Blog
Exploring data activation: What it is and how to use it
Exploring data activation: What it is and how to use it

Soumyadeb Mitra
Founder and CEO of RudderStack

Eric Dodds
Head of Product
23 min read
December 13, 2024

Data activation is a hot new term in the world of data engineering and data science. As is often the case with hyped terms in our fast-moving space, there is some confusion around it. In this post I’ll provide some clarity, looking specifically at how data activation relates to data and engineering teams. I’ll also provide a guide that covers different data activation workflows and when to use them.
Watch the video on data activation and the data activation lifecycle.
What is Data Activation?
The definition of data activation is simple. Data activation is the execution of business activities that are informed and fueled by data. The goal of data activation is to improve business outcomes. The cause of the confusion around the term is its close link to data delivery.
Data delivery involves sending data from some source into the systems used by business teams like marketing, product, and customer success for data activation. With the proper data in their tools, teams can build business use cases to achieve outcomes like reducing churn, increasing conversion, or prioritizing lists of customers. Data activation, then, is best thought of in the context of a larger process, which we call the data activation lifecycle, that accounts for all of the engineering work required to make data activation possible.
The enormous quantities of data that businesses gather can easily end up unsorted and unused. With data activation, data is actively inventoried and used to help teams make decisions that lead to more engagement, more sales, and greater efficiency.
Note that an across-the-board commitment to data activation should ensure that workers are never passed data with no clear actionable value. They should only receive analyses that can meaningfully help them work more effectively.
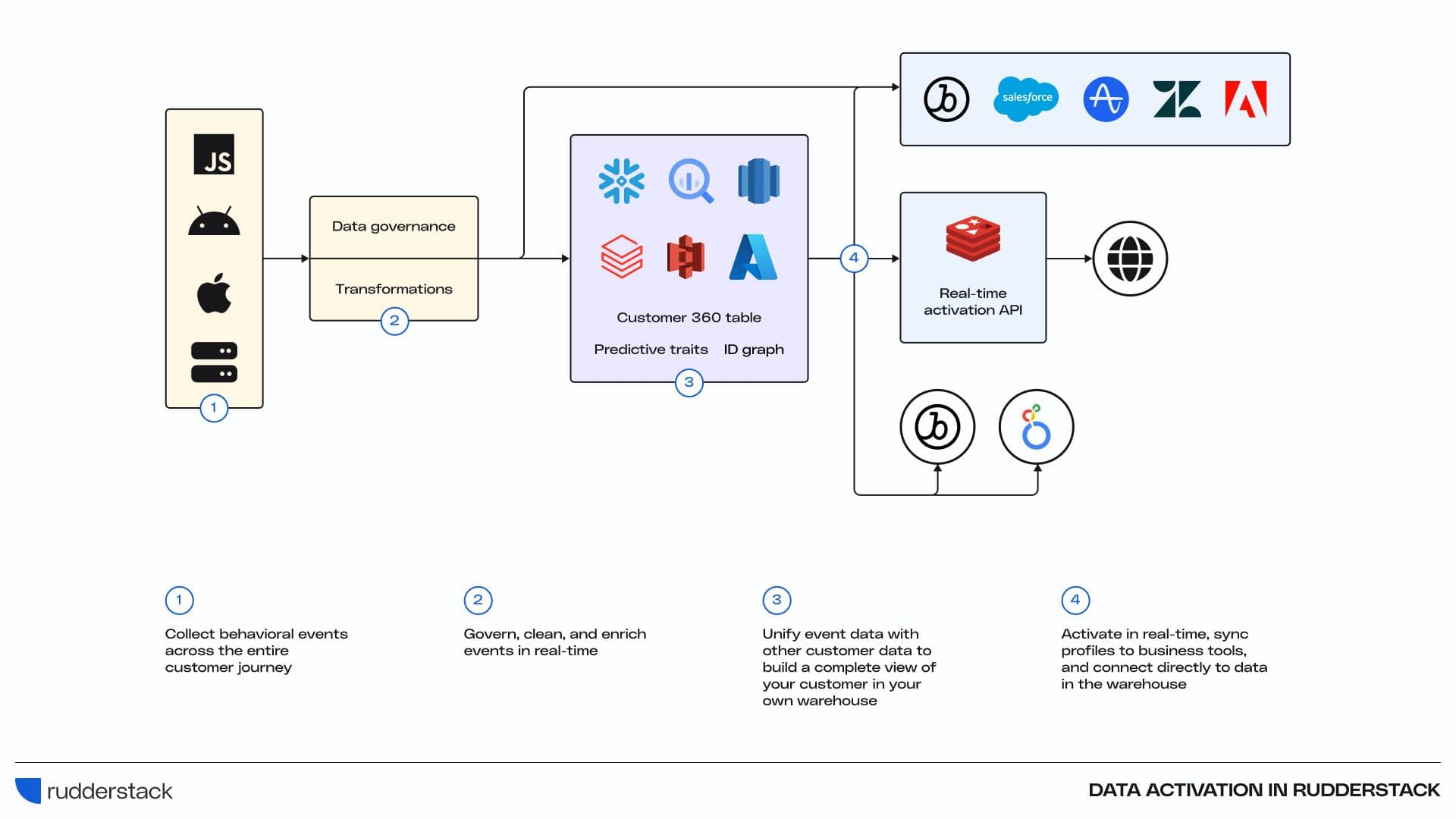
RudderStack gives data teams a tool to enable multiple data activation workflows a single platform
A brief history of data activation
Before the advent of cloud data warehouses and data lakes like Snowflake, Redshift, BigQuery, and Databricks, most data teams weren’t building many data applications beyond analytics. On-prem warehouses like Teradata didn’t scale well, and building on systems like Hadoop (whether on-prem or cloud) required substantial engineering effort, so only large enterprises were investing in advanced data applications and data management platforms to drive use cases.
Furthermore, big enterprises that did invest in building advanced data applications typically ran them on-prem behind VPNs and cloud firewalls, making it extremely challenging to connect to the applications from the outside.
The early 2000s also saw business systems, like marketing automation platforms, CRMs, and ticketing systems, start moving to the cloud, resulting in even more engineering work to get on-prem data into SaaS applications. Many companies were forced to use time-consuming, manual, and error-prone processes to export data from data systems and into the SaaS systems that business teams used.
Some enterprise companies still feed marketing with CSV files that represent customer segments today. This is inefficient, creates a significant data silo problem where each SaaS tool has a different, limited view of the customer, and forces business teams to use painful ‘direct’ integrations between SaaS platforms.
The advent of easily scalable, modern cloud data warehouses changed things. Many companies, even startups, began to use them to collect and process data, and to build data applications for use cases like LTV and lead scoring. Furthermore, because they run on the cloud, it was easier to connect them to all kinds of data sources, allowing for the breakdown of data silos and centralization of customer data.
But once the data was collected, it still needed to be moved from the warehouses into the business tools. While some teams built custom pipelines, systems like CRMs (Salesforce) and customer engagement platforms (Braze) rolled out tools for connecting directly to cloud data warehouses and managing the data there. A new software category called Reverse ETL emerged to facilitate this data movement and replace custom data pipelines, and entirely new types of systems were built specifically to run on data warehouses.
The innovation around the cloud data warehouse came as digital commerce exploded and unlocked the potential for companies to drive value at an unprecedented scale by leveraging customer data. However, the new connections that enabled business teams to quickly and easily build out high-impact use cases have also created higher expectations for data teams to drive business outcomes.
Moreover, the costs of modern data infrastructure can scale quickly. We have spoken to customers who were spending $1M for on-prem data warehouses and, after moving to the cloud, are spending 2-5x more.
There’s no doubt that the user experience is better, analytics are delivered faster, and business teams can be supported more efficiently and effectively, but CFOs want to see demonstrable justification for the increased investment. So, let’s consider the many ways data activation can benefit your business and the different approaches you can use to prove ROI.
How can data activation benefit your business?
Using your business data more effectively is obviously advantageous, but how can it specifically help take your business to the next level? Here are some key benefits to consider:
Reduce guesswork and risk
Data activation provides data-driven insights that empower teams to replace assumptions or gut feelings with informed decisions.
Workers can make informed decisions that take real trends into account and align with business objectives. With reduced reliance on intuition, teams minimize the risk of mistaken impressions leading the company astray.
Improve targeting and personalization
Effective targeting is tough to achieve, and throwing vast quantities of data at the task doesn’t help if the workers responsible can’t trim the data to find the key points.
Data activation highlights the most important takeaways, keeping them accessible for decision-making and helping creatives to streamline their efforts and deliver stand-out content without needing to pore over countless metrics.
Decrease reliance on manual reports
There’s often a disconnect between those who gather data and those who need to use it, and asking the former to create usable reports from raw collected data consumes valuable time and effort.
Prioritizing data activation eliminates the need for manual reports. Instead, teams can access insights on demand as data activation pipelines feed data directly into downstream tools.
The result is a smoother workflow with reduced use of human resources.
Identify crucial customer insights
Not all data-driven insights have an equal impact. Sometimes acting upon one particular takeaway can achieve more than acting upon tens of others.
Activated data provides a 360-degree view of customer actions and patterns, allowing the most effective insights to shine through. Marketers and sales professionals to implement remarkable improvements.
Enable real-time responsiveness
Speed of response matters a great deal, especially in industries that have to deal with rapidly changing trends and product prices.
Having activated data deriving insights from real-time metrics makes it possible for marketers to swiftly launch responsive campaigns and gives sales reps opportunities to contact prime leads before they’re reached by competitors.
Acting first doesn’t guarantee results, but it certainly makes them easier to achieve.
Optimize business-wide impact
Finding a way to squeeze a slight uptick in optimization for one department is valuable enough, so consider the value of doing that for every department.
All departments, regardless of their goals, benefit when they consistently receive data-driven insights, and that’s exactly what data activation was designed to achieve.
A guide to data activation
There are many different data activation workflows and various ways you can set up the different workflows. In this section, I’ll cover the different methods you can use and when to use them.
Note: while reverse ETL has become synonymous with data activation because of marketing from some reverse ETL vendors, this is a misnomer. Reverse ETL tools provide pipelines for data delivery from your warehouse into business tools—one of the important data activation workflows I’ll cover below.
This is just one workflow, though. In many cases, data activation does not require reverse ETL, and, in fact, a survey about data activation confirms that over half of people believe data activation is running data-driven campaigns, no matter how the data is delivered or what the destination is.
Activating first-party data from websites, apps, and server-side systems
First-party user behavior data is valuable for teams companywide. It can be used to fuel analytics as well as use cases for data-driven marketing, product, and customer success teams. Consider a simple user sign-up. After this event, the marketing team will want to send a welcome email and trigger other marketing campaigns, the product team will want to track adoption, and the customer success team will want to assign the user/account to a rep. First-party data collection is a critical piece of data activation for this cohesive customer experience.
There are multiple ways to implement this data activation flow:
Custom code → single SaaS API
In this setup, developers write custom code that sends data from their website or app to an API endpoint provided by the SaaS tool. While this gives engineers ultimate flexibility, integration maintenance becomes a major burden over time, creating low-value data activation work, especially as tools are added and APIs are changed/updated.
Single SaaS SDK/embed → single SaaS platform
In this setup, you embed code from the SaaS tool used for data activation in your website or app and that code sends data directly back to the tool.
Sales and marketing tools often provide embeddable forms that collect submissions and create users/leads. Analytics tools provide their own SDKs that send data into reports and dashboards. More modern platforms like Braze offer a combined approach, where their SDK can both create new users and capture granular user behaviors.
The challenge with this approach is that embedding tons of third-party code in your app or website slows things down. It also perpetuates issues with data silos because the data is not being centralized and is sent to each system separately.
Single SDK (CDP) → multiple SaaS platforms (one-to-many)
To solve the challenges of both custom integrations and 1-1 embeds, many customer data platforms (like RudderStack) offer a one-to-many solution, in which customer interactions are captured once by the CDP’s SDK, and distributed to many different business systems (CRM, marketing automation, analytics, and even warehouse/data lake). These are popular tools because they enable you to sync the entire customer journey to many tools at once.
In this setup, the CDP handles all of the integration work and API changes. This reduces the amount of code in your app or website, making it much easier to deliver marketing data to marketing channels for optimization.
Activating data from one SaaS business tool in a separate SaaS business tool
Sending data from one SaaS tool to another is one of the most widely used data activation workflows. A common use case within this workflow is syncing contact records between tools (i.e., a lead is created in a marketing platform, and then synced to the sales CRM). There is a long tail of SaaS-to-SaaS data activation use cases because of the proliferation of business tools, especially in the martech ecosystem (which often includes social media tools and e-commerce platforms).
While these kinds of connections for data activation can become unmanageably complex if used too heavily in a data stack, they are useful for certain types of data syncs where full pipelines aren’t necessary, and for managing one-off data integration needs (as opposed to full data sets).
There are multiple ways to implement this data activation flow:
SaaS → SaaS direct integration
Many SaaS systems, especially in the marketing and CRM categories, have direct integrations. Salesforce has managed integrations with Pardot, Marketo, and hundreds of other SaaS tools. In addition to syncing various business objects, like leads and accounts, direct integrations often also support syncing individual data points for data activation. Syncing data points generally involves some form of field syncing for data activation, where a field name/label in one system (number_of_employees) is mapped to the corresponding field in the other system (employee_count).
SaaS → Low/no code iPaaS → SaaS
Because there are so many business tools out there, it’s impossible for vendors to support integrations across the whole landscape. An entire industry has developed to support the long tail of API integrations for data activation across tools. This category is called iPaaS, which stands for Integration Platform as a Service. Some of the most popular tools are low/no-code solutions like Zapier and Workato. The workflow can become complex, but generally data activation is simple: choose your source system and the data you want to activate, then choose your destination system, map the data fields, and the iPaaS service will take care of syncing the data.
SaaS → technical iPaaS → SaaS
Low-code solutions are often insufficient for complex use cases. Robust systems like Mulesoft provide technical toolsets that extend beyond data syncing and allow users to activate data by managing integrations with code or APIs and more technical workflows.
Activating data from a data warehouse or data lake in SaaS business tools
Companies often turn raw data into analytics (also called business intelligence), metrics, customer profiles, and audience segments in a central data store, most often a data warehouse.
Historically, these decision-making customer insights stayed trapped in the data warehouse because moving that data into business tools required a significant amount of engineering effort.
The mass adoption of the data warehouse as a source of truth (and for data modeling) has changed things, and today there are multiple ways to deliver data from the warehouse to downstream tools where it can be activated to create business value.
There are multiple ways to implement this data activation flow:
Custom pipeline → SaaS
Many companies still build custom pipelines to push data from data stores into business tools for activation. Snowflake to Salesforce is a common example here. These connections are incredibly common, but data teams are increasingly replacing them with vendor-managed integrations, whether provided by the warehouse or a SaaS tool, or pipelines as a service.
Native warehouse app → SaaS via direct push integration
Modern data warehouses like Snowflake offer native apps that can automatically push data from warehouse tables into business tools for activation. The sync is initiated from the warehouse and is most often managed as part of the warehouse implementation.
Warehouse → SaaS via direct pull integration
Modern business tools like Salesforce and Braze give users the ability to pull data into the warehouse directly from the business tool itself. The sync is initiated from the business tool and is most often managed by the team that owns that tool.
Warehouse → SaaS via managed pipelines (reverse ETL)
Data teams often want the ability to sync a table to multiple tools (as opposed to just one). They also often want more control than direct integrations provide but don’t want to build and manage custom pipelines. For this use case, several companies, including RudderStack, offer managed pipelines, often referred to as reverse ETL, that can sync warehouse data to SaaS tools in a variety of ways.
Activating data from APIs or data stores in websites and apps
While activating data in SaaS tools is extremely common, customer data also often needs to be activated directly in websites or apps to drive personalization, recommendations, and other user experiences. This generally requires a website or app to ‘consume’ information from an API or low-latency data store (often via API).
There are multiple ways to implement this data activation flow:
Third-party API → website/app
Many apps consume information from third-party APIs. For example, a fitness tracking app might consume weather data from a weather API in order to give its users rain alerts.
First-party data store/API → website/app
In addition to activating third-party data, websites and apps often need first-party data to create user experiences that are informed by the full customer profile and demographics. RudderStack’s Activation API gives developers real-time access to a 360-degree view of their customer for personalization and other user experiences based on traits like lifetime value.
Use cases for data activation across departments
Before founding RudderStack, I spent over a decade as a data professional working to enable data activation. Here are some of the common business use cases that me and my teams built out:
- Sending discounts to high LTV customers who abandoned cart – Enabling the marketing team to send 20% discount coupons to loyal customers who don’t complete a purchase can drive significant revenue. I’ve implemented solutions for both rule-based LTV (customers who have spent more than $X historically) as well as predictive LTV (using an ML model to predict which customers will be high LTV).
- Enabling customer success to mitigate churn – The old adage about the cost of retaining a customer is true: it’s far cheaper to enable customer success to engage with customers who are likely to churn than it is to acquire new customers. These use cases tend to combine multiple types of activity data (app, website, usage, etc.) with customer support ticket data and, many times, sentiment analysis.
- Helping sales teams prioritize accounts – This use case typically takes the form of a lead score or account score. Similar to my LTV work, I delivered both basic, rule-based lead scores (i.e., a customer exceeds usage or adopts certain features) as well as ML models for predictive scoring.
None of these use cases are new, but data activation helps businesses implement them more effectively. Let’s look at some more ways in which data activation can be used across different common departments:
Management
Management teams are responsible for strategic business-wide decisions that have the potential to cause a lot of damage if they go poorly. Data activation gives them the clarity they need to allocate resources effectively, pick out key growth opportunities, and, most notably, avoid egregious missteps.
Given how slowly a large corporation can move, having a system in place that facilitates agility while minimizing the associated risks is a tremendous boon.
Product marketing
Developing compelling products is obviously essential for any business, but it’s ultimately how those products are presented that shapes how well they will sell. Marketers perform this vital work.
They need to craft messages and materials that resonate with potential buyers, and that requires a keen awareness of what those prospects are looking for. By highlighting critical pain points and buyer preferences, activated data can help marketers optimize and personalize their campaigns and promotions.
Sales enablement
Given how quickly a lead can evaporate, it’s obvious why sales teams need the right information at the right time. Data activation equips them with detailed insights into leads by highlighting everything from behavioral patterns to past interactions. This data allows them to tailor their outreach toward high-value prospects and close deals more efficiently.
It can also aid the increasingly key process of automation, which fuels personalization and frees up valuable human resources.
Customer experience
Every customer wants something slightly different and thoroughly understanding the people you’re trying to win over is key to creating personalized customer experiences.
Activated data enables representatives to view each customer’s prior purchases, interactions, and preferences. This information helps them take the right actions at the optimal time.
What challenges prevent data activation?
While data activation has the potential to transform business operations, implementing it isn’t without notable obstacles. Here are some key challenges that can get in the way:
Fragmented data infrastructure
When businesses store data across disconnected systems (e.g., spreadsheets or the databases of legacy software tools), it becomes almost impossible for them to draw accurate business-wide insights.
This fragmentation creates data silos, which hinder collaboration and prevent teams from making the most informed decisions. For this reason, centralizing data is essential before pursuing activation.
Weak identity resolution
To deliver personalized experiences, you need to connect data points to specific customers. If your system can’t accurately match actions or interactions to the right individuals, you’ll end up applying the right insights to the wrong situations and sending irrelevant or even counterproductive messages.
This is why it’s vital to use a strong CRM and put in the work to build a strong customer 360.
Unreliable data quality
The quality of data-driven decisions directly depends on the quality of the data you use. If you base your insights on data that’s inaccurate or outdated, you’ll reach faulty conclusions and devise ineffective tactics.
For example, imagine experiencing a duplication glitch that creates a large number of phantom email engagements and investing excessively in email marketing as a result. To keep your data accurate, create a data governance plan and perform regular audits.
Overworked technical teams
If non-technical teams constantly have to wait on engineers for data access or campaign analysis, productivity takes a hit. And, when those engineers have to put their time toward such work, they can’t focus on their regular duties.
Yes, a core strength of data activation is reducing the reliance upon manual analysis, but businesses can only implement it effectively with the participation of technical teams, who must also manage underlying data infrastructure. Wherever possible, find ways to take the pressure off your engineers.
What to look for in a data activation platform
Choosing the right data activation platform is crucial to ensuring your teams can use data effectively.
Out of the available options, a customer data platform (CDP) is the most powerful tool you can use for data activation. You could also opt for a data management platform (DMP), but these have drawbacks as they mostly use third-party data.
When deciding which data activation platform to use for your business, here’s what you should prioritize:
Flexibility and integrations
A strong platform needs to be flexible enough to handle your unique use cases and support a wide range of integrations. Whether you're connecting to CRM systems, marketing platforms, or analytics tools, your platform should ensure data arrives at the right destination without hassle.
Data handling
Look for a platform that supports different data types (e.g., events, notifications, audience segments) and offers automation capabilities. This will make it easy for you to manage complex workflows, effectively leverage data enrichment tools, and adapt to changing business needs.
Unified customer profiles
Consolidating data plays an essential role in creating personalized customer experiences. If you find a platform that builds comprehensive customer profiles using data from all available sources, you’ll be able to take advantage of a customer 360, fueling granular customer data analytics that can create smarter (and thus more impactful) customer interaction tactics.
Audience segmentation
Creating clear audience segments is essential for running effective marketing campaigns. Your platform should make it easy for you to create custom segments using a variety of differentiators (such as behavioral data, predicted lifetime value, purchase signals, or demographics) so you can tailor your campaigns accordingly.
Privacy and compliance
Data regulations are not going anywhere, so your platform must prioritize data privacy. Features for managing consent and ensuring compliance are non-negotiable. To avoid penalties, it’s essential to comply with data protection laws.
Ease of use and scalability
Your platform should be intuitive for non-technical users while being powerful enough for data engineers to work with. It should also have the scalability to grow along with your company, handling increased data volume and diverse use cases without racking up unreasonable costs.
Get a demo of RudderStack’s end-to-end data activation solution
RudderStack gives data teams a tool that enables multiple data activation workflows from a single platform. Built from the ground up for data teams, RudderStack is a flexible and secure warehouse-native CDP.
The platform supports every stage of your data's journey to activation with features that include:
- Real-time event streaming and integrations that allow you to send data from your websites and apps to over 200 business tools and data warehouses automatically.
- Reverse ETL pipelines to make it easy to sync your warehouse data to business tools.
- Activation APIs that give your websites and apps access to your customer 360 in real-time
Sign up for a free trial to experience RudderStack for yourself today.
Implement better data activation workflows with RudderStack
Get a demo with our team today to learn how RudderStack can help you
Published:
December 13, 2024



Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
