

Don't go through the pain of direct integration.
RudderStack’s Zendesk integration makes it easy to send data from Zendesk to Google BigQuery and all of your other cloud tools.
For more details, see our Zendesk to Google BigQuery integration.
Extract your data from Zendesk
Zendesk APIs are not specific to pulling data. Zendesk provides more than a hundred different APIs for you to integrate with. So you can easily manage your users, enhance your team’s productivity and create seamless integrations. You can create integrations or even enrich Zendesk with data from external sources. Zendesk API is a RESTful API that can be accessed through HTTP. As a RESTful API, interacting with it can be achieved by using tools like CURL or Postman or by using http clients for your favorite language or framework.
A few suggestions:
- Apache HttpClient for Java
- Spray-client for Scala
- Hyper for Rust
- Ruby rest-client
- Python http-client
Additionally, Zendesk offers a number of SDKs and libraries so you can access the API from your framework of choice without having to deal with the technicalities of HTTP. API clients are available for the following languages:
Zendesk API Authentication
Zendesk’s API is an SSL-only API, regardless of how your account is configured. You must be a verified user to make API requests. You can authorize against the API using either basic authentication with your email address and password, with your email address and an API token, or with an OAuth access token.
Zendesk rate limiting
The API is rate-limited. It only allows a certain number of requests per minute depending on your plan and the endpoint. Zendesk reserves the right to adjust the rate limit for given endpoints to provide a high quality of service for all clients. The current limits are the following:
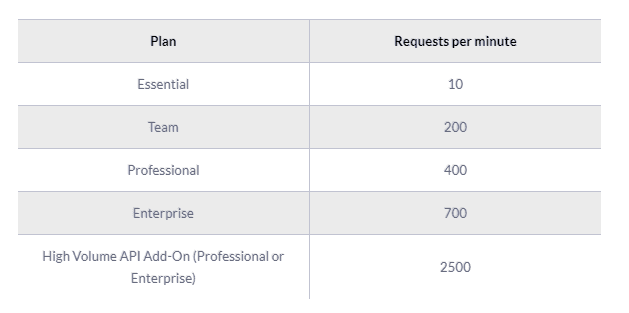
Pagination
By default, most list endpoints return a maximum of 100 records per page. You can change the number of records on a per-request basis by passing a per_page parameter in the request URL parameters. Example: per_page=50. However, you can’t exceed 100 records per page on most endpoints.
When the response exceeds the per-page maximum, you can paginate through the records by incrementing the page parameter. Example: page=3. List results include next_page and previous_page URLs in the response body for easier navigation:
JAVASCRIPT
Endpoints and available resources
The Zendesk REST API exposes a large number of resources and endpoints that allow the user to interact with the platform in every possible way. Thus it is possible to create new applications on top of the Zendesk platform, integrate external systems with it, and of course, pull data out of the platform. The most important resources are the following:
- The tickets that your customers create through Zendesk.
- Ticket events. Changes that have occurred to the tickets.
- Organizations.
- Users.
- Ticket metrics. These are metrics related to your tickets.
- Data related to the Net Promoter Score.
- Articles
Let’s assume that we want to pull all the tickets we have on Zendesk. To do that we need to perform a GET request to the appropriate end-point, like this:
HTML
JAVASCRIPT
And a sample response:
JAVASCRIPT
A complete ticket object might contain the following fields:
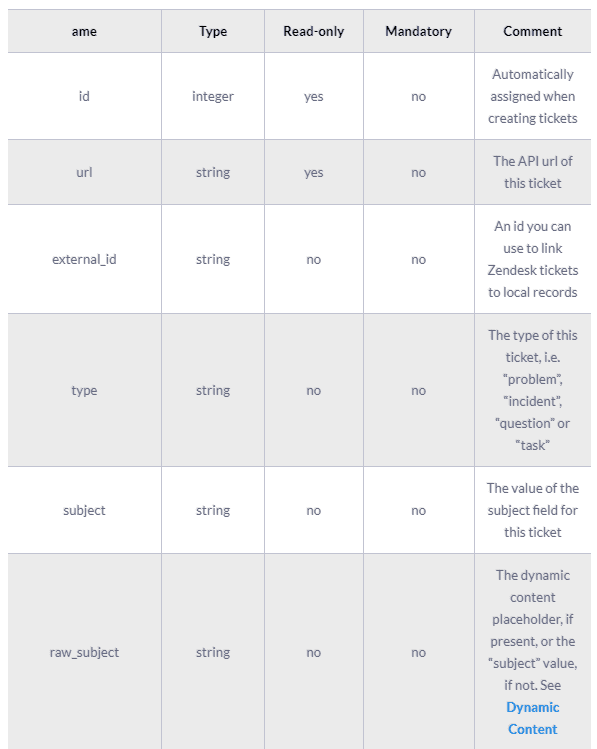
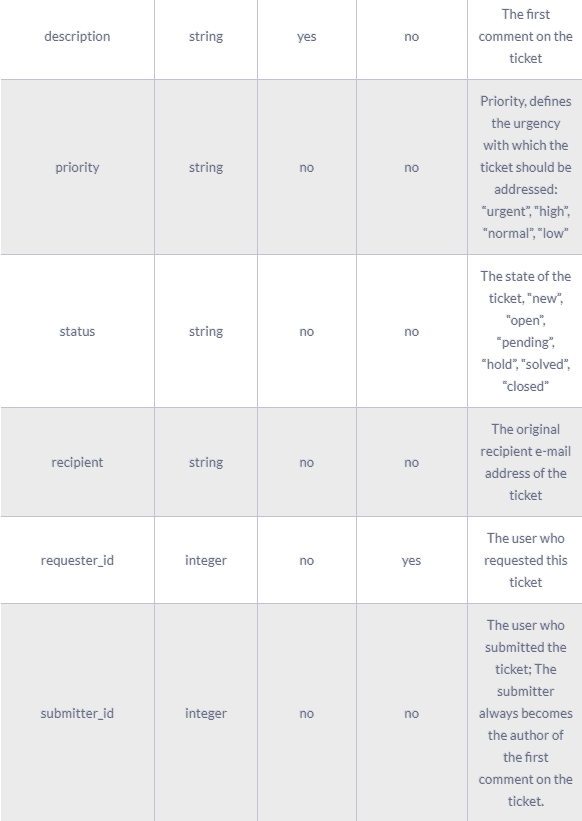
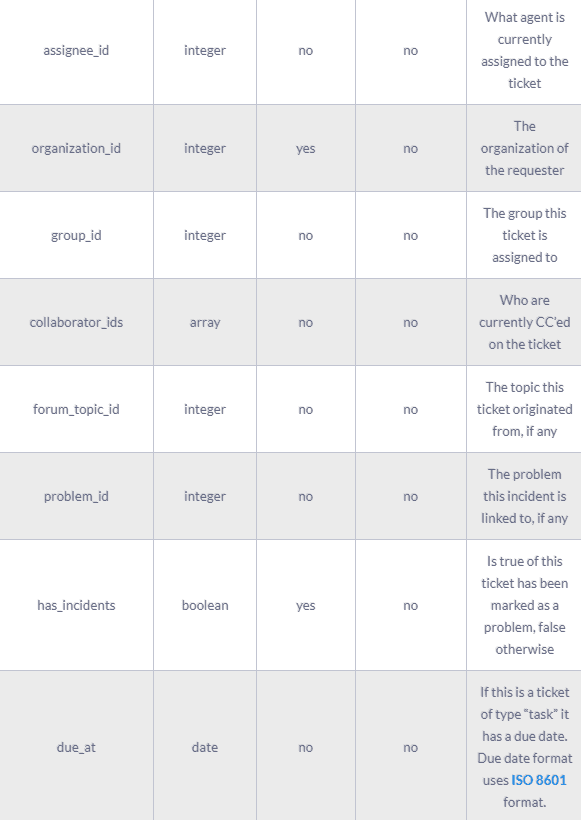
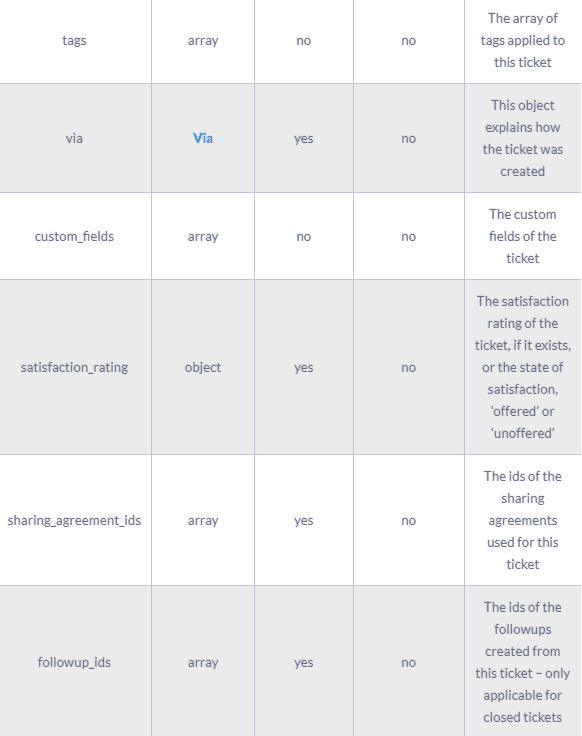
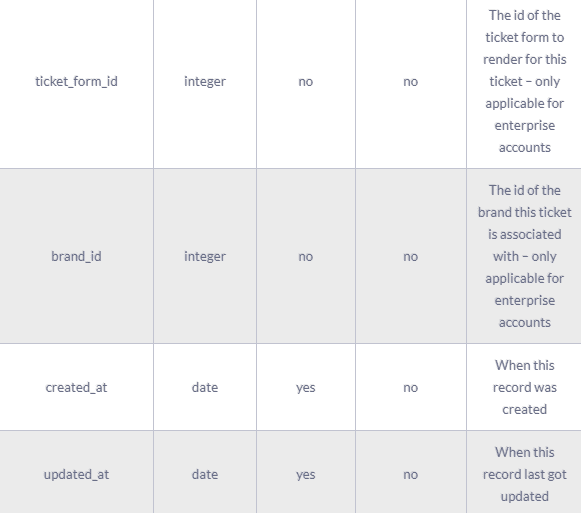
The results of the Zendesk API are always in JSON format. The API offers you the opportunity to get very granular data about your accounting activities and use it for analytic and reporting purposes.
Prepare your data to be sent from Zendesk to Google BigQuery
Before you load your data into BigQuery, you should make sure that it is presented in a format supported by it, so for example if the API you pull data from returns XML you have to first transform it into a serialization that BigQuery understands. Currently, two data formats are supported:
You also need to make sure that the data types you are using are the ones supported by BigQuery, which are the following:
- STRING
- INTEGER
- FLOAT
- BOOLEAN
- RECORD
- TIMESTAMP
For more information, please check the Preparing Data for BigQuery page on the documentation.
Load Data from Zendesk to Google BigQuery
If you want to load data from Zendesk to Google BigQuery, you have to use one of the following supported data sources.
- Google Cloud Storage
- Sent data directly to BigQuery with a POST request
- Google Cloud Datastore Backup
- Streaming insert
- App Engine log files
- Cloud Storage logs
From the above list of sources, 5 and 6 are not applicable in our case.
For Google Cloud Storage, you first have to load your data into it, there are a few options on how to do this, for example, you can use the console directly as it is described here and does not forget to follow the best practices. Another option is to post your data through the JSON API, as we see again APIs play an important role in both the extraction but also the loading of data into our data warehouse. In its simplest case, it’s just a matter of one HTTP POST request using a tool like CURL or Postman. It should look like the following example.
JAVASCRIPT
Working with Curl or Postman, is good only for testing, if you would like to automate the process of loading your data into Google Bigquery, you should write some code to send your data to Google Cloud Storage. In case you are developing on the Google App Engine you can use the library that is available for the languages that are supported by it:
If you are using one of the above languages and you are not coding for the Google App Engine, you can use it to access the Cloud Storage from your environment. Interacting with such a feature-rich product like Google Cloud Storage can become quite complicated depending on your use case. For more details on the different options that exist, you can check Google Cloud Storage documentation. If you are looking for a less engaged and more neutral way of using Cloud Storage, you can consider a solution like RudderStack.
After you have loaded your data into Google Cloud Storage, you have to create a Load Job for BigQuery to actually load the data into it, this Job should point to the source data in Cloud Storage that have to be imported, this happens by providing source URIs that point to the appropriate objects.
The previous method described, used a POST request to the Google Cloud Storage API for storing the data there and then load it into BigQuery. Another way to go is to do a direct HTTP POST request to BigQuery with the data you would like to query. This approach is similar to how we loaded the data to Google Cloud Storage through the JSON API, but it uses the appropriate end-points of BigQuery to load the data there directly. The way to interact with it is quite similar, for more information can be found on the Google BigQuery API Reference and on the page that describes how to load data into BigQuery using POST. You can interact with it using the HTTP client library of the language or framework of your choice. A few options are:
- Apache HttpClient for Java
- Spray-client for Scala
- Hyper for Rust
- Ruby rest-client
- Python http-client
The best way to load data from Zendesk to Google BigQuery and possible alternatives
So far we just scraped the surface of what can be done with Google BigQuery and how to load data into it. The way to proceed relies heavily on the data you want to load, from which service they are coming from, and your use case requirements. Things can get even more complicated if you want to integrate data coming from different sources. Instead of writing, hosting, and maintaining a flexible data infrastructure, a possible alternative is to use a product like RudderStack that can automatically handle this kind of problem for you.
RudderStack integrates with multiple sources or services like databases, CRM, email campaigns, analytics, and more. Quickly and safely move all your data from Zendesk to Google BigQuery and start generating insights from your data.
Sign Up For Free And Start Sending Data
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app.
Don't want to go through the pain of direct integration? RudderStack's Zendesk integration makes it easy to send data from Zendesk to Google BigQuery.