Blog
Declarative Data Modeling for Customer 360
Declarative Data Modeling for Customer 360

Nishant Sharma
Technical Director

Brooks Patterson
Head of Product Marketing
13 min read
October 5, 2023

Modern data modeling is more efficient, collaborative, and scalable than ever, especially with tools like dbt. Creating a customer 360, however, poses unique challenges, such as resolving the identity resolution problem. Those who have grappled with this issue using SQL-based tooling know how painful it can be.
Data modeling for customer 360 warrants a different, declarative approach that builds on modern methods and leverages additional, purpose-built tooling.
In this post, we’ll look at the strengths of modern data modeling, explore the specific challenges of modeling a customer 360, and detail how RudderStack Profiles provides a robust, scalable solution using declarative data modeling.
What is data modeling?
They say the devil is in the details. When it comes to customer data, you could say the devil is in the data model. Data modeling is the strategic framework that dictates how data is organized, stored, and retrieved — it facilitates the 'T' in ELT (Extract, Load, Transform) workflows. While extraction and loading ensure data makes it into your systems, modeling is a prerequisite for transforming that data into an insightful and actionable structure useful to teams across the business.
Data modeling is the foundation of success for all downstream data use. For example, at RudderStack, we combine Salesforce data on leads, accounts, and customer interactions with internal data such as monthly event volume ingested and product feature usage. The data model enhances the precision of sales forecasts and facilitates data-informed support for our customers. This example also demonstrates why we believe the data warehouse should be the foundation of your CDP — it’s impossible to model complete data if it’s siloed in SaaS tools.
Modern data modeling
Data modeling has come a long way since its beginnings in the early days of computing. The rise of the data warehouse in the early 2010s and Kimball’s Data Warehouse Toolkit, with its introduction of dimensional data modeling, ushered in the modern era of modeling for business analytics. Then, in 2016, a little project called dbt (data build tool) came out of RJ metrics and changed the game for analytics workflows. dbt brought software engineering best practices to analytics code management and introduced a modular approach to data modeling.
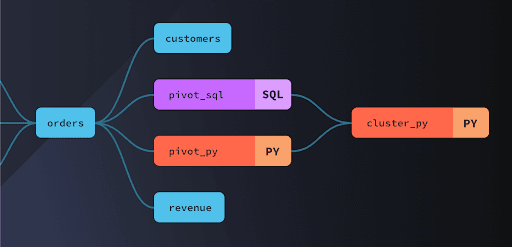
The modern data modeling workflow
When modeling data with dbt, the basic unit is a transformation. A transformation processes one or more input tables to produce an output table. These transformations, called models, can be written in templatized SQL or Python.
Modern data modeling with dbt delivers several benefits:
- Git-based workflows for model creation allow team-based development and review.
- Test assertions help ensure data quality.
- Models can reference the output of other models, so it’s possible to reuse SQL code and automate dependency tracking. This also enables you to resume failed runs on a per-model basis.
- A variety of community-contributed packages are available.
- Vendors also offer dbt packages, providing models that speed up use cases for vendor-specific warehouse data. Check out RudderStack’s dbt repos here.
At RudderStack, dbt is the top choice of our analytics engineering team for tasks like shaping raw data, combining data that are used across many reports and analyses, and streamlining data workflows for various teams. It’s the first stop for data preparation and analytics, where raw data needs to undergo baseline cleanup and structuring to be useful.
For example, understanding utilization across RudderStack customers requires combining total monthly volume across pipelines with product feature usage data. Before the final joins that drive reporting, the event volume data needs to be cleaned and aggregated. Once the dbt model runs, the baseline ‘utilization table’ output is used as a part of multiple analytics use cases.
We also use dbt to cleanse and remodel Lead, Contact, and Account data from Salesforce so any team can use it as part of their reporting or for ad hoc analysis.
dbt is an indispensable tool for us, but some of its limitations are exposed when it comes to building our customer 360, a use case downstream of baseline modeling. It is possible to do data modeling for a customer 360 view with dbt and SQL—in fact, we previously solved for ID resolution and customer journeys using those tools—but it’s painful and error-prone, especially at scale. Our customers affirmed this. Here are just a few of their specific struggles:
- As the customer 360 dataset grows, SQL-based data modeling can cause performance bottlenecks. Queries take longer to execute, impacting the ability to update reports quickly.
- As business needs change, maintaining and updating SQL-based customer 360 models becomes a significant overhead. It leads to increased development time and costs and involves models that rely on ‘tribal knowledge’ from the original builders.
- Maintaining matching rules across a myriad of different data sets with SQL becomes untenable at scale, and once deployed into production, even minor tweaks bring major risks of breaking something.
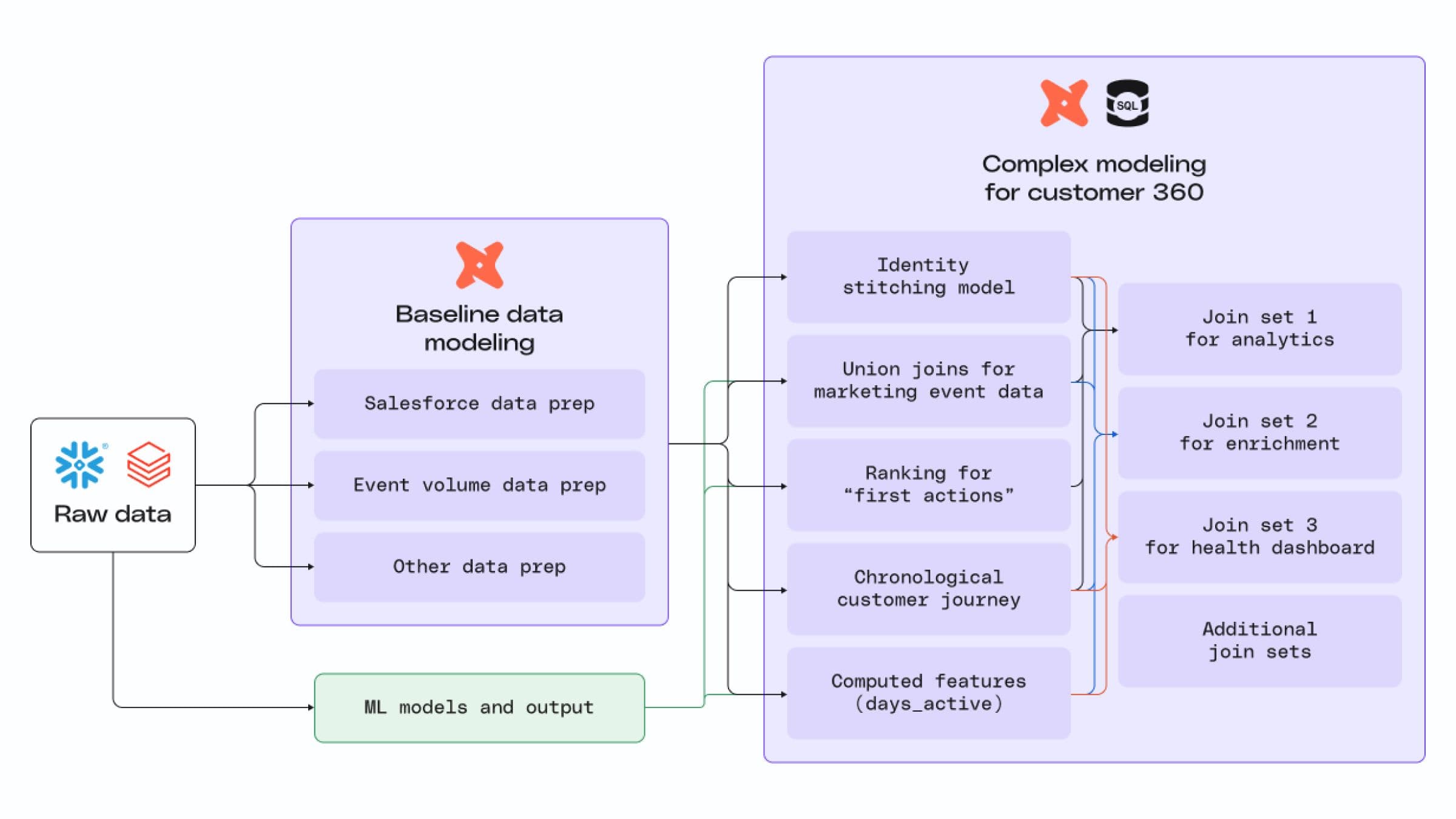
These challenges demonstrate why adding another tool to your toolbox for customer 360 data modeling is advantageous.
Consider the various types of saws you might find in a carpenter’s workshop. The table saw is a versatile tool that can make just about any cut, but it’s best suited for cutting large pieces of wood down to size at the beginning of a project. Cutting angles with a table saw is possible, but it’s difficult and leaves the precision of every cut up to the steady hand of the carpenter.
The miter saw, on the other hand, is a less versatile but more sophisticated tool. Miter saws are designed to make angled cuts with precision and efficiency. Set a miter saw to the desired angle for your cut, and you can quickly make angled cuts, relying on the tool to ensure every cut is perfect.
For many companies, dbt is the table saw – it’s used for baseline data modeling on almost all of their data. Customer 360 data modeling, however, begs for a proverbial miter saw.
What makes data modeling for customer 360 difficult?
Before we show you how RudderStack Profiles extends modeling capabilities, it’s worth digging deeper into the challenges of modeling a customer 360. At a foundational level, building a customer 360 model is hard because it involves both solving identity resolution to produce an identity graph and building user features on top of that identity graph:
- The identity graph represents your business entities and their relationships to each other (i.e., users, accounts, households)
- The features (or attributes) describe those entities (i.e., logins_last_7_days, LTV, churn_risk, total_sales, P0_last_30_days)
Combine these two components, and you can produce a Customer 360 table that every team can use for powerful use cases. But you must account for many unique complexities through data modeling before you can get a clean, usable customer 360 table:
- Fragmented identities: Customer 360 requires identity resolution across various siloed data sources, different entities, and a plethora of unique identifiers.
- Dynamic identity data: Customer profiles aren’t valuable if they’re out of date, and as new data gets generated, previously distinct identities may need to be merged.
- Dirty data: Customer data is messy, and duplicate information is unavoidable, making inconsistencies and discrepancies inevitable.
- Event timestamp alignment: Aligning event data from multiple sources to a common time base is hard because event paths differ, sources follow different timestamp conventions, and there can be network glitches, data buffering errors, or coding errors.
- Idempotency: Data pipeline stages must be idempotent to ensure predictable behavior.
- Point-in-time correctness: ML models require point-in-time correctness, but event alignment challenges make this hard to achieve.
You can handle each of these challenges using a SQL-based approach, but doing so is painful, especially at high levels of scale and complexity. It involves repetitive work that results in excessively complex, brittle code that creates a significant maintenance burden over time. One of our customers sank three years into a Customer 360 project before ultimately abandoning it because of the high maintenance costs. The final product worked, but the total ROI relative to the total cost wasn’t justifiable.
The good news is it doesn’t have to be so hard.
Create a customer 360 with RudderStack
See how you can use the Warehouse Native CDP to overcome data collection, unification, and activation challenges.
Escaping SQL hell with declarative data modeling
Instead of handwriting the intricate SQL for your customer profile models, what if you could simply add a column name to automatically generate the necessary SQL based on existing maps and definitions?
That’s how RudderStack Profiles, our customer 360 solution, works. Profiles takes a declarative approach to modeling, abstracting away the intricate SQL and automatically creating a robust customer 360 table based on your declarations. It fits into your existing workflow, complementing the baseline data modeling work you’ve already done.
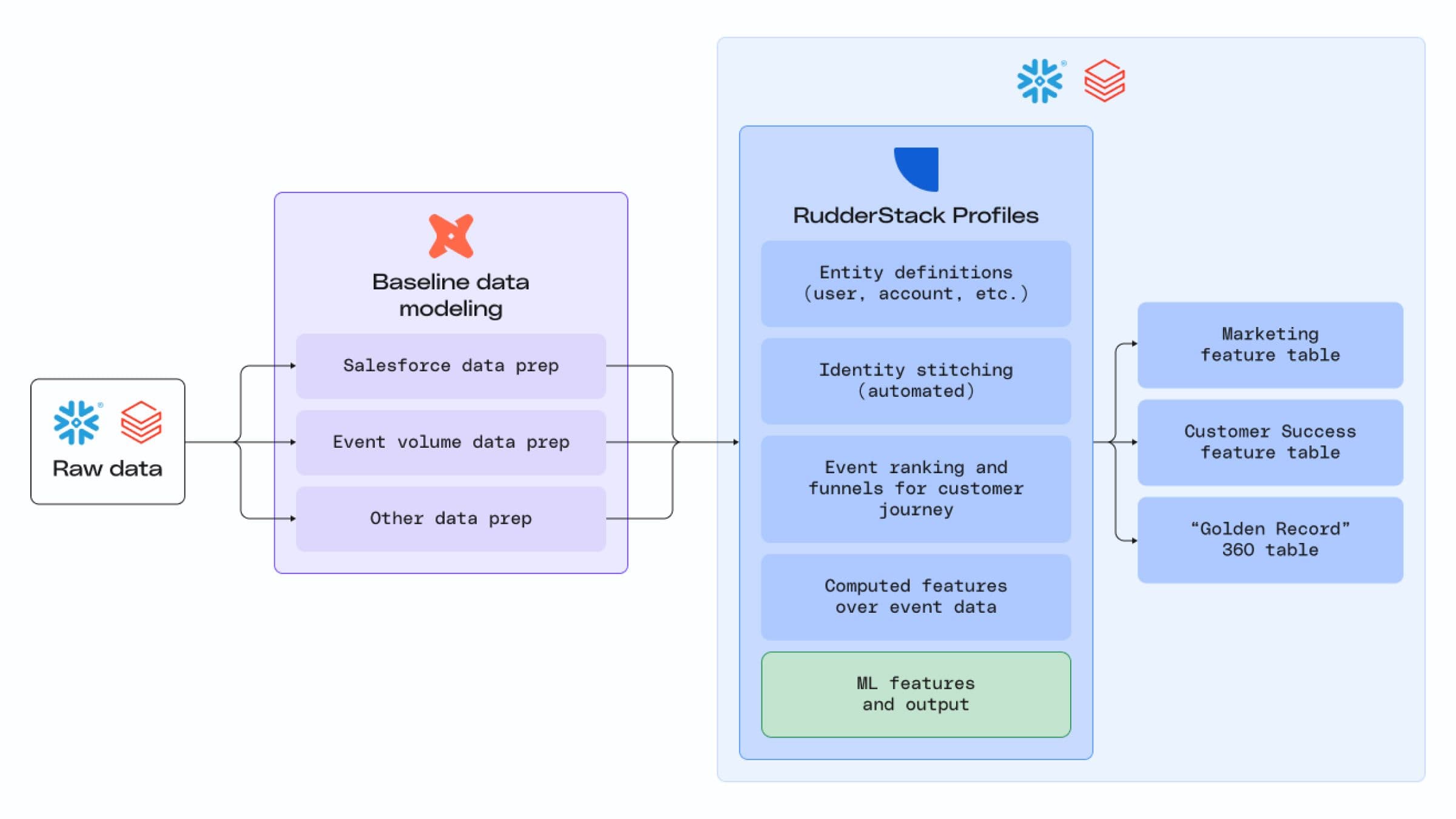
To illustrate how this works, let’s break a customer 360 project down into its three key components:
- What to build – the business logic, including features and alignment on the customer definition (is a customer a subscriber, a user, a household, a physical address, a company, or some combination of those entities?).
- The ingredients to use – the data sources and data points required to deliver the business requirements.
- How to build it – the actual modeling work, which includes writing code to solve identity resolution, creating an identity graph, and computing user features.
Data teams are intimately familiar with the ingredients (data sources) available to use for various requirements. So, if business partners can clearly define the customer and have a good idea of what they need, the problem lies in how. Implementation is where repetitive work and brittle code rear their ugly heads. It’s Implementation work that makes seemingly simple data requests from marketing complex to deliver, eating up days or weeks of valuable time.
To solve the implementation problem, RudderStack Profiles creates an abstraction layer that separates the business concerns from the build:
- Business concerns – The business logic and corresponding ingredients
- Build – Creation of the identity graph and the implementation of SQL to compute the business logic on top of the ID graph
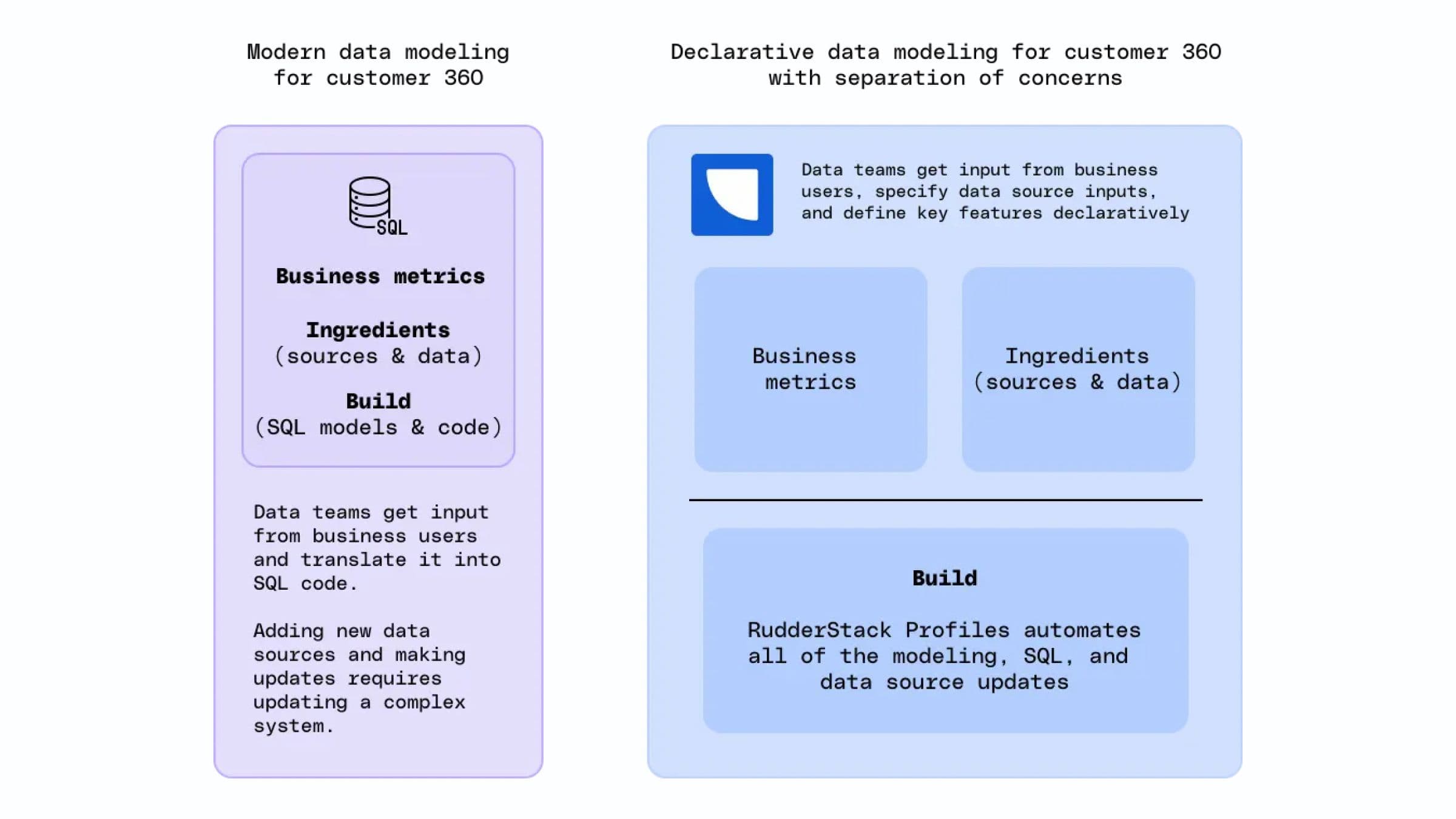
Profiles uses a declarative approach to remove the burden of how to build it from the data team. Business stakeholders describe the desired outcome, and data practitioners determine the inputs (ingredients). This work happens above the abstraction layer and covers what to build with which ingredients.
Below the abstraction layer, the burden of how to build it is happily delegated to RudderStack’s tools and libraries. With instructions on what to build and which ingredients to use, RudderStack Profiles handles identity stitching to build an identity graph and automatically generates the code required to compute the business logic on top. The code generated is auditable and portable, so you don’t have to worry about vendor lock-in.
Our minimally expressive approach simplifies data modeling so data teams can quickly respond to changing business requirements and integrate new data sources. It frees them up to channel their creative energy into tailoring unique business solutions and data products rather than focusing on low-level engineering concerns and endless model maintenance.
When you have the power of RudderStack in hand, you can blast off right away. It’s so much easier to build a machine learning model once your designs are driven by clean data, useful user features, and complete 360 customer views.
Wei Zhou, Director of Data Engineering at Wyze
The secret: Profiles’ semantic foundation
Profiles’ power comes from its semantic foundation. Unlike other approaches, semantics aren’t just a utility layer on top – they’re built into the foundations of the product.
Profiles provides multiple core semantic model types. These prepackaged models are built for specific use cases, and each one elegantly handles the challenges to modeling for customer 360 that we covered above (fragmented identities, event timestamp alignment, etc.). They act as transformers, interpreting your declared business logic and transforming it into SQL statements (or Python code for ML use cases).
Profiles currently offers semantic models for:
- Identity stitching
- Entity definition (objects like user, device, etc.) and entity variables
- Input definition (data sources) and input variables
These core semantic models have additional meta information that makes them intimately aware of their input/output semantics. This enables them to regularly adapt their behavior – and generate appropriate output – based on their semantic understanding.
Here’s the workflow: You build your own semantic-aware model spec in YAML. This spec ties your business logic into semantic primitives that Profiles understands and uses to generate the various features you define. So, you don’t have to write any SQL to generate an identity graph and user features – all it takes is a simple YAML config!
Ultimately, though, the queries generated by these semantic models are SQL statements that are fully auditable, so you maintain full transparency, control, and portability.
We’re actively developing additional semantic models for more advanced use cases:
- Semantic events
- Segments
- Funnels
- Churn
- Lead score
- Lifetime value
Check out our Early Access launch of ProfilesML for churn and lead scoring!
Conclusion
If you’ve struggled with data modeling for your customer 360, you’re not alone. Modern tooling affords many luxuries when it comes to data modeling, but modeling for your customer 360 is uniquely challenging. We’ve felt the pain of the SQL-based approach ourselves, and many of our customers have echoed our frustrations.
That’s why we built RudderStack Profiles. The product's semantic foundation enables a declarative approach to data modeling for customer 360 projects. It writes the intricate SQL for you, so you can focus on using your data to drive better business outcomes.
If you want to see Profiles in action, reach out to our team to get a demo of the product today.
Create a customer 360 with RudderStack
See how you can use the Warehouse Native CDP to overcome data collection, unification, and activation challenges.
Published:
October 5, 2023



Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
