Real-Time Event Streaming: RudderStack vs. Apache Kafka


Data volume and velocity have grown exponentially since 2015. Consumer expectations have also changed. The introduction of real-time experiences in applications like Uber, Grubhub, Amazon, and Netflix set a new standard for what we expect from digital products. When it comes to marketing, timely, individualized experiences are now table stakes. We’re charging headlong into a future where high-performance personalization and recommendation algorithms aren’t just nice to have – they’re requirements for growth. Real-time data integration has never been more important.
In response to this trend towards low latency, businesses are increasingly seeking robust, efficient data tools and frameworks to support real-time use cases. This emphasis on capturing and responding to data in real-time triggered the rise of event streaming.
"If you asked three years ago whether or not you needed to know exactly when your food was picked up from the restaurant and how close it was to your house, everybody would have gone, like, who really cares? Then COVID hit, and now everybody expects up to the second visibility into where their fried chicken is, right? So, I would argue that real-time isn’t required until someone decides to do it and changes the expectation. Companies like GrubHub and Netflix have changed the expectations."
In this article, we’ll start with the fundamentals of streaming data and discuss the two most common types. Then, we’ll compare Apache Kafka with RudderStack, highlighting where the tools shine.
We’ll also cover how the two tools can complement each other. RudderStack’s Kafka integrations provide reliable connectors that make it easy to get customer data into and out of Kafka. Plus, with RudderStack Profiles, you can unify your Kafka with data from every other source to create complete customer profiles and then send them back to downstream destinations (including Kafka!).
What are two major types of streaming data?
Streaming data is continuously generated. Streaming sources often generate thousands of data points over short periods. It can come from user activity on a website, financial transactions, or telemetry from IoT devices. Unlike traditional data, which is stored and then processed, streaming data is processed on the fly, allowing for real-time insights and decisions.
Time series streaming data
Time-series data architecture focuses on capturing data points at successive time intervals. The primary purpose is to track changes over time, which is crucial for trending, forecasting, and anomaly detection, among other tasks.
For example, a stock market application might use time-series data to track the price of a particular stock at regular intervals throughout the day. Such an application can help identify trends, predict future price movements, or detect unusual trading activity.
Key things to look for in time-series data include:
- Seasonality: Data patterns that repeat at known regular intervals, like an increase in ice cream sales every summer. Streaming tools can adjust for seasonality when creating real-time forecasts.
- Trends: The underlying pattern in the data, such as a gradual increase in a website's monthly visitor numbers. Real-time alerting based on a spike or dip in a trend is a common application for streaming data.
- Noise: The random variation in the data that doesn't contribute to the pattern. Noise can be filtered out in real time using streaming data tools.
Event-driven streaming data
Non-time series streaming data places the primary focus on the events that occur rather than the time passing. While some event-driven stream data could be considered time series data, it can be helpful to think about this data separately because of how it's used. This data type is generated in applications following the Event-Driven Architecture (EDA) design pattern. EDA is a software design pattern that centralizes its actions around creating, detecting, and responding to an application's events or messages. Let's delve into an example of an event-driven data stream.
eCommerce event-driven streaming data
Imagine you own an e-commerce web store. In this scenario, several user actions can generate events – shopping cart additions, order placements (purchases), and review postings are a few examples. These actions trigger events that are essential to various downstream services. Let’s take a look at a customer order, for example.
Customer action: A customer placing an order triggers an “Order Placed" event. This event is self-contained, holding all necessary information like the user ID, order ID, item details, and payment method.
Event streaming: The event gets published to an event stream (a queue holding all events until the corresponding service processes them.)
Event processing: Different microservices listen to the event stream, waiting for events that concern them. In our case, the "Order Placed" event would interest several microservices:
- Inventory management service: checks if the ordered items are in stock and decreases the stock levels accordingly.
- Payment processor: handles the payment transaction after verification the item is in stock.
- Shipping provider: receives the order after payment is processed and the item is in stock.
- Email marketing tool: sends a confirmation email to the customer that the order has shipped.
This architecture allows each service to operate independently, improving the system's scalability and resilience. If one service goes down, it doesn't immediately impact the others. It also allows for real-time or near-real-time processing and response to events, enhancing the user experience.
Apache Kafka – the streaming data pioneer
Apache Kafka shines in its ability to provide a robust, scalable, distributed messaging system grounded in the event stream model. It's like a multi-lane highway that allows cars (or, in this case, events) to enter, continue their journey for a while, and then exit when required. These events can be created, saved for future use, and then used by multiple applications or services that subscribe to these events.
Kafka allows you to publish and subscribe to streams of events, store these events for as long as necessary, and process them in real time. An event in Kafka documents that "something happened." This event, also called a record or message, comprises a key, a value, a timestamp, and optional metadata headers.
Events get stored in topics, which are similar to folders in a filesystem. These topics are partitioned across different Kafka brokers for scalability, allowing client applications to read and write data from/to many brokers simultaneously.
Each event gets appended to a topic's partition, and Kafka ensures that any consumer of a topic partition always reads the events in the order they were written. Every topic can be replicated across different brokers to ensure data fault tolerance and high availability.
Lastly, the Kafka data structure is defined by a schema, commonly crafted in formats like Apache Avro. Before producing data, this schema gets registered with the Schema Registry, which maintains its different versions. When dispatching data to Kafka, it's serialized into bytes and tagged with a schema version reference. While consuming, this reference helps fetch the right schema from the registry, enabling data deserialization. As data needs evolve, the schema can be adapted and re-registered, ensuring compatibility with past versions.
Using Kafka for eCommerce event stream data:
Let’s take our eCommerce example and explore how you might leverage Kafka for event-driven or time series user-generated data ingestion.
First, you need to set up Kafka. Just for a basic non-production setup, you’ll have to (1) download and install Java, (2) set up a cluster by configuring brokers and listeners, (3) install, set up, and start Zookeeper, and (4) start Kafka. Assuming all went well, you then need to configure Kafka for your use case by setting up topics, producers, and consumers for your data stream. Lastly, you will need to integrate your data stream from your data source.
Remember, Kafka consumes data streams but doesn’t directly collect data for you. To collect data from your eCommerce website, you must write a custom event collector or use a prebuilt solution (more on this approach later) that supports Kafka as a destination.
With Kafka set up and your event stream connected, here’s how we’ll collect user behavior data from our e-commerce website:
- When a user interacts with the e-commerce platform, each action, such as browsing products, adding items to their cart, or making a purchase, generates a click event. These click events are captured and sent to Kafka producers.
- These click events are published by Kafka producers to a specific topic, such as "clickstream_topic," within the Kafka cluster. Each event contains details like the user ID, timestamp, clicked item, and any additional relevant metadata.
- Kafka brokers receive and store the click events within partitions of the "clickstream_topic." The partitions ensure scalability and fault tolerance, allowing multiple consumers to process the data in parallel.
- Kafka consumers, such as real-time analytics or personalization services, subscribe to the "clickstream_topic" and consume click events as they arrive. These services analyze the clickstream data in real time to generate insights, recommendations, or personalized content.
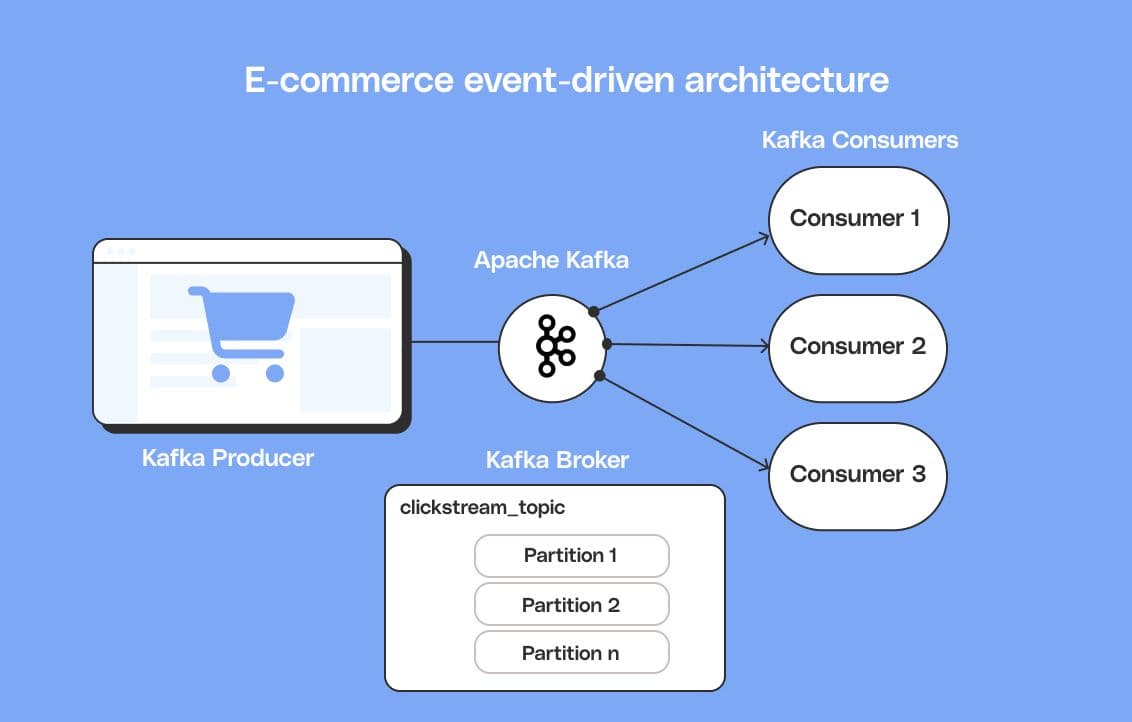
Kafka can enable this e-commerce platform to handle a large volume of real-time events, ensure data consistency, and enable seamless coordination between various services.
Kafka’s challenges and limitations
Kafka and the low-level tool paradox
While Kafka has great versatility, it's a low-level tool that doesn't directly address business problems. To extract value from Kafka, client applications must perform data read and write operations. But Kafka doesn't prescribe how this should be done. It prioritizes flexibility to accommodate diverse use cases, leaving the client applications to figure out how best to use its flexible APIs.
Kafka administration and maintenance
Like many all-purpose open-source tools, Kafka has inherent complexities that make its implementation and maintenance challenging. Operating Kafka involves engineering tasks that require specialized knowledge and effort that may not be part of a typical data engineer’s background. Just as managing a large-scale relational database may warrant hiring a database admin team, Kafka, too, demands a dedicated set of professionals.
After hiring your team, your Kafka administrators must grapple with tough design decisions, like defining how messages are stored in partitioned topics, setting retention policies, and managing team or application quotas. This process is akin to designing a database schema but multiplying the complexity with the added time dimension.
Other challenges with Kafka
Kafka has a few additional limitations that can hinder its effectiveness for certain use cases. For instance, on-the-fly transformation is challenging, and its details are left to you. Also, while Kafka allows persisting events, it presents scaling challenges constrained by disk space, servers, and ongoing data migrations.
Kafka was originally designed for on-premise storage and compute, so its deployment on the cloud is an additional hurdle. Furthermore, Kafka is not built for handling batch data efficiently, so you must ensure you don’t overload brokers with large-scale batch reads.
While Apache Kafka is a powerful open-source data streaming platform, it’s not the ideal solution for every scenario. It offers high throughput and scalability but is a complex solution requiring specialized engineering knowledge. Lastly, it doesn’t have first-class support for the actual data collection, so you’ll need another tool for that.
Hosted Kafka
You don’t have to host Kafka yourself – there are several options for avoiding some but not all of the administration of Kafka. Confluent Cloud is one of the more popular options. Confluent even has some built-in connectors, but most are for low-level infrastructure destinations.
If you choose a hosted version of Kafka, you will still face several challenges:
- User-defined schemas – you must architect and manage the data schemas yourself.
- Batch data loading constraints.
- Data collection from streaming data sources – requires you to write custom code or buy another tool.
- Error handling – Although Confluent has an integration with Snowflake, they don’t have a dead-letter queue. This means errors can either pass through or all data stops until an error is fixed.
- Monitoring and data transformation (we will come to this in the next section).
Streaming data with RudderStack
For many use cases, the truth is you don’t need Kafka. When it comes to customer data, specifically, RudderStack is an excellent solution that handles the ingestion, routing, and delivery of customer behavioral data.
RudderStack is a warehouse native customer data platform (CDP) that helps businesses collect, unify, and activate data from various sources. One of the key features of RudderStack is its ability to stream and transform event data in real time.
The fundamental difference between RudderStack and Kafka is that while Kafka is a low-level tool, RudderStack is a domain-specific platform. It’s built to simplify customer data management while still giving data teams robust controls. RudderStack’s platform approach delivers out-of-the-box features that address many of the challenges you’ll encounter with Kafka:
- Real-time transformations – RudderStack allows you to use Python or JavaScript to transform data in real time. These transformations can help you drop data you don’t need to save money in your downstream tools, mask PII, and enrich information in real-time, along with many other uses.
- Event ingestion – RudderStack has several SDKs for client and server-side event collection, allowing you to customize what you collect from your web app, marketing website, or mobile app.
- Error handling – RudderStack error handling allows for a (DLQ) dead letter queue where problematic data can be queued for review while not delaying good data from continuing to flow to downstream tools.
- Observability – RudderStack gives you real-time visibility using Grafana so you can know exactly what is going on.
- Event Schemas – RudderStack has predefined event schemas based on industry best practices for hundreds of popular sources and destinations. These schemas save you from manually creating schemas for your source or destination.
RudderStack data streams
RudderStack can handle both time series and event stream data processing and ingestion as well as real-time transformations.
- Time-series data: RudderStack can collect and ingest time series data such as user behavior data, customer attribution data, and clickstream data. This data can be collected via a snippet of code that runs on your website. A typical use case is collecting data from a marketing website inside a SaaS app or eCommerce store.
- Server Event stream data: RudderStack can also collect server-side event stream data. This data is often sent from an application's webhook. RudderStack has a native integration with many webhooks (like Shopify for things like add to cart and purchase complete). It also features a generic webhook integration that accepts inbound events from any source you choose.
After the data is received and transformed (if necessary), RudderStack can send data to popular tools via native integrations with tools already in your ecosystem, such as CRMs (Salesforce, Hubspot, etc.), Marketing (Customer.io, Braze, Klaviyo, etc.), and many other tools. RudderStack also has the flexibility to send data to your data warehouse asynchronously (in batches), so you can use SQL to analyze historical data.
Using RudderStack for eCommerce event stream data
Here’s how you would tackle a similar use case to the one we covered previously with Kafka in RudderStack:
- Create a new event stream source in RudderStack. The JavaScript SDK is the most popular, and the installation process is similar to installing a Google Analytics or Hubspot pixel. Some platforms (such as Shopify) will have an app you can install. Install the SDK in your marketing or eCommerce websites' frontend code in the header section that runs on every page.
- Set up server-side events using the Shopify app or your e-commerce or marketing website's webhooks to send data to a RudderStack webhook source. These server-side events could be “payment processed,” “fraud review complete,” or any number of other events.
- Create a transformation using the built-in JavaScript transformer. You can filter out traffic or events that are not relevant, saving downstream storage and data processing costs. You can also hash sensitive PII data such as social security numbers or email addresses.
- Activate your data by streaming it to your email marketing tool, Google ads, or another destination using an outbound webhook.
Processing other types of data with RudderStack
Not all data needs to be streaming data. RudderStack can also process batch data to your data warehouse and other tools that don’t need real-time data. This capability is helpful when your destination doesn’t need or doesn’t support real-time data.
Using RudderStack and Kafka together
RudderStack can also work in concert with Kafka. RudderStack’s Kafka integrations provide reliable connectors that make it easy to get customer data into Kafka or move data from Kafka into all your downstream tools – including your data warehouse or data lake – without the burden of building and maintaining custom integrations.
RudderStack’s customer 360 solution, Profiles, brings even more value to the table. With Profiles, you can unify data from Kafka and every other source in your warehouse to create complete customer profiles and then send them back to downstream destinations (including Kafka!) for activation.

RudderStack Kafka destination integration
If you already have Kafka set up and connected to many downstream destinations, you can use RudderStack as an ingestion mechanism to collect customer data from every website and application and send it to Kafka. You can also use RudderStack to unload your Kafka data in your data warehouse, like Google BigQuery, Snowflake, Amazon AWS Redshift, or Postgresql. This can be helpful for future analysis and troubleshooting using the data streamed by Kafka.
The RudderStack Kafka destination provides a seamless way to stream your customer event data into Apache Kafka topics. By configuring your Kafka connection settings in the RudderStack interface, you can start piping event data like page views, clicks, purchases, and more into your Kafka infrastructure. RudderStack natively supports sending events to existing topics and dynamically mapping events to new topics based on the event type or name. This makes it easy to organize and consume your data in Kafka.
A major benefit of the integration is its ability to serialize your event data into Avro format before publishing to Kafka. By defining schemas and configuring Avro serialization in RudderStack, you can overcome the challenges of schema evolution and compatibility that often accompany streaming data architectures. RudderStack will convert your events to Avro and publish them to the desired topics based on the schema configuration. This unlocks the advantages of Avro, like efficient serialization, versioning, and schema evolution when building stream processing pipelines with Kafka.
RudderStack Kafka Source Integration
RudderStack offers a way to directly ingest data from Kafka topics. By leveraging a custom Java service that consumes messages from Kafka, businesses can forward that data to RudderStack over HTTP API without making any changes to their infrastructure. This is ideal for customers who already have Kafka deployed internally, as it does not require network access or modifications to begin routing Kafka data.
RudderStack handles translating the messages from Kafka into customer events that can then get passed to downstream destinations. This RudderStack Java service for Kafka enables businesses to activate customer data from their Kafka pipelines to various valuable destinations for customer data that aren’t covered by services like Confluent. For companies leveraging Kafka, RudderStack's custom Java service provides an appealing way to ingest data without disruptive changes.

When to use RudderStack vs. Kafka
Kafka is valuable if you need a flexible distributed messaging system that excels at event streaming and handling large volumes of real-time data. It shines in complex environments where multiple services must independently consume and process the same data stream. If your operations involve managing large-scale databases and you can dedicate resources for Kafka's administration and maintenance, then Kafka is your tool.
RudderStack, on the other hand, is an excellent choice for businesses that are looking for a streamlined solution to collect, unify, and activate customer data from various sources to various destinations without Kafka's complexities. RudderStack is a more suitable tool if your primary requirement is to handle event stream data and perform real-time transformations, and you don’t need to handle an extensive microservices architecture. Furthermore, RudderStack's out-of-the-box integrations with popular tools and ability to handle batch data efficiently make it a versatile solution for many use cases.
So, when should you use RudderStack vs. Kafka? Here’s a breakdown by a few key features.
Flexibility
- Use RudderStack when you need a flexible tool to collect, unify, and activate your customer data.
- Use Kafka when you need ultimate flexibility for your streaming needs – like building an ETL platform.
Admin & maintenance
- Use RudderStack to avoid unnecessary admin/maintenance. You’ll also get schema management, better error handling, and event ingestion.
- Use self-hosted Kafka if you need maximum flexibility and have the staff for admin and maintenance. Use cloud-hosted Kafka for automated maintenance.
Data source and destination integrations
- Use RudderStack if you would benefit from a wide range of out-of-the-box integrations that include SDKs and webhooks.
- Use Kafka if you need low-level integrations for massive amounts of data that even APIs would not handle well. Hosted versions of Kafka have some connectors, but most are for low-level systems.
Batch & Real-Time
- RudderStack handles batch and real-time workloads well.
- Kafka could run into issues handling batch and real-time workloads together.
Ease of use
- RudderStack is simple but powerful
- Kafka is complex and powerful
Platform
- RudderStack is managed (SaaS)
- Kafka is self-managed or Saas via third-party
The key takeaway
In the era of real-time experiences, the need for robust and efficient data streaming tools has grown significantly. When comparing RudderStack and Apache Kafka, both offer unique benefits depending on your use cases and requirements, but the choice is not necessarily either/or.
Apache Kafka excels in handling large volumes of real-time data, and it provides an extremely flexible distributed messaging system. However, it’s a complex platform that requires a dedicated set of professionals for administration and maintenance. Choose Kafka if you are building a SaaS software platform and need full control and flexibility.
RudderStack provides a streamlined solution enabling real-time streaming and transformation of event data. It offers over 200 out-of-the-box integrations, efficiently handles batch data, and doesn't require complex administrative tasks. Rudderstack is for you if you are ingesting event stream data and want to:
- Easily ingest event data via SDKs or webhooks
- Transform your data in real-time
- Send your data to downstream cloud tools (Salesforce, Braze, and Intercom)
- Store your data in a data warehouse (Snowflake, BigQuery, DataBricks) for historical analysis using SQL
RudderStack and Kafka make an excellent pair if you’re using Kafka and need a reliable solution for customer data integration, unification, and distribution. Our SDKs and Webhook sources make event data ingestion for Kafka easy, our Profiles product enables you to unify data from Kafka with data from every other source in your own warehouse, and our large destination integration library makes it easy to get data from Kafka into every tool in your customer data stack.
Try RudderStack Event Stream today
Sign up free and start streaming data with RudderStack in less than 5 minutes.
Published:
July 28, 2023

Event streaming: What it is, how it works, and why you should use it
Event streaming allows businesses to efficiently collect and process large amounts of data in real time. It is a technique that captures and processes data as it is generated, enabling businesses to analyze data in real time


How Masterworks built a donor intelligence engine with RudderStack
Understanding donor behavior is critical to effective nonprofit fundraising. As digital channels transform how people give, organizations face the challenge of connecting online versus offline giving.


How long does it take you to see a customer event? If it's over five seconds, you're missing out
Access to real-time customer data is no longer a luxury. This article explains how a modern, modern, real-time infrastructure can help you close the gap between customer intent and action—before it’s too late.



