Blog
Feature launch: Identity graphs
Feature launch: Identity graphs

Ryan McCrary
Product Manager at RudderStack
9 min read
January 2, 2023

RudderStack is the warehouse native CDP built for data teams.
Identity graphs are a foundational component of almost every use case involving customer data, from analytics to personalization. At a basic level, an identity graph builds a complete view of a business entity (user, account, etc.) by finding all unique identifiers for that entity across a variety of data sources.
Building an identity graph, though, is challenging. If you’ve ever undertaken an identity graph project, the pitfalls are obvious. At the beginning of the project, identity resolution starts simply enough – deduplicating users that exist as multiple records or have multiple identifiers from a known set of disparate data sources. This process is essentially creating a simple identity graph across your data, most often with SQL joins.
But, inevitably, edge cases begin to creep in. The data model in your CRM is different from what the team anticipated. A legacy system uses a different data model and has legacy data that needs to be resolved to your current (and much better) data model. So, over time your simple model grows into an unmanageable mess… that downstream teams can’t live without because it’s the most comprehensive source of customer data available for data activation use cases, from analytics to lists for marketing.
These models also become more and more fragile over time as you add new sources, data models change, and team members move on. Before you know it, the model becomes a risk in and of itself. Adding new datasets or even minor conditionals begin to affect existing use cases and break downstream systems. Adding a new data source becomes a long-lived project where newly introduced bugs are chased at each step of the project. Ultimately, you end up with an increasingly brittle model that few trust but the business relies on. These problems can't be solved in marketing platforms or audience-building tools.
That’s why it’s time for dedicated tooling that helps data teams solve identity resolution at the root and easily scale the project as data and business needs change.
Introducing identity graphs for RudderStack Profiles
We launched the first version of our Profiles product at Snowflake Summit in June of 2023. Since then, we’ve been working directly with customers to understand their identity resolution projects on a deeper level and how we could improve our product to make their work even more streamlined.
Today, we’re announcing identity graphs for Profiles, a feature that allows data teams to easily configure and generate deterministic identity graphs, at any level of complexity, directly in their warehouse.
Like all RudderStack features, identity graphs are warehouse native, meaning:
- All of the jobs run transparently in your warehouse or data lake
- The code Profiles produces is transparent, auditable, portable SQL
- Schedules and data sets are fully configurable, making it easy to control compute cost while still meeting the needs of every downstream team
- The output tables for identity graphs live within your warehouse
Easily model your complex business logic using flexible entities
One major challenge businesses face is that traditional data models from marketing, customer success, and sales tools rely on an overly simplistic user/account taxonomy. Most business models transcend such a narrow view.
It’s not an uncommon requirement for data teams to consider not only individual entities (customers, users, etc.) but also how they roll up or relate to each other in the concept of a household, business, or account. IoT companies often also need to associate physical devices with users and households.
Identity graphs in RudderStack Profiles are completely agnostic to business entities and can support any kind of relationship between entities, drastically simplifying the task of modeling business logic.
Build dedicated identity graphs for specific business use cases
In addition to multiple entities, many businesses have multiple business lines/brands or multiple categories of users to consider.
Companies with this more complex business logic often need to resolve user identities across business lines while maintaining dedicated identities and user feature sets individually for each business line.
For example, many retail companies own multiple brands. They need to understand how individual users purchase across different brands, which requires ‘global’ identity resolution. At the same time, it’s critical they maintain distinct views of that customer’s relationship with each individual brand to optimize brand-specific offers, loyalty programs, and campaigns. Further, brand-specific teams often want dedicated views for their users to simplify their analytics and other work.
Profiles identity graphs make it easy for data teams to maintain a global view of every entity alongside dedicated identity graphs for brands, product lines, teams, or any other business logic component.
How does it work?
When we set out to build a proper identity graph solution for our customers, we were building what we wanted and what we knew our customers needed to accomplish their most important business goals. We knew this needed to be done in the data warehouse, not in yet another cloud tool, and that using the product should create clarity, trust, and a deeper understanding of data relationships.
We wanted to solve the problem more elegantly than any other available solution. It had to be easy to understand, easy to maintain, and follow software best practices.
We also wanted to provide an onramp for data teams to help them avoid the cold start challenge and make basic use cases accessible to less technical users.
Starting with automated identity graphs through the RudderStack app
Because you can run RudderStack as a connected, end-to-end system, our Profiles product can automate basic identity resolution on RudderStack data.
Practically, this means that data engineers, analysts, and even technical ops or marketers, can use the RudderStack UI to select RudderStack sources, map identifiers, and run a job that produces an identity graph in their warehouse. In fact, Profiles automatically maps standard identifiers (anonymousId, userId, and email).
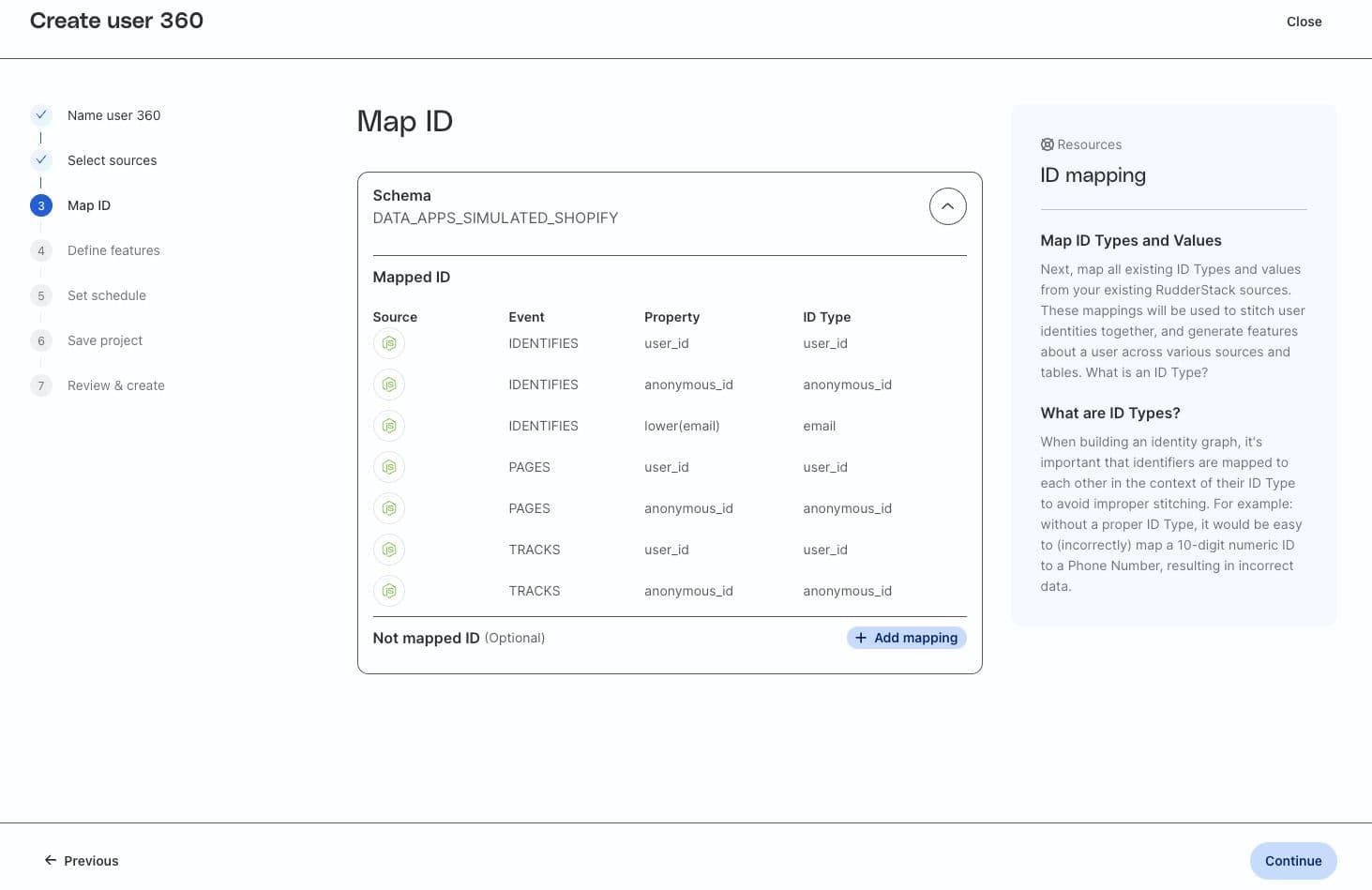
Go deeper with clear, concise, code-based configuration
With Profiles identity graphs, you can configure your identity graph logic using clear, declarative code that makes sense. Our YAML configuration file allows for rapid configuration of comprehensive graphs across any number of data sets and identifiers.
Once you configure the YAML file and run the job, Profiles will generate all of the SQL code required to produce the identity graph, along with the output table of nodes and edges for each individual entity.
Here’s a sample configuration file:
YAML
No black boxes: audit ID graph SQL for visibility and troubleshooting
Once your identity graph has been defined, you can easily compile your project and check the actual SQL code that will be run against your dataset. This eliminates confusion about how your graph is being defined and allows your team to understand and debug issues quickly and easily as they arise in your graph.
Here’s an example of the SQL that Profiles generates to build the identity graph.
SQL
Easily update entities when new data sources are added
Even if you have well-defined entities, maintenance can become challenging when new data sources are added that include new entity traits.
Identity graphs makes updating entities with new data sources extremely easy: incorporating new traits from new tables is a matter of adding a new inputs (tables) and identifiers (column names) to the config file.
Here’s an example of a user entity with identifiers from multiple data sources:
YAML
Stay in control and scale with software engineering best practices
As your identity graph evolves and grows, it becomes even more important to understand the source of truth for your model and how it changes over time. You can build Profile’s identity graphs within our UI, but you can convert them to a git repository for more complex configuration at any time.
This allows you to use software engineering best practices, like version control, to maintain your identity graphs. Users can use different branches for dev/staging/etc, run within CI/CD workflows, test their models before merging, and have a complete view of historical changes using Github, BitBucket or GitLab.

Always maintain full transparency in your data warehouse
Not only does Profiles build identity graphs on top of data in your data warehouse, but the output identity graph itself is generated and stored in your data warehouse.
You can use the graph to power other existing models, build features through RudderStack, or any other type of activation from your warehouse. Shipping use cases is fast and easy when powered by clean tables in your warehouse.
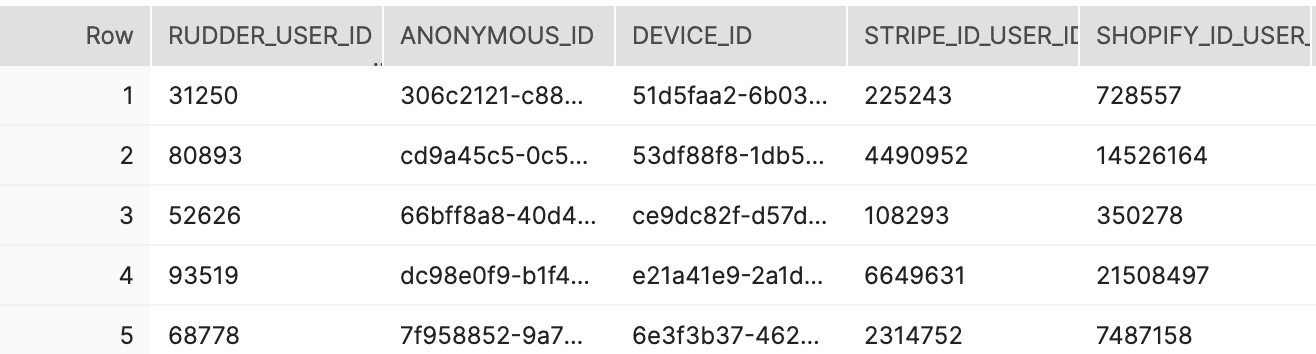
Get a running start on ML use cases
It's no secret that every team is moving towards ML use cases to maximize the effectiveness of data within their organization. While opinions and approaches to ML vary, the one universal fact is that clean, reliable data is necessary to build viable ML use cases. Identity Graphs provide a clean, trustworthy, verifiable starting point to generate high-fidelity data for your ML inputs.
Start building with identity graphs today
Getting started with Profiles is easy, our out-of-the-box project templates help jump start your identity graph. If you’re using RudderStack for streaming data, Profiles can automatically create an identity graph out-of-the-box. We also happily stitch any data that exists in your data warehouse.
Getting started is as simple as downloading a sample project, connecting to your data set, and defining your identifiers. Then you’re off to the races.
Build scalable, transparent identity graphs in your warehouse
Request a demo with our team today to see RudderStack Profiles in action
Published:
January 2, 2023
More blog posts
Explore all blog posts
Salesforce data enrichment: Best tools for 2025
Danika Rockett
by Danika Rockett

CIAM: What is customer identity and access management?
Danika Rockett
by Danika Rockett

Deterministic vs. probabilistic models: A guide for data teams
Danika Rockett
by Danika Rockett


Start delivering business value faster
Implement RudderStack and start driving measurable business results in less than 90 days.


