Blog
Data agents need context graphs. Can your data pipelines cater?
Data agents need context graphs. Can your data pipelines cater?

Nishant Sharma
Technical Director
10 min read
April 28, 2026

Decision traces are just events. The infrastructure to handle them already exists.
Part 3
Part 1 of this series showed why incrementality is harder than it looks, and why tools built for time-grained analytics break on entity-grained activation pipelines. Part 2 argued that the deeper problem is what agents produce: SQL is the wrong output target, and a semantic intent compiler is the missing layer.
This post picks up where Part 2 left off. The data community has converged on context graphs as what AI agents need to consume. This post asks the question nobody is answering: once agents have that context, how do they act on it safely?
A new consensus is forming in the data and AI community. In December 2025, Jaya Gupta and Ashu Garg posited that the next generation of durable platforms will be systems that capture decision traces: the exceptions, approvals, precedents, and reasoning buried in Slack threads, email chains, and approval workflows. Writing in Metadata Weekly, Jessica Talisman draws a sharp line between semantic layers, which are built for analysis and metric governance, and ontologies, which are built for reasoning, helping systems understand domains well enough to make inferences and support decisions. The emerging direction: AI agents need context graphs built from these traces, not just metric definitions.
That direction is right. But the discourse is focused entirely on input.
The question it leaves unanswered is the one that matters most for production systems: Once agents have access to a rich context graph, what should they produce, and how do you make that production safe and deterministic at scale?
I believe the answer starts with a realization that reframes the whole problem: Decision traces are just events.
Decision traces are just events
The data industry has spent 15 years building infrastructure to handle behavioral events: clicks, page views, purchases, feature usage. The problems of ingestion, schema discovery, identity resolution, warehousing, and activation are largely solved.
Decision traces are a different source, but they share the same nature. An exception granted by a VP in a Slack thread is an event. A policy update in an approval workflow is an event. A precedent cited during a contract negotiation is an event. Different channel, same data infrastructure DNA.
That insight matters because it means the extension is natural. You do not need a new category of infrastructure to handle context graphs. You need to recognize that the infrastructure you already have applies.
The infrastructure DNA they share
Decision traces and behavioral events share four properties. Each one maps onto existing, proven infrastructure patterns.
Emergent schemas, not upfront design
Behavioral event schemas are not designed in a lab. They emerge as products evolve. When a team ships a new feature, new event types appear: feature_engaged, feature_upgraded. Your event infrastructure adapts without requiring a schema redesign.
Decision traces work the same way. When an LLM extracts decision traces from Slack threads, new trace types emerge: discount_approved, exception_granted, precedent_cited. The ontology of organizational knowledge builds organically, exactly as event schemas do.
This means you do not need to design a complete ontology upfront. You need infrastructure that handles emergent structure, which is exactly what event pipelines already do.
Identity resolution
Behavioral events need identity resolution to answer: Which user did this action? Decision traces need a richer version of the same thing.

LLM Extracts Diagram
When an LLM extracts a trace from a Slack message, the raw output might read: Approver is "VP Jane," customer is "Acme Corp," precedent is "Q3 deal." Before that trace is useful, those references need resolution: "VP Jane" becomes Person:jane_doe_123, "Acme Corp" becomes Account:acme_456, "Q3 deal" becomes Decision:q3_discount_789. Only then is the trace queryable, joinable, and composable with the rest of the graph.
This is ID stitching applied to a harder extraction problem. The pattern is the same. The inputs are messier. Entity extraction from natural language is more probabilistic than matching a cookie ID, but it is not a different architecture. It is another transformation step in the same pipeline.
Warehouse-native storage
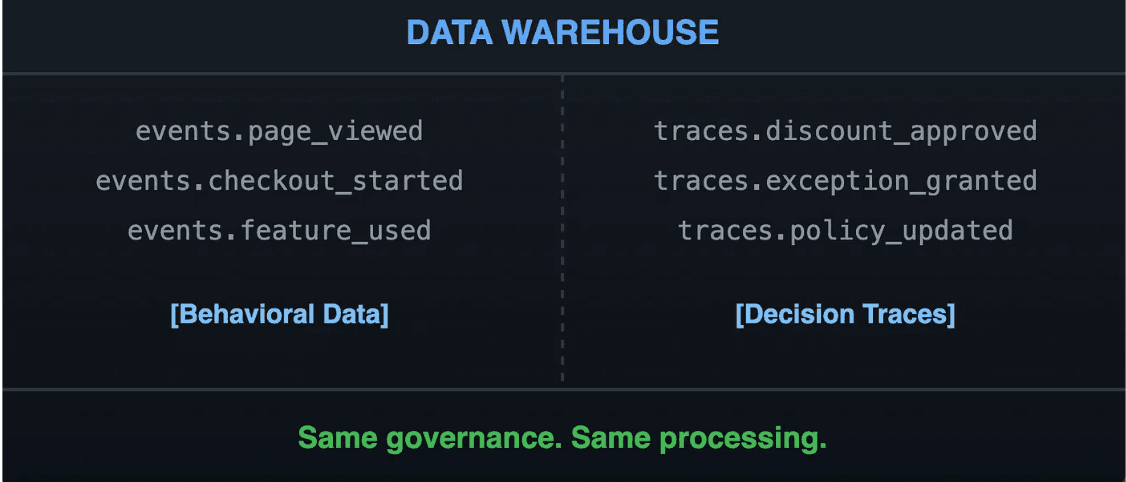
Data warehouse: Behavioral data and decision traces
Behavioral events land in the warehouse: same governance, same compliance, same processing infrastructure. Decision traces should land there, too, not only in a separate specialized store.
This matters for a practical reason. Decision traces only become valuable when they can be joined with behavioral data: when a discount approval can be connected to the account's purchase history, when a policy exception can be joined to the segment it affects, when a precedent can be linked to the entity it concerns. That joining happens naturally in the warehouse. It requires custom integration work in any other architecture.
What about graph databases?
The knowledge graph community often gravitates toward specialized graph stores (Neo4j, RDF triple stores). There’s a case for native graph traversal. But for enterprise activation — where traces need to join with behavioral data, respect the same governance, and feed the same downstream systems — warehouse-native storage has natural affinity. Vectors can live in the warehouse, too. The question isn’t “graph DB vs. warehouse” but “what needs to join with what?”
What about privacy?
Decision traces contain sensitive information, including who approved what, internal reasoning, exceptions. This isn’t a new problem. Your warehouse already has PII detection, consent management, retention policies, and audit trails. Warehouse-native traces inherit all of it. No need to rebuild privacy infrastructure in a separate store.
What about cost and latency?
Processing every Slack thread in real-time sounds expensive, and it is — if you try to do it that way. But event infrastructure already solved this: incremental updates, not full reprocessing. The Compiler doesn’t re-extract every trace on every run. It processes deltas. High-signal sources (approval workflows, formal exceptions) get priority; low-signal noise gets batched. Same pattern as behavioral events. Not a new problem.
Activation-driven
Behavioral events are inert until they drive action: synced to a CRM, triggering a campaign, personalizing a product experience. A context graph sitting in a warehouse without an activation layer is just an expensive audit log.
Decision traces are the same. The value is not in storing them. It is in what agents can do with them: routing an exception to the right approver based on precedent, triggering a retention workflow when a risk threshold is crossed, updating a customer profile based on a decision that affects their account.
Activation is the point where context graphs become agentic infrastructure rather than a sophisticated archive.
The gap: Raw facts are inert
Here is where the current discourse stops short.
The emerging consensus is right that agents need context graphs, decision traces, and ontologies. But all of that thinking is focused on what agents consume. It does not address what agents should produce, or how to make that production safe.
If an agent outputs raw SQL against a warehouse, even a warehouse rich with decision traces and ontological structure, three problems from Part 2 remain unchanged.
- No incrementality: the agent has no memory of what was computed yesterday. It reprocesses the full context graph on every run.
- No governance: knowing that a policy exists does not enforce it. The agent can still query fields it should not touch.
- No determinism: the same context graph, queried on different days, can produce different SQL and different outputs.
There is also a sharper version of this problem specific to agentic action. For queries and dashboards, 95% accuracy is useful. For actions, such as updating a CRM record, routing an approval, or triggering a campaign, 95% accuracy is effectively 100% failure. Context graphs give agents the knowledge to reason well. They do not by themselves provide the execution layer that makes actions reliable.
The Semantic Intent Compiler: Context graphs as fuel, compiler as engine
Part 2 introduced the Semantic Intent Compiler as the missing layer between probabilistic agent and deterministic execution. The same architecture is what turns a context graph from an audit log into agentic infrastructure.
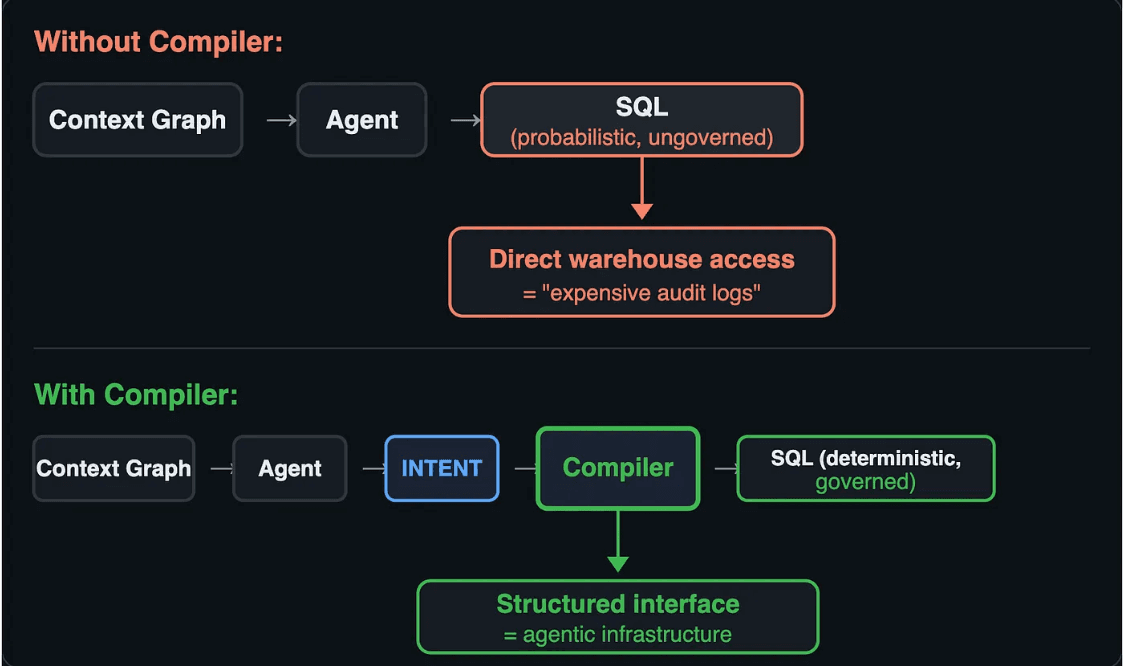
With and without the Semantic Intent Compiler
Without the compiler, the flow is: context graph feeds the agent, agent outputs SQL, SQL hits the warehouse directly. The context makes the agent better informed. It does not make the output governed or deterministic.
With the compiler, the agent expresses structured intent instead of SQL. The compiler transforms that intent into execution with three guarantees: incremental (only recompute what changed), governed (policies enforced at compile time, not as suggestions), and deterministic (same intent plus same state equals the same SQL, every time).
What this looks like in practice
Consider an agent that receives a discount request exceeding policy limits. It needs to find relevant precedents, identify the right approver, and route the request with full context. Without the compiler, this requires the agent to generate SQL against the context graph, navigate ontological relationships manually, and hope the output is correct and compliant.
With the compiler, the agent declares intent:
YAML
The agent never writes SQL. It declares what it wants. The compiler handles the graph traversal, the joins, the incremental updates to the audit trail, and the governance constraints. The agent stays at the semantic level. The compiler handles the execution.
The feedback loop: Context graphs that compound
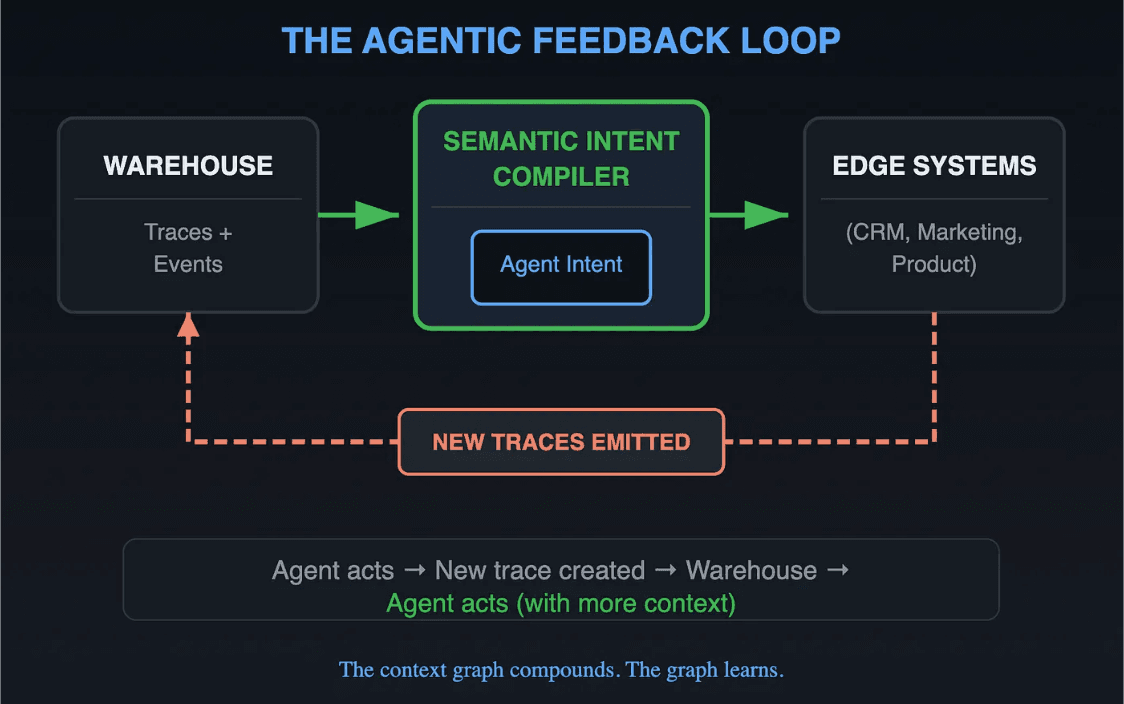
Agentic Feedback Loop
This is where context graphs become a living system rather than a static artifact.
Every agent action creates new decision traces. An agent approves a discount and a trace.discount_approved event is emitted. An agent routes an exception and a trace.exception_routed event is written. Those traces flow back into the warehouse. They get ID-stitched to existing entities. They become available for future queries.
The context graph compounds. Every action adds context for the next one. Precedents become searchable. Exceptions become patterns. The agent that routes the next discount request has richer context than the one that routed the last, because the last routing itself became a data point.
This feedback loop is what separates a context graph from a one-time knowledge base. It is also only possible with the compiler in the middle: Without it, each agent action is stateless, and the traces it produces do not feed back into a shared, incrementally maintained graph. They are isolated outputs with no memory.
Context graphs are the fuel. The compiler is the engine.
Context graphs are the right direction. Decision traces, ontologies, richer agent context: The community is converging on real infrastructure needs.
The reframe this post offers is that decision traces are just events. They need emergent schema handling, identity resolution, warehouse-native storage, and activation, exactly what behavioral event pipelines already provide. The infrastructure exists. The extension is natural.
But capturing traces is only half the problem. Raw facts in a warehouse, however richly structured, are expensive audit logs until an agent can act on them safely. That requires the compiler: the layer that sits between probabilistic agent and deterministic execution, enforces governance by construction, and maintains the incremental state that makes the feedback loop possible.
Context graphs are the fuel. The Semantic Intent Compiler is the engine.
The next post in this series will go inside the compiler: how this.DeRef() works under the hood, the dependency graph model, and how incremental computation actually executes across a graph that includes both behavioral events and decision traces.
Further reading
Explore the RudderStack Profiles documentation to see the Semantic Intent Compiler in practice.
Published:
April 28, 2026
More blog posts
Explore all blog posts
Understanding event data: A guide to behavioral data collection
Danika Rockett
by Danika Rockett

How AI data integration transforms your data stack
Brooks Patterson
by Brooks Patterson

Behavioral segmentation: Examples, benefits, and tools
Brooks Patterson
by Brooks Patterson


Start delivering business value faster
Implement RudderStack and start driving measurable business results in less than 90 days.


