Blog
Feature launch: Feature builder
Feature launch: Feature builder

Ryan McCrary
Product Manager at RudderStack

Matt Kelliher-Gibson
Technical Product Marketing Manager
9 min read
February 21, 2024
A comprehensive identity graph is critical for every customer data use case. It’s the foundation you need for analytics, attribution, personalized recommendations, customer journeys, and everything in between. While creating your identity graph is a major (and mandatory) milestone, it’s only one piece of a multi-step workflow required to turn your customer data into competitive advantage.
When it comes to using the data in your identity graph for use cases that can power growth, it’s all about the features.
First, an identity graph builds the foundation by stitching unique identifiers for entities across platforms and datasets. It gives you a comprehensive view of each individual entity. Entities can be users, accounts, households, pets, or even physical devices.
Next, features, commonly called traits, are built on top of the identity graph to describe those entities with data points. Put the two together, and you have a customer 360 that can power use cases for your entire business.
With a robust identity graph in place, you can easily write SQL to output a single feature for an entity, but this approach quickly becomes untenable in the real world. As you add more features to meet business requirements and create comprehensive customer profiles, the amount and complexity of your SQL code grows, eventually becoming a liability that prevents you from effectively serving your business.
If you want to build a solid data foundation that enables you to serve your business with agility, handwriting SQL queries for features will hold you back. You need tooling that simplifies feature creation and allows you to scale projects easily as data and business needs change. Today, we’re introducing our feature builder to help you move fast without breaking things. Feature builder is part of RudderStack Profiles and compliments our identity graphs feature.
A new approach to feature creation and management
When you’re handwriting SQL queries for your feature tables, it’s nearly impossible to keep up with the business. When marketing requests a new feature, you may find yourself going through thousands of lines of SQL written by multiple people over multiple years trying to prevent unintended consequences like breaking the BI dashboard your sales team uses.
This approach slows you down and leads to frustrated business partners and missed opportunities to maximize your team's impact. The cost only increases as ML and AI use cases become more prevalent because AI/ML models require access to present and historical features.
When downstream teams don’t get data for business use cases fast enough, it’s not uncommon for them to procure their own tools to implement specific, narrow use cases in the short term, primarily working out of their own data silos and creating their own customer traits. While this may solve an immediate problem, when teams operate on slightly different data sets, a disjointed understanding of customer metrics develops. As the data silos drift further apart, data trust within the company can erode completely. We’ve seen this play out within businesses of all sizes across many verticals, and we believe there’s a better way.
Introducing feature builder for RudderStack Profiles
To solve the problem, we believe data teams must own identity resolution, data models, and feature generation in a central, open environment. For this to work in the real world, though, data teams must be able to keep up with the demands of the business. While existing solutions like dbt can help you better manage your SQL and foundational models, using them to create and scale an identity graph and user features leads to the same old problems of brittle, unmanageable code. That’s why RudderStack Profiles uses declarative data modeling to model for customer 360, and it’s why we designed feature builder to abstract the intricate SQL required to define your features.
With RudderStack’s feature builder, you can easily generate and maintain features across any data set in your own data warehouse. It sits on the foundation of our identity graph solution for RudderStack Profiles and follows the same guiding principles.
- Warehouse native – Feature builder is not a black box tool. It generates SQL that runs transparently in your warehouse or data lake so you can understand exactly what queries are operating on your data and how the outputs are generated. The outputs are also fully contained in your warehouse. This transparent approach facilitates greater data trust and enables easy troubleshooting.
- A central home for all data features – Feature builder enables you to efficiently generate features in your warehouse. Because it affords speed, it eliminates the need for business teams to create features in silos. This enables and incentivizes an approach where the data team owns the data models and feature generation and the data warehouse serves as a central source of truth.
- Datasets for every team – Enabling new use cases often requires old and new features. Because creating multiple data models involves time investment and overhead, it’s tempting to force every use case into one generalized data model, but this creates issues when teams have differing needs for specific features (product wants user-level features while customer success wants account-level features). Feature builder makes it easy to build multiple feature tables on top of the same identity graph, allowing you to deliver bespoke data sets based on the same source of truth.
Your path to feature agility
Feature builder makes creating, maintaining, and scaling features easier. It will help you quickly deliver reliable features to downstream stakeholders, and it’s easy to get started.
Start from a solid foundation with 30 features out-of-the-box
With feature builder, you don’t have to start from zero. Because it’s part of RudderStack Profiles and built upon the same config (even the same inputs) used to power identity graphs, getting started is simple. You can easily define simple features on inputs, features that reference each other, and even use custom SQL queries to define features for more advanced use cases. And you don’t have to start from scratch. Profiles even automatically calculates over 30 features for you, including predictive features like churn scores.
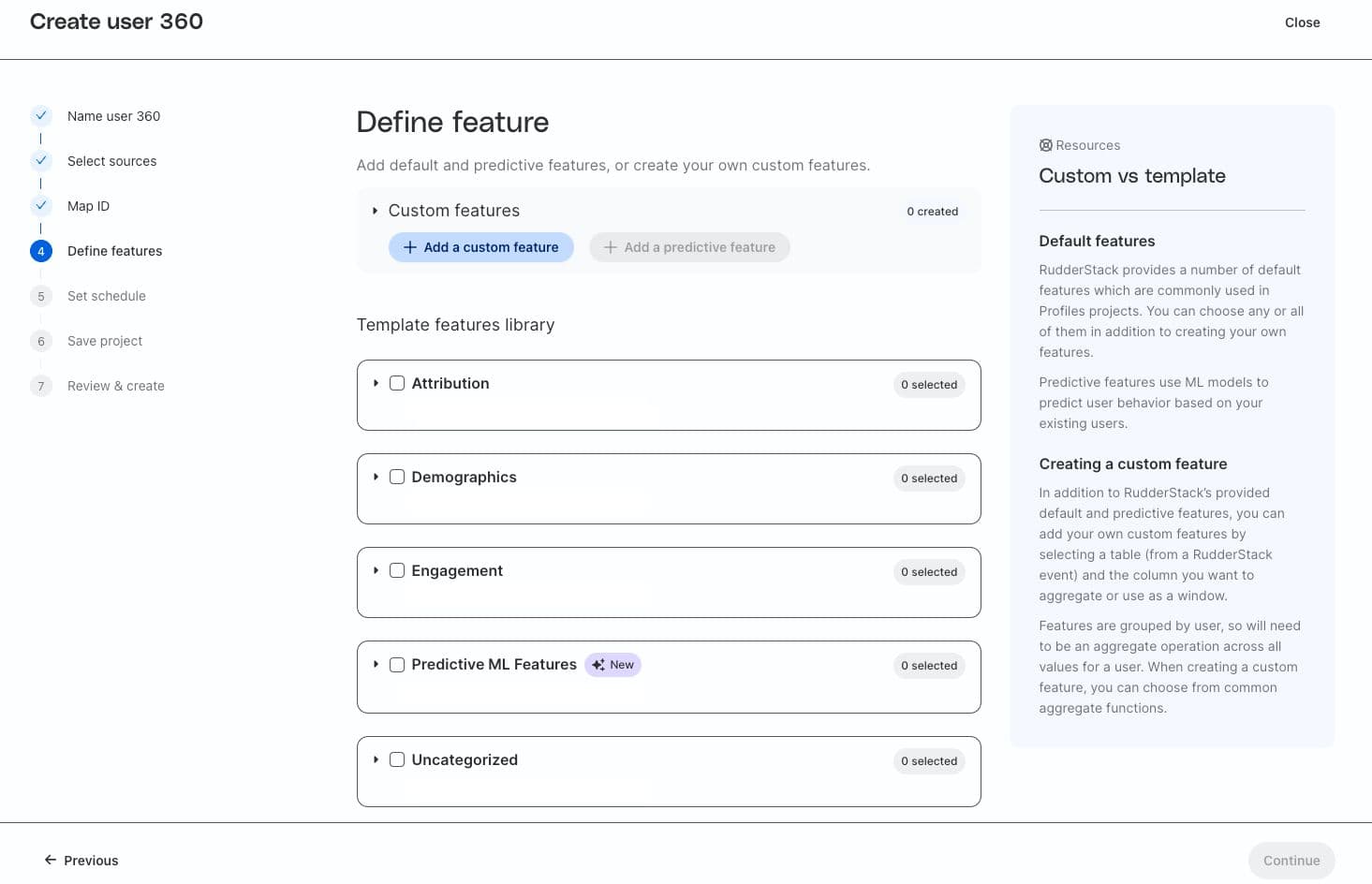
With feature builder you can intuitively define features through the Profiles UI. This enables both data teams and technically savvy business users to generate new features for their use cases. However, with feature builder, you’re not limited to the UI. You can go deeper with clear, concise, code-based configuration. Use our YAML configuration to easily create comprehensive feature tables across any number of data sets and identifiers using SQL syntax for your feature definitions.
YAML
Maintain and scale with confidence
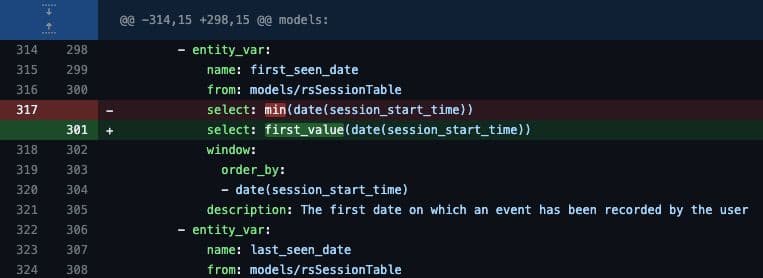
To make maintenance easier and enable you to move quickly, feature builder compartmentalizes individual features, limiting the ability for one to affect another. With this check in place, you can ship new features quickly with increased reliability and without fear of breaking existing models or features.
YAML
Feature builder also allows you to apply software best practices to feature generation. You can power your projects off hosted Git repositories from your tool of choice so you can understand changes over time.
Unblock and unlock every use case
With the agility afforded by feature builder, you can support your stakeholders with reliable data for every use case and quickly, even proactively, adapt to changing requirements. Once your features are built, data activation with RudderStack is easy. Deliver data directly to the tools your stakeholders use via our Reverse ETL pipelines, or use our activation API for real-time use cases.
Add velocity and potency to AI/ML initiatives
Feature builder can provide immediate lift to your AI/ML efforts. Clean, reliable data is the starting point for any successful machine learning initiative, and feature builder makes it easier to fuel your ML models with clean, verifiable feature tables. Additionally, because Profiles projects are typically triggered over consistent intervals, you have historical snapshots for each feature and how it’s changed over time. Combine transparent, reliable features with historical changes, and you can confidently deliver powerful ML solutions.
For specific use cases, you can use feature builder in tandem with our Predictions product to quickly train and automatically deploy ML models without complex MLOps. Predictions currently supports churn and conversion scoring.
How it works
RudderStack Profiles makes it easy to get started generating features. If you’re using data from our Event Stream product, you can choose from 30 automatically generated features (including predictive features!) within the UI. You can also add simple features using any data source in your identity graph with the custom feature builder.
For more complex use cases, you can export a complete Profiles project and directly edit the config YAML files. Just enter new features as entity_var and use the same syntax as regular SQL queries. Because each variable is defined in isolation, you can confidently edit and create new features as business needs arise.
Start building feature tables today
Getting started with Profiles is easy, our out-of-the-box project templates help jump-start your feature table. If you’re using RudderStack for streaming data, Profiles can automatically create a feature table out-of-the-box. We also happily stitch any data that exists in your data warehouse.
Getting started is as simple as downloading a sample project, connecting to your data set, defining your identifiers, and selecting your features. Then you’re off to the races.
Build features with agility
Request a demo with our team today to see feature builder in action
Published:
February 21, 2024



Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
