

Don't go through the pain of direct integration.
RudderStack’s Zendesk integration makes it easy to send data from Zendesk to Amazon Redshift and all of your other cloud tools.
For more details, see our Zendesk to Amazon Redshift integration.
Extract your data from Zendesk
Zendesk APIs are not specific to pulling data, Zendesk provides more than a hundred different APIs for you to integrate with. So you can easily manage your users, enhance your team’s productivity and create seamless integrations. You can create integrations or even enrich Zendesk with data from external sources. Zendesk API is a RESTful API that can be accessed through HTTP.
As a RESTful API, interacting with it can be achieved by using tools like CURL or Postman or by using HTTP clients for your favorite language or framework.
A few suggestions:
- Apache HttpClient for Java
- Spray-client for Scala
- Hyper for Rust
- Ruby rest-client
- Python http-client
Additionally, Zendesk offers a number of SDKs and libraries so you can access the API from your framework of choice without having to deal with the technicalities of HTTP. API clients are available for the following languages:
Zendesk API Authentication
Zendesk’s API is an SSL-only API, regardless of how your account is configured. You must be a verified user to make API requests. You can authorize against the API using either basic authentication with your email address and password, with your email address and an API token, or with an OAuth access token.
Zendesk rate limiting
The API is rate-limited. It only allows a certain number of requests per minute depending on your plan and the endpoint. Zendesk reserves the right to adjust the rate limit for given endpoints to provide a high quality of service for all clients. The current limits are the following:
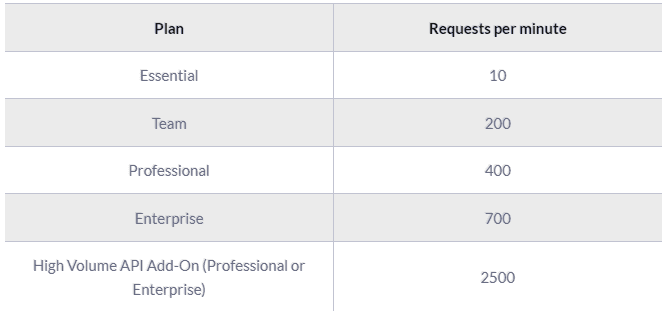
Pagination
By default, most list endpoints return a maximum of 100 records per page. You can change the number of records on a per-request basis by passing a per_page parameter in the request URL parameters. Example: per_page=50. However, you can’t exceed 100 records per page on most endpoints.
When the response exceeds the per-page maximum, you can paginate through the records by incrementing the page parameter. Example: page=3. List results include next_page and previous_page URLs in the response body for easier navigation:
Endpoints and available resources
The Zendesk REST API exposes a large number of resources and endpoints that allow the user to interact with the platform in every possible way. Thus it is possible to create new applications on top of the Zendesk platform, integrate external systems with it,, and of course pull data out of the platform. The most important resources are the following:
- The tickets that your customers create through Zendesk.
- Ticket events. Changes that have occurred to the tickets.
- Organizations.
- Users.
- Ticket metrics. These are metrics related to your tickets.
- Data related to the Net Promoter Score.
- Articles
Let’s assume that we want to pull all the tickets we have on Zendesk. To do that we need to perform a GET request to the appropriate end-point, like this:
JAVASCRIPT
JAVASCRIPT
And a sample response:
JAVASCRIPT
A complete ticket object might contain the following fields:
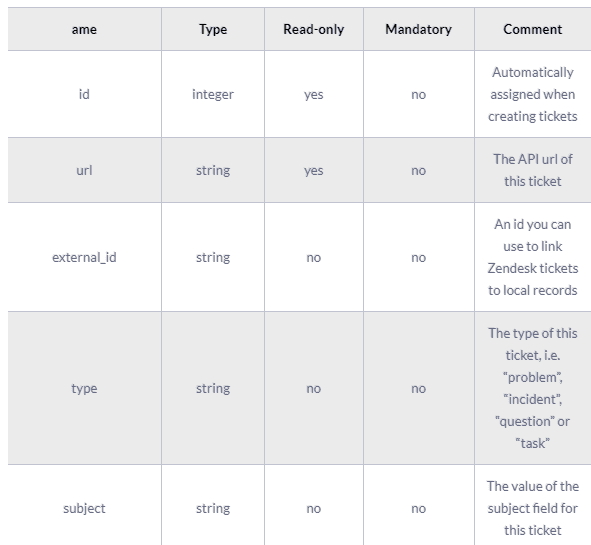
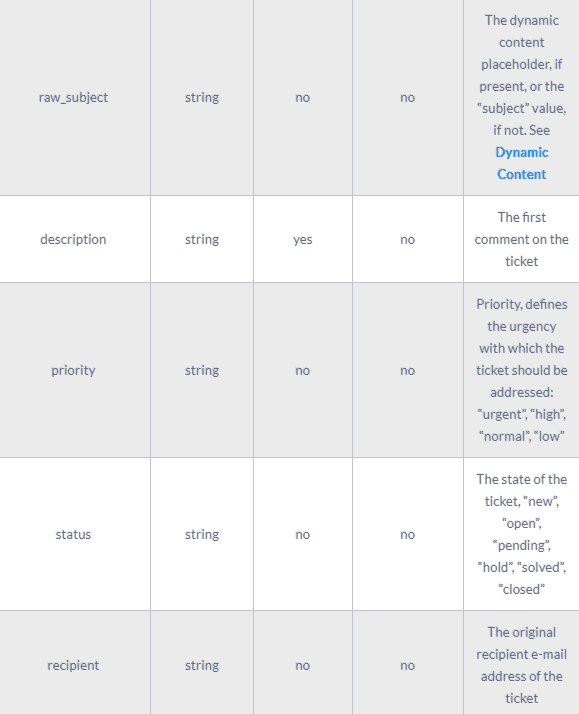
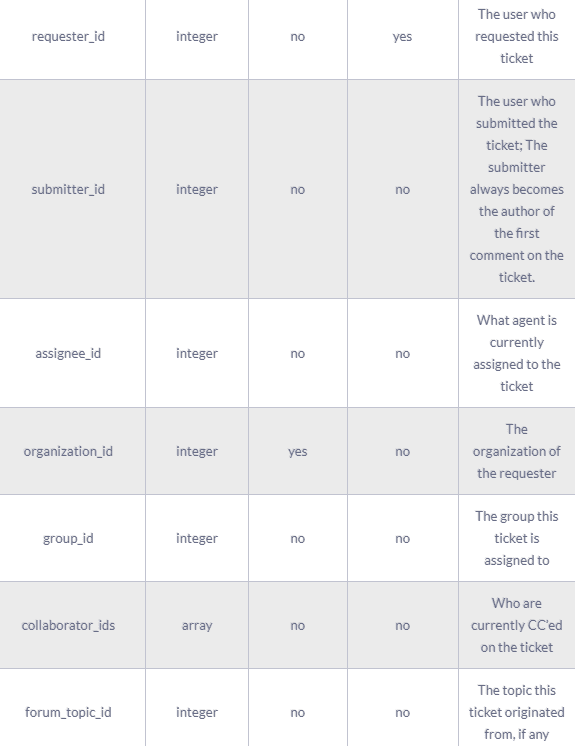
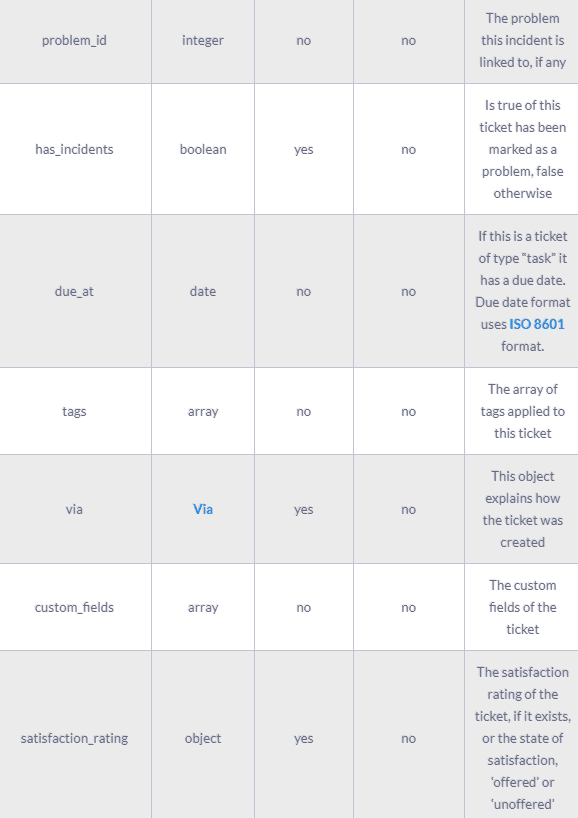
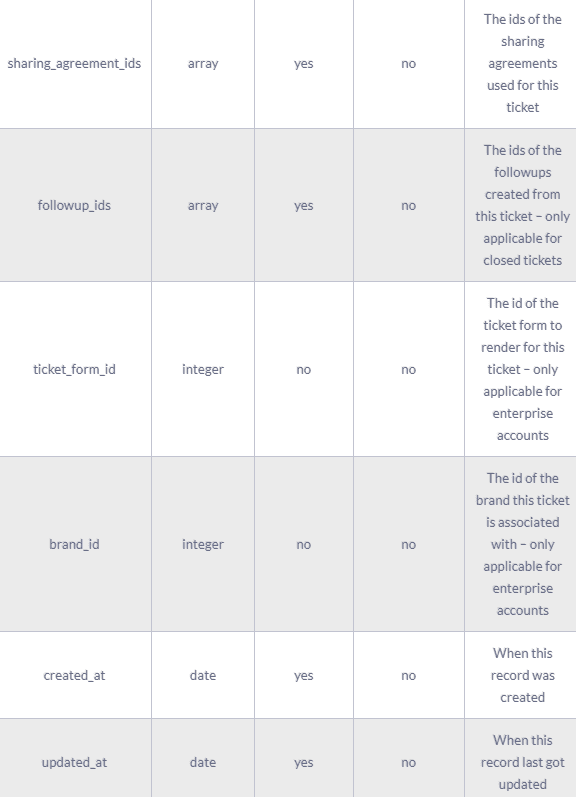
The results of the Zendesk API are always in JSON format. The API offers you the opportunity to get very granular data about your accounting activities and use it for analytics and reporting purposes.
Prepare your Zendesk Data for Amazon Redshift
Amazon Redshift is built around industry-standard SQL with added functionality to manage very large datasets and high-performance analysis. So, to load your data into it, you will have to follow its data model which is a typical relational database model. The data you extract from your data source should be mapped into tables and columns. Where you can consider the table as a map to the resource you want to store and columns the attributes of that resource. Also, each attribute should adhere to the data types that are supported by Redshift, currently, the data types that are supported are the following:
- SMALLINT
- INTEGER
- BIGINT
- DECIMAL
- REAL
- DOUBLE PRECISION
- BOOLEAN
- CHAR
- VARCHAR
- DATE
- TIMESTAMP
As your data are probably coming in a representation like JSON that supports a much smaller range of data types you have to be really careful about what data you feed into Redshift and make sure that you have mapped your types into one of the datatypes that is supported by Redshift. Designing a Schema for Redshift and mapping the data from your data source to it is a process that you should take seriously as it can both affect the performance of your cluster and the questions that you can answer. It’s always a good idea to have in your mind the best practices that Amazon has published regarding the design of a Redshift database. When you have concluded on the design of your database you need to load your data on one of the data sources that are supported as input by Redshift, these are the following:
Load data from Zendesk to Redshift
The first step to load your Zendesk data to Redshift is to put it in a source that Redshift can pull it from. As it was mentioned earlier there are three main data sources supported, Amazon S3, Amazon DynamoDB, and Amazon Kinesis Firehose, with Firehose being the most recent addition as a way to insert data into Redshift.
To upload your data to Amazon S3 you will have to use the AWS REST API, as we see again APIs play an important role in both the extraction but also the loading of data into our data warehouse. The first task that you have to perform is to create a bucket, you do that by executing an HTTP PUT on the Amazon AWS REST API endpoints for S3. You can do this by using a tool like CURL or Postman. Or use the libraries provided by Amazon for your favorite language. You can find more information by reading the API reference for the Bucket operations on Amazon AWS documentation.
After you have created your bucket you can start sending your data to Amazon S3, using again the same AWS REST API but by using the endpoints for Object operations. As in the Bucket case you can either access the HTTP endpoints directly or use the library of your preference.
DynamoDB imports data again from S3, it adds another step between S3 and Amazon Redshift so if you don’t need it for other reasons you can avoid it.
Amazon Kinesis Firehose is the latest addition as a way to insert data into Redshift and offers a real-time streaming approach into data importing. The necessary steps for adding data to Redshift through Kinesis Firehose are the following:
- create a delivery stream
- add data to the stream
Whenever you add new data to the stream, Kinesis takes care of adding these data to S3 or Redshift, again going through S3, in this case, is redundant if your goal is to move your data to Redshift. The execution of the previous two steps can be performed either through the REST API or through your favorite library just as in the previous two cases.
The difference here is that for pushing your data into the stream you’ll be using a Kinesis Agent.
Amazon Redshift supports two methods for loading data into it. The first one is by invoking an INSERT command. You can connect to your Amazon Redshift instance with your client, using either a JDBC or ODBC connection and then you perform an INSERT command for your data.
JAVASCRIPT
The way you invoke the INSERT command is the same as you would do with any other SQL database, for more information you can check the INSERT examples page on the Amazon Redshift documentation.
Redshift is not designed for INSERT-like operations, on the contrary, the most efficient way of loading data into it is by doing bulk uploads using a COPY command. You can perform a COPY command for data that lives as flat files on S3 or from an Amazon DynamoDB table. When you perform COPY commands, Redshift is able to read multiple files simultaneously and it automatically distributes the workload to the cluster nodes and performs the load in parallel. As a command COPY is quite flexible and allows for many different ways of using it, depending on your use case. Performing a COPY on Amazon S3 is as simple as the following command:
JAVASCRIPT
For more examples on how to invoke a COPY command, you can check the COPY examples page on Amazon Redshift documentation. As in the INSERT case, the way to perform the COPY command is by connecting to your Amazon Redshift instance using a JDBC or ODBC connection and then invoke the commands you want using the SQL Reference from Amazon Redshift documentation.
The best way to load data from Zendesk to Amazon Redshift and possible alternatives
So far, we just scraped the surface of what can be done with Amazon Redshift and how to load data into it. The way to proceed relies heavily on the data you want to load, from which service they are coming from, and the requirements of your use case. Things can get even more complicated if you want to integrate data coming from different sources.
A possible alternative, instead of writing, hosting, and maintaining a flexible data infrastructure, is to use a product like RudderStack that can handle this kind of problem automatically for you.
RudderStack integrates with multiple sources or services like databases, CRM, email campaigns, analytics, and more. Quickly and safely move all your data from Zendesk to Redshift and start generating insights from your data.
Sign Up For Free And Start Sending Data
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app.
Don't want to go through the pain of direct integration? RudderStack's Zendesk integration makes it easy to send data from Zendesk to Amazon Redshift.