reports like user flows and funnel analyses. Mixpanel has robust journey reporting, and because we can send our event stream data directly to the tool, the marketing team has instant access to those reports.
Here’s an example of a visualization that would require tons of work in Looker, but is instantly available in Mixpanel with the same data:
Leads
Counting Leads is a little more complicated because we have to exclude users for a number of reasons. While we might use a RudderStack User Transformation to prevent internal email addresses from being loaded into our production Customer.io and Salesforce instances, we don’t restrict those events en masse from going into Snowflake and S3 (for testing, etc.). Instead, we created a Google Sheet shared amongst the team with email addresses or domains and an exclusion reason. This way, instead of not reporting a lead, we flag it with an exclusion reason and filter report models based on these exclusions.
Also, the marketing team’s primary view looks at the very first lead to come in from an account, which ensures they don’t over-count (i.e., multiple signups from the same company) and can maintain clean first-touch attribution by account. We assign a domain rank to each lead by account to drive those metrics.
JSX
It’s also worth pointing out that we could simply use the USERS table created by RudderStack and compare that to our list of exclusions and this would result in the same output. The approach above could be expanded to include multiple schemas and also lets us define first touch, last touch, etc. for better attribution tracking.
MQLs
This is where unified warehouse data makes the difference. Now that we have defined our clean set of leads by removing exclusions and assigning domain rank, determining which of those constitutes an MQL involves connecting the behavioral dataset above to the Salesforce leads table we pulled in via RudderStack ETL.
JSX
Note: the output of this query is a set of leads and not an actual number. We will use this table as the seeding table for Looker and apply the final tallying in the charts themselves.
Opportunities & customers
Both Opportunities and Customers use the same type of mapping defined in the SQL above to derive MQLs. Note that in reporting on these metrics, we’ve actually transitioned from marketing data (i.e., website visits) to sales data, “traversing systems” entirely. With all of our data in the warehouse, though, that happens seamlessly.
dbt for the win
As we’ve written previously, we are big fans of dbt and the team at dbt Labs. We leverage the cloud version of dbt to create and share models based on the SQL components above. These jobs run on a nightly basis to create tables in a designated dbt_ouputs schema within the warehouse. The tables are then loaded into a small set of Looker models for analysts or team leads to create charts and dashboards.
Conclusion
While there is no single prescription or one size fits all data stack, we do hope we’ve highlighted how using RudderStack and a warehouse as the core of our own data nervous system provides us the platform for building a robust and scalable solution that makes life easier for our engineers and data engineers and provides every team with the data they need to drive the business forward.
If you would like to learn more about how RudderStack can support your business, please join us on Slack or connect with us at sales@rudderstack.com.
Published:
October 21, 2021







