Blog
Why your AI agent hallucinates on your data
Why your AI agent hallucinates on your data

Nishant Sharma
Technical Director
21 min read
May 27, 2026

The structural pattern 11 companies discovered, and the architecture that fixes it
Part 4A
Part 1 of this series showed why incrementality is harder than it looks, and why tools built for time-grained analytics break on entity-grained activation use cases.
Part 2 argued that the core problem is not what agents know but what they produce: SQL is the wrong output target, and a semantic intent compiler (a system that compiles YAML-declared business semantics into governed, incremental SQL) changes that.
Part 3 showed why context graphs are the right direction for AI agents, and why the infrastructure to handle them already exists.
This post is about what happens in the field.
A fintech company built an AI agent to query their warehouse. They tested the same query more than 500 times over the course of a week. It passed every time. Then came test 701: the VP demo. Same prompt. Different query. Wrong answer.
The agent was not bad. The context it was working from was raw warehouse tables with cryptic column names and implicit join logic. The AI was reading storage, not meaning.
They are not alone. Over the past several months, the RudderStack team has been part of conversations with 11 companies across healthcare, fintech, automotive, e-commerce, entertainment, and wealth management. The same pattern repeats. Every one is building something with AI. Every one hits a wall. The walls look different from the inside, but if you line them up, three failure families emerge.
The diagram below describes these walls and is followed by additional industry examples.
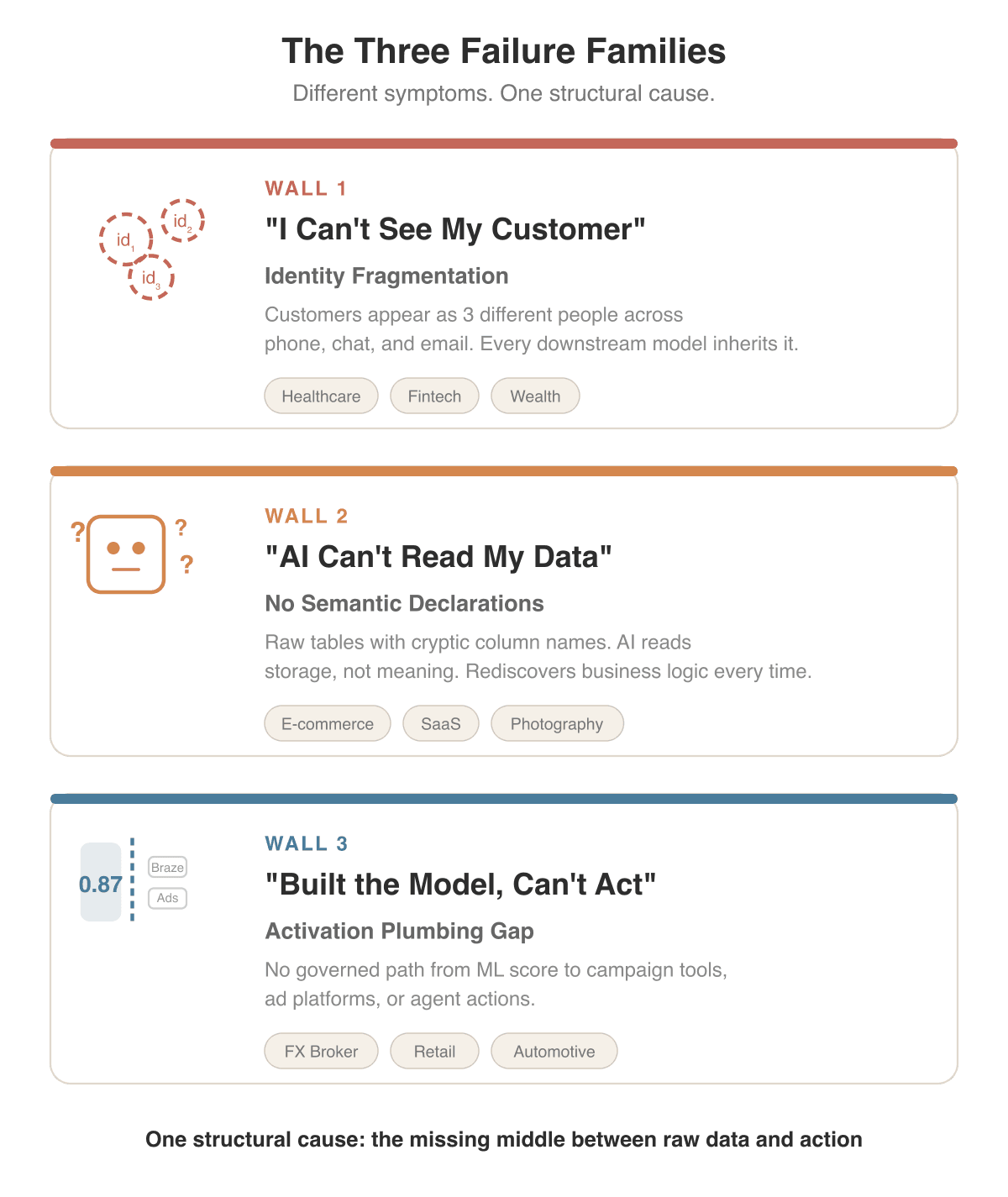
Three failure patterns
"I can't see my customer"
Identity fragmentation. The customer who signed up on mobile, browsed on desktop, and called support from a phone number shows up as three different people. Every downstream model inherits the fragmentation.
A healthcare platform matches therapists to patients using embeddings, but the embeddings only see onboarding data, not behavioral history, because event data lives in a separate system with no connection to the patient entity, so it never feeds the recommendations at all.
A fintech company deploying virtual agents for customer welcome calls finds the same customer appearing as three separate identities across phone, chat, and email. Unifying that identity into a single record is a foundational step they have not yet solved.
A wealth management platform runs a production AI financial advisor serving visitors across desktop, phone, and multiple sessions over a 90-day sales cycle. Without identity stitching, there is no coherent "customer" for the AI to advise. Identity resolution is the capability the platform needs most.
A healthcare company with PHI data in one warehouse and business data in another cannot join them. Data governance is not an afterthought here; it is a prerequisite.
"AI can't read my data"
Raw tables with no semantic declarations. The LLM sees storage (e.g., column names, join keys, audit fields), not meaning. It has to rediscover business logic every time it runs. Sometimes it discovers the wrong logic.
A photography platform runs AI agents connected to their warehouse for churn models, segmentation, and customer insights. This work previously took a data team weeks. It works, until it does not. The agent goes off course or makes too many assumptions exactly where the data model or semantic layer is weak.
An e-commerce team building propensity models for 20K+ SKUs has data scientists spending 80% of their time on feature plumbing and 20% on the actual model.
A ticket marketplace building an AI decision engine realized its first ML model produced no usable results because the team could not determine which features to feed it. The copilot that writes their YAML handles the automation but offers no guidance on which features are actually meaningful, leaving the hard judgment calls to a team without ML expertise.
A consultant deploying data stacks across e-commerce clients finds that standardized schema is what separates AI that stays on track from AI that goes off the rails. Without it, agents rediscover meaning from scratch on every run.
"I built the model, but can't act on it"
The activation plumbing gap. The ML score exists. The campaign tools exist. There is no governed middle layer connecting them.
An FX broker sending predicted lifetime values to Google Ads has no governed path from the warehouse to the ad platform, so they repurpose their analytics tool as a makeshift feature store, using its API to serve ML outputs at query time because the API calls happen to be free.
An automotive company running multi-agent customer service bots is forced to decompose a single agent into five narrower ones because a single agent hallucinated when the context window included the full customer entity. The trigger logic they actually want is straightforward: when a customer's finance agreement is within 90 days of expiration and their equity position turns positive, enter the retention workflow. The governed semantic layer to express that does not exist.
A rental marketplace finds that Snowflake hybrid tables for sub-second personalization are cost-prohibitive and fall back to change data capture (CDC) into MySQL. Every workaround trades cost for latency, or latency for complexity.
An entertainment startup hand-building a real-time context graph faces manual PII handling and prohibitive event-volume pricing. In their view, context is the central competitive battleground, and right now, they are fighting it entirely by hand.
The common thread
The models themselves aren’t the bottleneck. Generating a churn model, a propensity scorer, or a recommendation engine is the easy part now. Any AI coding assistant can do it. The bottleneck is upstream: fragmented identities, missing semantics, no governed path from score to action.
💡Key insight
Three walls, one structural cause. Every company has data. And they collect plenty of it. Every company has activation tools: Braze, ad platforms, chatbot frameworks. What’s missing is the middle: The architecture that turns raw, fragmented data into entity-level context that AI can reason about and act on.
The dependency chain underneath
These symptoms look like four different problems from the inside:
- a chatbot hallucinating,
- a matching engine starved of behavioral data,
- an analytics tool repurposed as a feature store,
- a single agent that has to be split into five because it cannot handle a full customer entity.
But line them up, and they share a dependency graph: identity resolves entities, features describe entities, cohorts group entities, activation targets entities. When something breaks upstream, everything downstream inherits the break.
That is why composing separate best-of-breed tools does not solve it. When identity, features, and activation live in separate tools, no single component can see the full graph. The cascade is invisible to each individual layer.

The fragmentation problem
Without entity resolution, there is no "customer." Instead, there are fragments, and every ML model built on fragments inherits the fragmentation.
A therapist-matching platform wants to use embeddings to match patients to therapists. The user who signed up on mobile, browsed on desktop, and called support from a phone number shows up as three different people. Every downstream model inherits the fragmentation. The embeddings lose more than accuracy; they actually learn the wrong relationships.
And this is not only a data quality problem. It’s also an incrementality problem. When a new identity edge resolves, entity count goes down. In other words, two entities become one. That is subtractive, not additive. And tools built for time-grain incrementality have no primitive for it.
Part 1 of this series walks through why this breaks every standard incremental pattern.
Identity resolution is not a preprocessing step that can be deferred. It is the foundation. Every layer above it—from features to ML to activation—either gets a resolved entity, or it gets garbage.
Features and clean events
Once you have a unified entity, you need two things: features that describe the entity, and clean events that describe what it did.
Features (days_since_last_login, total_spend_90d, support_ticket_count) are today largely hand-written SQL: fragile, non-incremental, non-governed. But features alone are not enough. The intelligence layer also needs clean, typed events. Not raw clickstream rows, but meaningful occurrences: "cart completed," "appointment booked," "payment failed." Today, events arrive as undifferentiated rows in a table. What type of event is this? What are its properties? Which entity does it belong to? These questions are answered by implicit SQL logic buried in ETL scripts that nobody maintains.
This is why the fintech's agent (described earlier in this post) failed on its 701st test. The events had no declared meaning. The features had no declared semantics. The AI was reading storage, not meaning.
An automotive company wants to personalize its service experience. They need a customer health score incorporating purchase history, service appointments, survey responses, and digital engagement. Four source systems. Twelve joins. Hundreds of implicit business rules. The data engineer who wrote the original query left six months ago. Nobody dares touch it. The events from each system (service booked, test drive completed, warranty claimed) are unnamed rows in tables nobody documents.
A photography platform's lead engineer articulated the need precisely: Define a path in the tracking plan ("when a user does X, Y, and Z") and have the system automatically emit a higher-order event. No transformation code. No dbt model. Just a declaration that these events constitute a funnel, and the system recognizes it. What they are describing is declarative event semantics, exactly what event groups and funnel models provide.
Features and events exist only as embedded logic in SQL queries that nobody maintains. Every new use case rediscovers them from scratch.
The ML-on-raw-tables problem
AI code generation quality is bounded by the semantic clarity of its inputs. Same LLM, same agent, different context, different outcome.
When a data scientist or AI coding assistant builds a model against raw warehouse tables, the workflow is:
- Discover which tables matter
- Figure out joins and entity keys
- Handle deduplication and nulls
- Re-engineer features from scratch, and
- Hope the schema hasn’t changed since last week.
An e-commerce company with 20,000 SKUs spends 80% of data science time on those steps and 20% on the actual model. Then next quarter, when the product catalog changes, they repeat it.
A SaaS company wants to predict expansion revenue. Any AI coding assistant can write a gradient-boosted model in minutes. But it cannot find the right features across 200 warehouse tables. It generates plausible-looking SQL against wrong tables, joins on wrong keys, and produces a model that fits the training data beautifully and means nothing.
The photography platform mentioned above pushes this furthest, running Cursor agents connected to their warehouse via MCP as a full data science workflow. It works, until it doesn’t.
Their lead engineer's diagnosis: The agent trajectory goes off course or makes too many assumptions where the data model or the semantic layer is either incorrect or weak.
Their current semantic layer, which consists of dbt models and LookML definitions, provides enough context for the agent to generally figure out where it's going. But enough is not reliable. The agent is overly confident exactly where the semantic definitions are thin. This is the ML-on-raw-tables problem expressed at scale: The semantic layer becomes the rate limiter on AI quality.
A consultant who implements data stacks across multiple e-commerce companies arrived at the same conclusion from a different angle: "Without standardized schema, you then let the AI go off the rails. But when it's standardized, it makes it a lot easier to build any type of AI agent."
The consultant points out that most platforms have standardized schemas only for e-commerce events. Lead-based events, subscription events, content events, usage-based events have no standards. Every company reinvents them. Every AI agent that consumes them must rediscover the meaning from scratch.
Two independent observations: A photography platform's data scientist and an e-commerce infrastructure consultant working from completely different starting points, and both converge on the same structural insight.
The practical difference is 10x better context-per-token: 500 tokens of semantic YAML versus 5,000 tokens of raw DDL noise. But context compression is not the differentiator: dbt metrics, LookML, and Cube also compress context.
The difference is what happens after the agent reads it. With those tools, the agent reads compressed context and outputs raw SQL: ungoverned, stateless, probabilistic. With a semantic intent compiler, the agent reads YAML and outputs more YAML, which the compiler transforms into governed, incremental SQL. The context is both the input the agent reads and the contract the agent writes.
Part 2 of this series lays out the full argument.
A ticket marketplace's data lead put it plainly: The hard part is not AI. It’s preparing data in a way that AI can actually make sense of it. Her team tried building propensity models on their semantic layer and got nowhere because they were accidentally feeding the model attributes that already predicted the outcome. Not because the model was wrong, but because the tool that helped them write YAML did not help them understand which features make good predictors.
The bottleneck wasn’t the model. It was the semantic surface the model consumed.
The activation gap
A company builds an ML model. It produces a churn score. Now what?
This is where most companies stall, and not because activation tools do not exist. They exist in abundance. The problem is that each activation pattern requires a different interface to entity context, and no one has built the governed middle layer to serve it.
Across the 11 companies we spoke with, five patterns surfaced:
- Ad platforms need predicted lifetime values fed back to optimize spend, but the predictions live in the warehouse with no governed path to Google Ads.
- Chatbots and agents need real-time entity context, but PHI governance, PII masking, and per-agent access control cannot be afterthoughts. The automotive company above decomposed one agent into five because a single agent hallucinated on a full customer entity.
- Workflow triggers need governed, fresh entity features crossing thresholds, like the finance agreement within 90 days of expiry with a positive equity position.
- Real-time personalization needs sub-second feature serving. One rental marketplace tried Snowflake hybrid tables and found the cost prohibitive; falling back to CDC into MySQL just trades one problem for another—cost for latency, or latency for complexity.
- And AI advisors need the full context graph. A wealth management CTO running a production AI financial advisor finds that the quality of the interaction between human and AI improves dramatically when good contextual data is fed into the system. But what makes it deployable is putting rules-based APIs on top of the LLM, constraining what the model can do rather than letting it act freely, precisely because LLMs are non-deterministic by nature.
Every one of these patterns needs the same foundation: entity features, ML scores, and cohort membership-–all governed, all fresh. Without it, companies fall back to manual CSV exports, one-off queries, and "we'll figure out governance later." The reality: They never do.
A consultant who deploys data infrastructure across e-commerce clients observes that AI often becomes the catalyst for a CDP project that was already overdue. Companies do not realize their data is siloed until they try to build an AI agent and discover it cannot access the context it needs. The AI use case exposes the activation gap that was already there.
Why these four problems are actually one problem
When a new identity edge merges two entities into one, every feature computed on those entities is stale. Every cohort that included either entity needs re-evaluation. Every activation targeting either entity (the campaign, the ad audience, the chatbot context) is operating on a ghost.
The cascade runs from identity to semantics to activation. An identity tool that does not invalidate downstream features, a semantic layer that doesn’t know about identity merges, an activation layer that does not know what is stale: no component in a composable stack can propagate this cascade automatically. You need one system that owns the dependency graph across all three layers.
That system has a structure.
Separating meaning from storage
After three years building a semantic intent compiler, including designing the primitives, writing the incremental engine, and watching what breaks at scale, one conclusion has become clear:
The fix is to completely separate what data means from how it is stored.
Not a thin reference layer on top of tables. That is what dbt models and LookML definitions already provide, and the evidence above shows where that breaks. The fix is a complete world model in business language: entities, events, entity features, cohorts, entity relationships, predictive traits, funnels. Pure semantic intent, with no imperative SQL mixed in.
The foundation is the entity: A real-world object (user, account, product, listing) that your system models. Not a table, not a primary key. An identity-resolved concept that spans multiple data sources. The user who signed up on mobile, browsed on desktop, and called support is one entity. Everything else in the architecture (e.g., features, cohorts, relationships, events, ML scores) is organized around it.
You declare this world model in structured YAML. A semantic intent compiler conceptually moves through a six-stage pipeline (Parse, Resolve, Discover, Optimize, Generate, Execute) and deterministically produces incremental, governed SQL. You write what things mean. The compiler handles how they are computed. Teams change, priorities shift, people rotate. But the semantics survive because they are declared, not embedded in queries.
What a semantic intent compiler does differently
Today's semantic layers (dbt, LookML, Cube) translate business questions into SELECT statements. But the infrastructure underneath (the tables, materializations, identity resolution, incremental computation) is someone else's problem. So the semantic layer must reference physical tables by name, navigate foreign-key relationships between warehouse objects, and assume a specific data layout. Data layout leaks into the semantic language because the semantic layer does not own what is underneath.
A semantic intent compiler takes responsibility for infrastructure SQL as well: creating tables, managing materializations, resolving identities, running incremental computation. The agent never references a table name. It declares intent (e.g., "I want churn_risk_30d for entity user"), and the compiler owns everything from YAML declaration to warehouse execution.
When the semantic layer owns the full stack, data layout never leaks into agent definitions. A source migration, a schema restructure, a new payment processor: the agents do not notice. The compiler absorbs it.
This gives you three things that no thin semantic layer can provide:
- SQL performance becomes a property of the system, not of AI skill: the compiler generates optimized, incremental SQL using
this.DeRef()with named checkpoints and conditional DAG semantics, so query performance is durable and predictable regardless of how the agent evolves. - Governance is enforced at compile time, not bolted on afterward: Tag a field as PII in YAML and every downstream model that touches it inherits the privacy filter automatically, by construction.
- And data shape changes do not break agents: When your warehouse schema evolves (tables renamed, columns migrated, sources swapped), the Profiles compiler handles schema changes automatically, so the semantic surface your agents consume remains stable.
Think of it like a low-level virtual machine (LLVM), the compiler infrastructure that separates language frontends from optimized backends: The agent is the frontend (translating human intent into declarations) and the compiler is the backend (generating optimized, governed execution). Better frontends make the backend more valuable, not less.
Three tiers: What engineers set up, what engineers define, what agents do
The world model has three tiers. Engineers build the first two. Agents operate on the third, and can extend it.

Tier 1: Engineer declares what exists
This is the bedrock. Engineers declare the system's inputs, entities, and the relationships between them.
Inputs and metadata: Raw data sources with declared schemas: what entity they relate to, what events they carry, what properties those events have.
Entities: The real-world objects the system models: user, account, product, listing. Each entity has an identity graph; the compiler knows that user_123 on web and user_456 on mobile are the same person.
Identity resolution: Graph-based entity resolution across all inputs. The compiler builds and incrementally maintains the entity graph.
Entity relationships: Declared connections between entities: user to account, listing to provider, patient to therapist. These enable cross-entity traversal via this.DeRef(), so agents can compute cross-entity features without writing joins.
Event schemas: Typed, named events with declared properties and entity relationships. An event group is a semantic contract.
Tier 2: Engineer owns meaning, trust, and governance
On top of the world model, engineers define the governed semantic surface.
Entity features: Computed attributes of an entity: days_since_last_login, total_spend_90d, support_ticket_count. Declared in YAML, compiled to incremental SQL, automatically joined with entity resolution.
Metrics: Reusable aggregation templates: avg_order_value, retention_rate_30d. Defined once, invoked by anyone in features, cohorts, and dashboards.
Trust and governance: Access control, PII masking, audit trails. Declared alongside the features, not added afterward.
Tier 3: Agents operate and extend in business language
Agents think in business language because the foundation speaks business language. They do not just consume the semantic surface; they extend it.
New feature: The agent declares entity_var: a computed attribute like churn_risk_30d or product_affinity_vector. The compiler generates incremental SQL, joins with entity resolution automatically, and maintains it going forward.
New cohort: The agent declares entity_cohort: a named subset like high_value_at_risk or trial_activated_no_purchase. Incrementally maintained and immediately available for ad targeting, campaign triggers, ML training sets, and experimentation holdouts.
New funnel: The agent declares events_driven_funnel: ordered stages referencing events with time bounds. The compiler generates window-function SQL. Conversion metrics become entity features automatically.
New ML model: The agent declares propensity:, attribution:, or llm_model: operating on declared features and events. Outputs feed back into the feature table. The semantic surface feeds the model; the model enriches the surface.
Compose: The agent references any declared concept inside any other: {{user.churn_risk_30d}} in a cohort filter, a metric in a feature, a cohort in an activation trigger. The compiler resolves dependencies, ensures freshness, and generates optimized SQL across the composition.
Agents do not write SQL. And they do not reason about table joins or schema changes. They simply declare intent, and the compiler handles identity resolution, incrementality, governance, and performance.
The power is in composition
Each primitive is small. The creative leverage comes from combining them. Define a feature, and it automatically joins with entity resolution. Define a cohort over that feature, and it is immediately available in activation. Define a funnel, and its conversion metrics become entity features that are available to ML models, other cohorts, and activation triggers. No matter how complex the combination, the compiler guarantees correctness, governance, and performance.
What makes this possible is a five-layer architecture. Part 4B will cover that architecture in full: the five layers, where most stacks break, and why owning identity through features through activation as one system matters.
The bottom line
The models are not the bottleneck. Generating a churn model, a propensity scorer, or a recommendation engine is the easy part. Any AI coding assistant can do it now. The bottleneck is upstream: fragmented identities, missing semantics, no governed path from score to action.
Eleven companies across six industries found the same ceiling. The AI use case didn’t create the problem. It exposed the one that was already there.
The fix is not better prompting or richer metadata, though both help at the margins. It’s a different architecture: one that separates what data means from how it is stored, compiles that meaning into a form that can be governed and maintained incrementally, and gives agents a stable semantic surface to build on rather than raw tables to rediscover every time.
When the foundation speaks business language, agents can too. That's what separates AI systems that work reliably in production from ones that pass 500 tests and fail on the demo.
Explore the RudderStack Profiles documentation to learn more about entity resolution, semantic features, and the composable primitives described in this post.
Published:
May 27, 2026



Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
