Blog
What is the Starter Stack?
What is the Starter Stack?

Eric Dodds
Head of Product
23 min read
June 7, 2022

If you work in data, you’ve heard about “the modern data stack.” But the conversation around the term can make it confusing for practitioners. First, definitions of the modern data stack, along with the related architectural diagrams, are all over the place. It’s a popular term, but it’s hard to define practically. Second, and more importantly, the modern data stack is often positioned as a single big step for a data team: “implement the modern data stack!”
Practitioners working in data know the reality on the ground is different. Data stacks grow and change along with the needs of the business. For data teams doing the work, the goal is actually to progressively modernize your data stack in practical ways that impact the businesses ability to make better decisions with data. It’s not about adopting a particular architecture because it is considered modern.
Modernizing a stack is a process that takes time and thought at each juncture—and there are many, many steps to take as the business grows and changes. The good news is, you don’t have to take a single, overwhelming step. You can start making small changes whatever your starting point is to better meet the data needs of your business.
Every company is on a journey to mature their data stack, whether it’s an eCommerce company that needs better analytics or a Fortune 500 company trying to operationalize machine learning models.
This is the first post in a series breaking down each phase of the Data Maturity Journey, a framework we’ve built to help data teams navigate the sea of tools and architectures of the modern data stack. It’s to help companies build the most practical, helpful stacks for every stage of their journey. Like every journey, it has a beginning. In our framework, we call this the “Starter Stack,” which is where most companies take their first step in modernizing their data stack.
It’s important to note that the “starter” designation doesn’t refer to company stage (i.e., it’s not just for startups). As we will outline below, this phase of the journey is for companies of any size who are facing data integration and data consistency problems due to the lack of a unified data layer.
Starter Stack overview
When it comes to investing in a data stack, the first step is the most important. The foundational decisions you make about your data stack now will have a big impact on the future. It’s critical to get this first step right because the robust, clean, and scalable data layer of the Starter Stack makes it easier to progress to later phases, like the Growth Stack and ML Stack, where you’ll build advanced analytics, enrich data, and stand up predictive models.
The Starter Stack introduces a “unified data layer” that addresses two fundamental data challenges that companies must solve first in order to enable more powerful data use cases:
- Data consistency: Using multiple systems to create and manage customer data caused inconsistency across tools in the stack
- Integration complexity: every company faces data integration challenges, whether they are a small company using a few SaaS tools or an enterprise with multiple legacy systems
As any data professional knows, if data consistency and data integration aren’t solved at the root with a unified data layer, it doesn’t matter what kind of advanced technology you use in other parts of the stack—other tools will have fundamental limitations because they are only as good as the data you feed them.
The Starter Stack solves these problems by:
- Leveraging a single system to create and update both customer behavioral data and customer traits (which make up user profiles)
- Removing the need for point-to-point or custom integration work by unifying all integration needs into a single, automated integration layer
These problems are related, but distinct. Data can become inconsistent both at the source and in the process of flowing through integrations, so it is critical to separate these concerns in the architectural solution.
Here’s what Starter Stack architecture looks like at a high level:
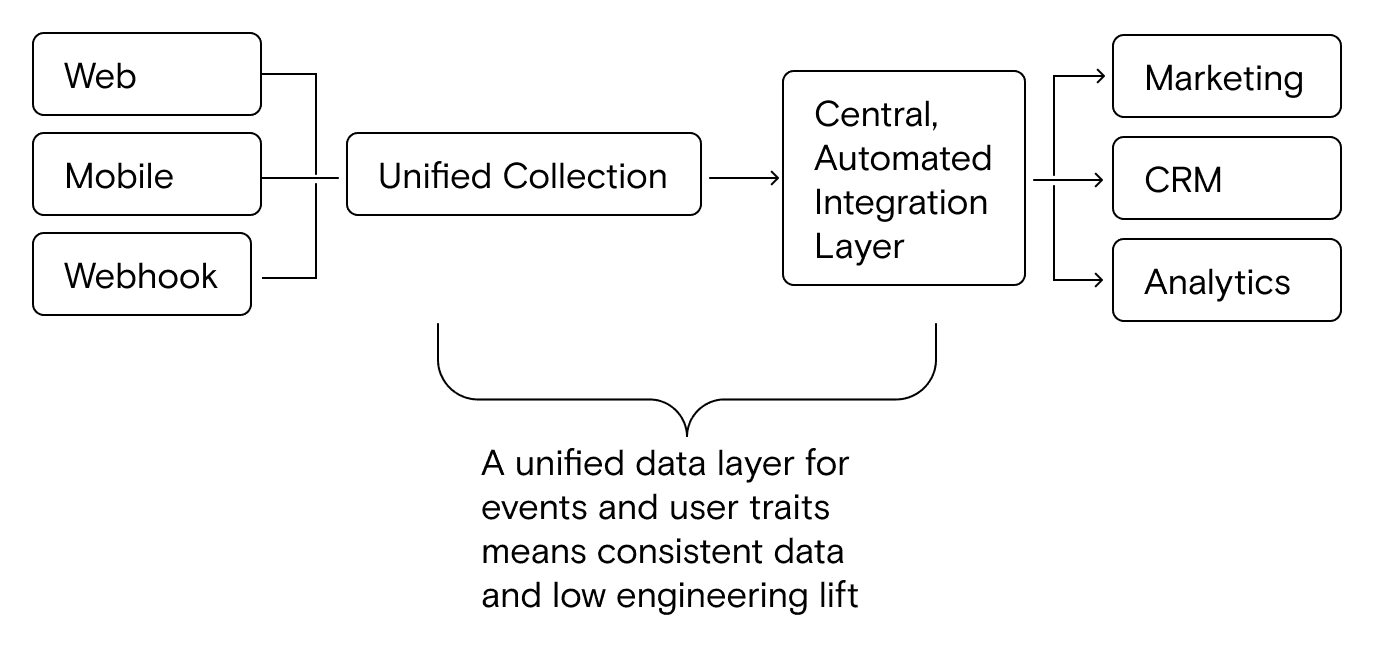
When do you need to implement the Starter Stack?
A big part of finding success on your data maturity journey is knowing what steps to take when. Taking a step too late, or too early, can mean wasted time, money, and effort. So, let’s take a look at when it’s time to set up your Starter Stack.
Symptoms that indicate you need the Starter Stack
If you’re experiencing constant pain related to data and/or decreases in velocity due to data consistency issues or data integration problems, you’re probably in need of a unified data layer. The specific nature of these pain points vary from business to business, but here are a few example symptoms:
- Point-to-point integrations between SaaS tools require constant maintenance related to custom fields, different data types, and limited ability to customize syncing (most often because the only option is primitive field-to-field syncing, which is notoriously problematic across systems, especially without customized scheduling).
- The “same data” is different across different tools, meaning different teams have different versions of the truth. A classic example here is comparing ad platform conversions and analytics conversions with your actual user number.
- You are forced to export data from multiple systems in order to answer basic questions on topics like conversion rates, customer segmentation, and marketing attribution.
- You can’t answer even simple complex questions about your customers and their journey, without a herculean manual effort. For example, it’s hard to know exactly how many users visited a particular page or screen because your web analytics and product analytics tools show different numbers.
- You’ve tried to solve some of these problems by deploying engineering hours against them, but the ongoing maintenance, constant requests from marketing and other teams, and developers’ dislike of the work are making it clear that using internal dev resources isn’t sustainable.
What your company and team might look like
As we said before, companies of any size can begin their data maturity journey by implementing the Starter Stack—it all depends on your starting point, your specific needs, and your data challenges. That said, because customer journeys are more complex (and margins much thinner) for direct-to-consumer companies, they often feel the pain earlier than B2B companies, even though both are solving the same basic set of problems.
If your company is on the smaller end of the spectrum, you:
- Are likely using developer time to tackle data engineering and data integration work, which is often a significant distraction from building the core product, site, etc
- Have someone playing an ops role, whether formal or informal. Someone from marketing or sales ops might have had to jump into the nitty gritty of integrations and data munging, or the person who operates a tool like the email marketing platform could be solving data problems so they have clean(er) data to work with
If your company is larger, you:
- Have a dedicated data or analytics team
- Are running a custom web/app platform that relies on multiple legacy tools and custom data integrations, all of which require maintenance
- Are slow to respond to data and integration requests from teams like marketing because of the complexity and interrelatedness of the app/site and integrations codebase
- Have to regularly export data from back-end systems to combine with data from the SaaS tools your analysts and other teams use
Making it practical with an example company
Let’s drive this home by looking at an example company that’s ready for the Starter Stack.
Company description
You’re an eCommerce company, large or small (as we said above, company size doesn’t matter). Your website, mobile, and marketing teams focus on driving digital purchases through your site and app, and you also have a sales team supporting wholesale buyers. Many of the sales team’s prospects are long-time repeat digital purchasers who would benefit from opening an account.
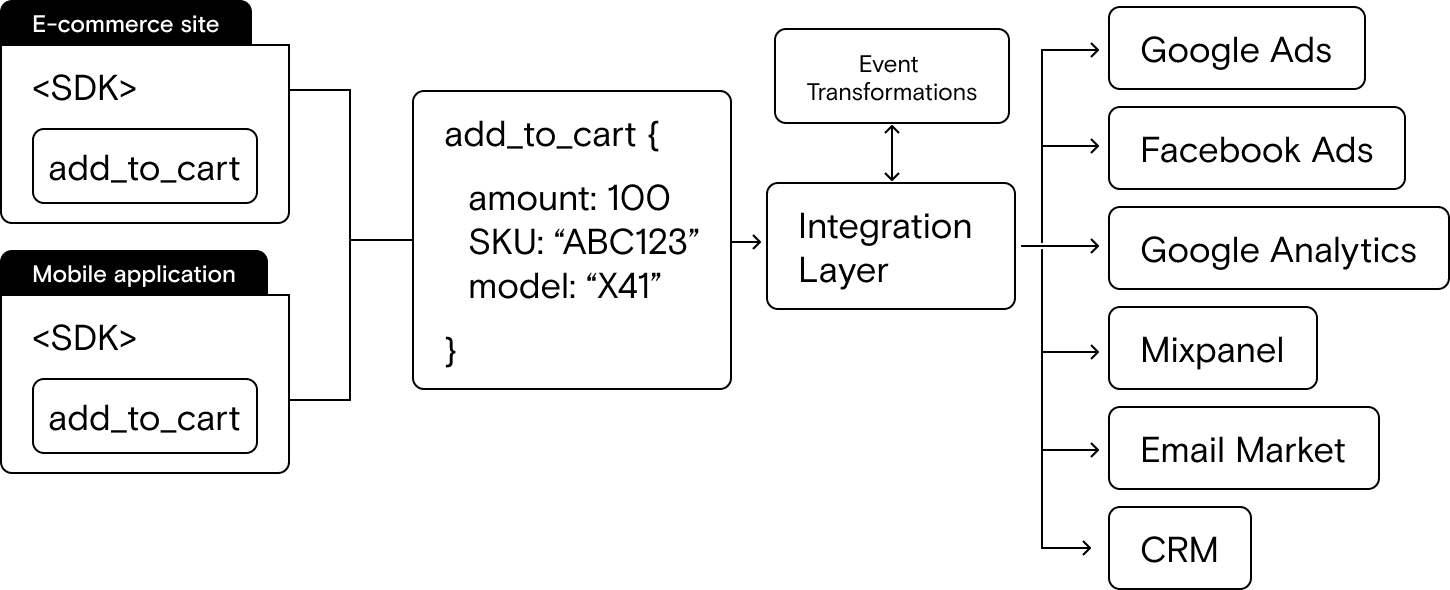
The data stack
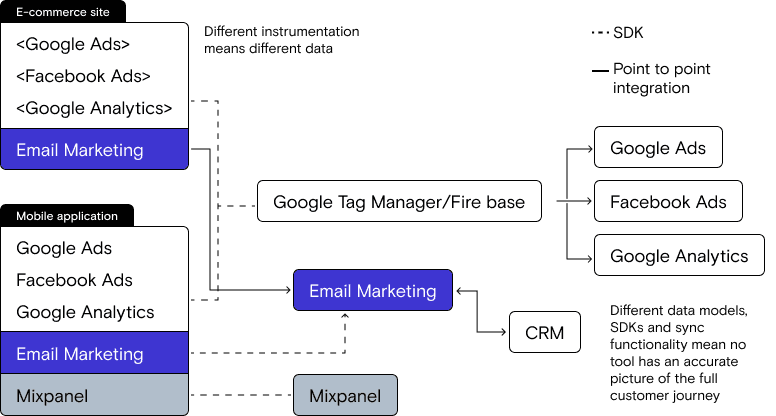
Your website runs on a 3rd-party platform (like Shopify or BigCommerce). On the website, your marketing team runs scripts for Google Ads, Facebook Ads, and Google Analytics, all via Google tag Manager. Their email marketing tool is connected to the eCommerce platform with a point-to-point integration.
Your mobile app also runs scripts for Google Ads, Facebook Ads, and Google Analytics via Google Tag Manager and Firebase. Plus your mobile team runs the Mixpanel SDK for mobile product analytics. Because the mobile app is custom, you also run the script from the email marketing tool directly in the app.
The sales team uses a CRM that gets its data from a point-to-point integration with the email marketing tool.
Here’s what the stack architecture looks like:
Your data challenges
With this architecture, it is very likely that you are facing data challenges. Here are a few specific pain points:
- Despite ongoing work and multiple overhauls of the Google Tag Manager implementation, conversion data across Google Ads, Facebook Ads, and Google Analytics is inconsistent, making it hard for your marketing team to know exactly what’s working best. Worst of all, it’s hard to triangulate this data across platforms (web and mobile)
- The eComm platform’s traffic data is different from Google Analytics data, making it hard to triangulate actual website and mobile visit volume from various sources and get clarity on first touch attribution. There are also discrepancies between Google Analytics and Mixpanel for mobile data, which further complicates the picture. Ultimately, no one has a single source of truth for analytics
- Your email marketing tool has much more flexible data fields than your CRM, meaning only a subset of data can be shared across the tools, limiting your sales team’s ability to see the full customer record in their tool of choice. This also means that your eComm platform, email marketing tool, and CRM all have different versions of the ‘same’ customer record
- Your web and mobile engineers are constantly bombarded with tickets related to Google Tag Manager and conversion instrumentation, as well as troubleshooting data discrepancies
- Someone on your team, likely an ops or admin person, spends a huge amount of time fiddling with the point-to-point integrations across the eComm platform, email marketing tool, and CRM. They’re spinning their wheels fielding requests for data from the marketing and sales teams, and fixing issues when data doesn’t look right in marketing and sales tools
- Because of these challenges , there’s a person on the team who spends 4-6 hours 1-2 days a week exporting data into CSV files, running complicated vLookups or macros in a spreadsheet, and manually updating charts
- Despite all of the laborious efforts, you still only have basic reporting, and no one really trusts their reports
The Starter Stack Playbook: implementing a unified data layer
So, how do you fix all of the problems above? With a unified data layer, of course! But before we get to the specifics, let’s talk about what your goals should be for the Starter Stack and, most importantly, what your data focuses should be in this phase.
Goals of the Starter Stack
The Starter Stack will make it almost certainly easier to get accurate analytics in your SaaS analytics tools and better understand your customer, but the reality is that deriving insights about your customer is a never-ending journey that generates new requirements as your business grows and changes. Getting the foundational data right is the first step.
The goals for the Starter Stack stage are simple:
- Create data consistency by unifying data collection at the source
- Stop wasting time on low-level integrations dev work
If you get those two things right, you’ll solve your biggest pain points, and create a foundation that makes it easy to deliver increasingly complex data products as your company grows.
Data focuses of the Starter Stack
Once you start working on modernizing your stack and solving problems like the ones outlined above, it’s easy to get excited about all of the things you could fix or modify. It’s incredibly important, though, to make sure you get the data fundamentals right. If you do, every subsequent step becomes easier and you can avoid huge amounts of technical debt and re-work.
In this stage, two main types of data serve as the foundation:
- Behavioral data
- User traits
These behaviors and traits come from your websites and apps as users interact with them and, at some point, make the transition from an anonymous user to a known user. These data points are often called “events” and this category of data is commonly called “event stream data,” “clickstream data” or simply “user behavioral data.”
If you review the challenges mentioned above, they all relate to either:
- Analytics on user actions (e.g., purchase, form fill, ad platform conversion, page view, scroll, etc.)
- Customer records of user characteristics (e.g., email, shipping address, shirt size, rewards membership status, etc.)
Keeping things simple in this stage is key. Until you have consistent data on your users and what they do, adding more data sources and data types into the equation will only complicate things.
The first step: map your user journey
One of the main culprits behind data inconsistency is that implementing tracking of user actions often happens ad-hoc for a specific tactic. For example, your marketing team might want to track subscriptions to their new daily deals email, which seems simple enough in isolation, but in reality is part of a complex customer journey.
Without considering the bigger picture, it’s easy to instrument one-offs that create technical debt later. The way teams name ad-hoc actions can often create confusion in data because they aren’t thinking about the names of all of the other actions being tracked (i.e., what do newsletter, newsletter_1 and subscriber mean?). If you are multi-platform, be sure to think through how the same user might interact with both your web and mobile experiences.
Before you start implementing the Starter Stack, it’s important to map out your customer journey, from their first page view all the way through to the actions they might take after becoming a customer. You might not need to track every single action from the outset, but the context will help you make better decisions about
- What you do need to track
- The naming taxonomy you use to describe the actions
Pro tip: once you’ve decided on the events you do want to track and what to name them, that index should serve as your tracking plan and instrumentation guide, which every stakeholder should help build and approve. Here’s an example tracking plan template.
Mapping your tracking plan against current actions and conversions
Once you’ve decided what you want to track and how you want to name events, you should map your plan against the user actions and conversions currently being sent to your downstream platforms. This allows you to see which events are net-new and which already exist (and need to be modified to match the tracking plan). It will also give every stakeholder visibility into what’s going to change.
Pro tip: even if a downstream team has some poorly named events, there will likely be pushback about having to build out new reporting or remember the date an event named changed. These are valid concerns. Even if a team wants to keep an old event, we recommend setting up new destinations that receive only the new and modified data—over time this clean, fresh start will become more and more valuable. If your data pipeline tool supports event transformations (more on that below), you can have the best of both worlds by renaming new events to match the old names for the original destination.
How-to: creating consistency at the source
Inconsistent data from the source happens for one very simple reason: you are sending the ‘same’ data point, using different code, to each separate platform (which all have their own APIs). For example, Facebook’s code is fbq('track', 'AddToCart'); vs Google’s code, which is gtag(‘event’,’add to cart’,{});.
Let’s look at a simple user action like an “Add to cart” event. Looking at our pre-Starter Stack architecture, that one event is tracked 4 different times on the website:
- One event for Google Ads
- One event for Facebook Ads
- One event for Google Analytics
- One event from the eComm platform (sent to the email marketing tool)
On mobile, the addition of Mixpanel means the event is sent 5 different times.
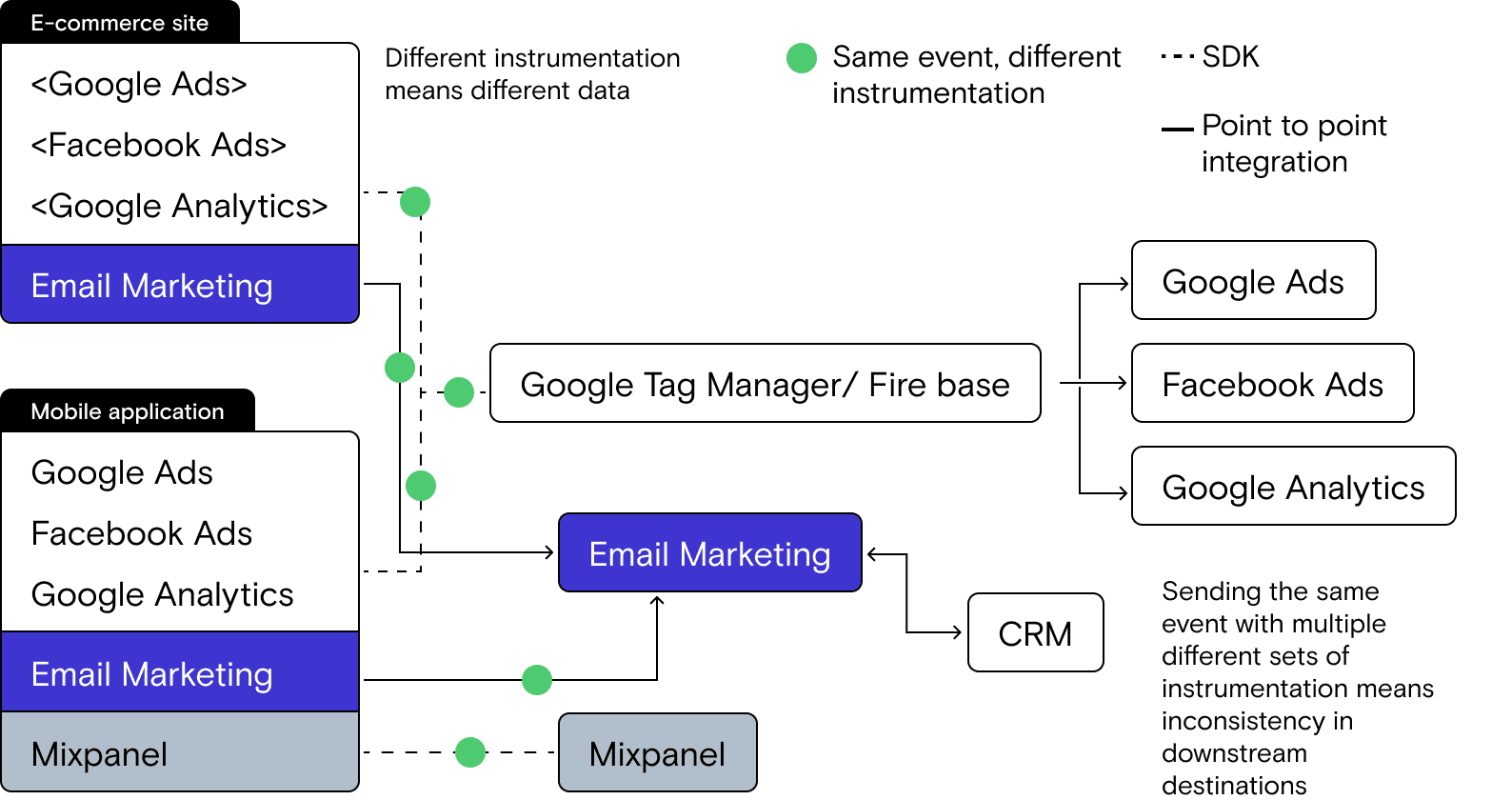
Anyone who has worked in a stack like this knows that the potential problems are endless: script sequencing issues, changes in event names (or bad naming in general), various methods of deduplication in the destination platforms and, of course, any sort of error in instrumentation.
Consistency in tracking user actions (events)
The Starter Stack solves this event fragmentation problem by:
- Abstracting event collection away from the downstream destinations
- Using a single SDK to collect events and identify users
- Using a consistent format for all events and users (this is most commonly achieved using JSON payloads)
If we return to our “Add to cart” event, the result in the Starter Stack is one single event in a standardized format, as opposed to multiple events in different formats:
JAVASCRIPT
Instead of instrumenting multiple SDK and multiple versions of the same event, we instrument one SDK and one, consistent version of the event in every platform:
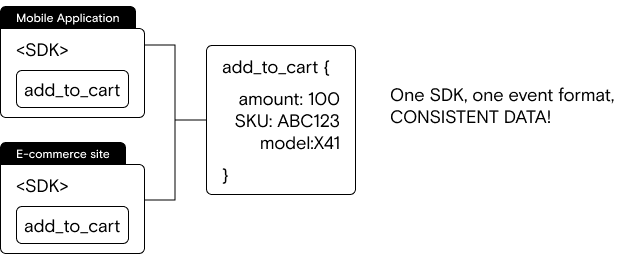
Pro tip: looking at this simple example, it can be tempting to think about building your own SDK and event format, but that rarely works out in the long run: you’re simply trading integration work for SDK work that never ends. We highly recommend using a data tool that provides SDKs and standardized event schemas out of the box—that will allow your team to focus on the data, not building SDKs.
Consistency in tracking user traits
Driving consistency for user traits operates the same way as tracking user actions, the difference is that you are identifying a user.
When a user becomes known (by making a purchase, subscribing to a newsletter, etc.), identifying the user in a consistent format, with the same data, ensures that there’s only one version of the ‘customer record’.
Here’s an example of how you might identify a user:
JAVASCRIPT
How-to: decreasing dev work with an integrations layer
Ok, so we’ve solved for data consistency at the source, but the entire goal of a unified data layer is to make sure all of the downstream tools have the same copy of events and user records. On face value, these single-format payloads are problematic because the APIs for downstream destinations are unique—that’s why you had to run multiple scripts from multiple platforms in the first place.
That’s where the integration layer comes in. Instead of running multiple SDKs and sending events in various formats, you translate the standardized payloads for each destination, meaning each different API is getting the same set of data.
Pro-tip: while standardization makes integration work easier, we also recommend using a third-party data tool that provides an integration layer. APIs change all of the time, so even with standardized payloads, maintenance debt for homegrown integrations can become significant over time.

Bonus: maintaining consistency and fixing data with event transformations
Even if you capture events consistently at the source, there will inevitably be problems. People aren’t perfect, so instrumentation can accidentally be modified in releases, meaning your payloads might have misnamed data points, which will cause problems in downstream destinations.
On the other hand, downstream teams are known for changing things as well—let’s say your marketing team renames a field on the customer record in their email marketing tool and, as a result, your identification payloads don’t update that field anymore.
An event transformation layer helps you avoid these issues by allowing you to modify payloads in-flight on a per-destination basis, without having to go back and deploy code fixes.
So, if your sales team changes a field name in their CRM, you can modify identification payloads to automatically map the correct trait to the updated field name. This means engineers don’t have to modify instrumentation and wait on web or app releases. Plus, fixes are applied only on destinations that need them—the original payload remains unchanged at the source and is delivered as normal to destinations that don’t need transformations applied.
Most importantly, event transformations allow downstream teams to have their cake and eat it too: you can send events with the new taxonomy to fresh analytics setups (i.e., a new Google Analytics property and Mixpanel project), but keep the old destinations and simply transform the new event names to match the old ones. This makes transition periods for analytics possible without any interruption in reporting.
Event transformations help solve point-to-point integration problems where there are differences in things like field names and field data types. Here’s what the event transformation layer looks like:
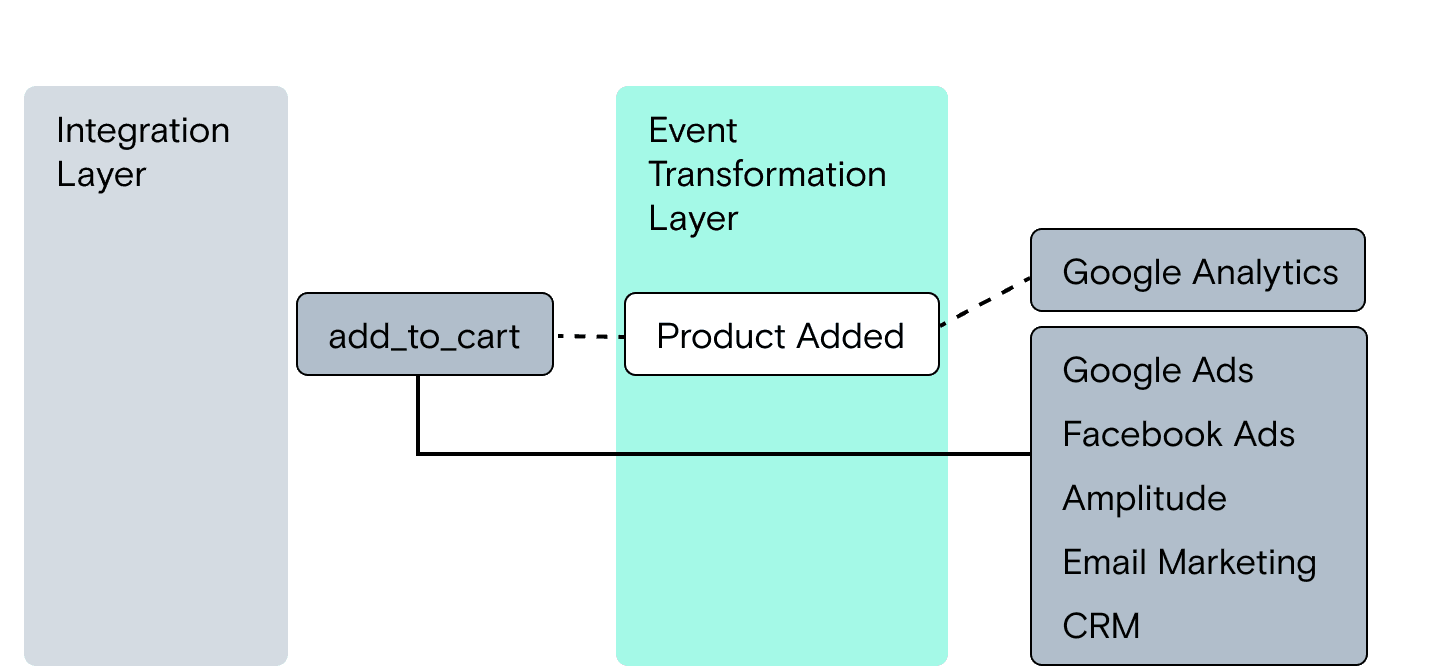
Bringing it all together
When you add an event transformations layer in, here’s what the final Starter Stack architecture looks like:
Tooling and technical review
Though it’s critically important, the Starter Stack doesn’t require a lot of componentry.
Here are the technical pieces you need to implement the Starter Stack:
- One SDK to replace all downstream platform SDKs
- Standardized event format (event schema)
- Standardized user identification format (user schema)
- Integration layer
- Optional but recommended: event transformations functionality
Choosing the right tools for the job
There are plenty of great data tools out there, so how do you decide which ones to use to implement the Starter Stack? Here are a few helpful guidelines:
- Open platforms, as opposed to black-box 3rd-party platforms, will give you deeper visibility into how the tool manages your data
- Flexibility should be king. Even though you want to keep it simple in this stage, your stack will grow in complexity over time. You need a tool that has the flexibility to handle more complex use cases, more technical data tools, and the inevitable list of additional SaaS integrations downstream teams will start using over time
- As customer data infrastructure increasingly becomes the responsibility of data teams, developer-focused features are key as well. Specifically, the ability to integrate that infrastructure into your development workflows and orchestration make managing a complex stack in the future much easier
Features to look for that speak to flexibility and scalability are:
- Robust integrations with core data tools (warehouses, data lakes, in-memory stores, streaming pipelines)
- A large library of SaaS integrations
- The ability to stream events from SaaS applications (like email events from your engagement platform)
- The ability to transform event payloads in-flight
- Webhook sources and destinations for semi-custom integrations
- Dev workflow integrations like:
- The ability to managing your setup in a config file (as opposed to just a UI)
- The ability to manage components of the stack, like event transformations or tracking plans, in version-controlled repos
- The ability to access platform features via API
Outcomes from implementing the Starter Stack
What can you expect after implementing a unified data layer? In short, all of the problems we mentioned above will be solved:
- You’ll finally have clean, rich web and mobile analytics data that is consistent across platforms
- Your conversions will match across ad platforms and, amazingly, match the user and purchase numbers in your eComm platform, email marketing and CRM
- Your analytics will rejoice because they can focus on uncovering insights, not cleaning data
- Your ops team will spend time actually optimizing process within, instead of fighting data fires just to keep the basics running
- Your developers and data engineers can finally focus on delivering true value, as opposed to constantly working on low-level data plumbing problems.
It may sound odd, but when you look at the outcomes, the Starter Stack is almost always the most fundamentally transformative step on the Data Maturity Journey.
When have you outgrown the Starter Stack?
Once you have clean analytics running for marketing and product and teams have the bandwidth to really spend time with the data, they learn more. When they learn more, it follows that they ask more interesting questions. Insights from data create a loop: harder questions require more data to answer (rinse and repeat). Eventually you’ll outgrow your Starter Stack.
On the analytics front, here are a few clear indicators you might be outgrowing the Starter Stack:
- Your SaaS analytics tools are no longer flexible enough to answer your most important questions
- The insights you want require additional data beyond user actions and user traits
Once you hit this point, you’re ready for a data warehouse. Here you can collect all kinds of customer data (in addition to user actions and traits) and perform deeper analysis using SQL or Python. Once you get a data warehouse, you’re ready to start building on top of your Starter Stack and implementing the Growth Stack.
Published:
June 7, 2022



Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
