Extract your data from Braintree
Braintree, as it is common with payment gateways, exposes an API that can be used to integrate a product with payment services. Access to this API happens through a number of clients or SDKs that Braintree offers:
Instead of a public REST API, Braintree provides client libraries in seven languages to ease integration with our gateway. This choice is deliberate as Braintree believes that in this way they can guarantee:
- Better security
- Better platform support. And
- Backward compatibility
The languages they targeted with their SDKs cover the majority of the frameworks and needs. For example, with the Java SDK, they can also support the rest of the JVM languages like Scala and Clojure.
Braintree API Authentication
To authenticate against the Braintree API and perform either transaction or pull data, the following credentials are required.
- Public key: user-specific public identifier
- Private key: user-specific secure identifier that should not be shared.
- Merchant ID: unique identifier for the gateway account.
- Environment: Sandbox (for testing) or production.
For more information on how to retrieve the above information, you can check the credentials documentation.
Braintree API Rate Limiting
For a system that handles payments, rate limiting doesn’t really make sense. I guess you wouldn’t like to see some of your payments failing because it happens that you have too many customers and you are dying to pay you. For this reason, Braintree has implemented some really sophisticated algorithms to ensure that if one of their users goes crazy for any reason, this will not affect the others. So they are actually operating outside of the conventional practices of setting up rate limits. Nevertheless, you should always make sure that you respect the service you are interacting with and the code you write is not abusing it.
Endpoints and available Resources
The Braintree API exposes a number of resources through the available SDKs, with these you can interact with the service and perform anything that is part of the functionalities of the Braintree platform.
- Add-ons: returns a collection of all the add-ons that are available.
- Address: through this resource, you can create and manage addresses for your customers. There’s a limit of 50 addresses per customer and a customer ID is always required for the operations associated with this resource.
- Client Token: This resource is available for creating tokens that will authenticate your client to the Braintree platform.
- Credit Card: Deprecated
- Credit card verification: Returns information related to the verification of credit cards.
- Customer: your customer with all the information needed in Braintree to perform payments
- Discount: Access to all the discounts that you have created on the Braintree platform.
- Merchant Account: information about merchants on the platform.
- Payment methods: Objects that represent payments
- Plan: Information about the different plans that you have created in the Braintree platform.
- Settlement Batch Summary: The settlement batch summary displays the total sales and credits for each batch for a particular date.
- Subscription: All the subscriptions that have been created on behalf of your customers inside the Braintree platform.
- Transaction: This functionality is specific to Marketplace
All the above resources are manipulated through the SDKs that Braintree maintains. In most cases, the full range of CRUD operations is supported, unless it doesn’t make sense or if there are security concerns. In general, you can interact with everything that is available on the platform. Through the same SDKs, we can all fetch information that we can then store locally to perform our analytics. Each one can offer back all its results that we can consume, let’s assume that we want to get a list of all the Customers we have with all their associated data. In order to do that we first need to perform a search query on the Braintree API, for example in Java:
JAVASCRIPT
With the above query, we will be searching for all the entries that belong to a customer with the given ID. Braintree has a very reach search mechanism that allows you to perform complex queries based on your data. For example, you might search based on dates and get only the new customers back. Each customer object that will be returned, will contain the following fields.
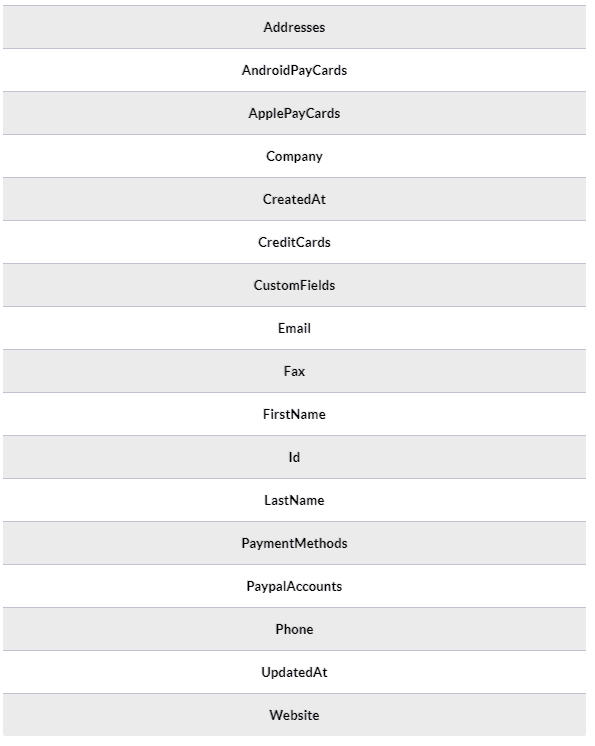
The above fields will be the columns of the Customer table that we will create for storing the Customer data.
Paging is transparently managed by the SDK and the Braintree API so you won’t have to worry about how to iterate on a large number of records. When you get your results you will get an Iterator object which will iterate over all the results in a lazy way for keeping the resource consumption low.
What is important to notice is that the above data are available encapsulated into the structures that each SDK is exposing, so if you need the data in JSON format, for example, this is something that you have to take care of by converting the objects you get as results into JSON objects.
Prepare your data to be sent from Braintree to Google BigQuery
Before you load your data into BigQuery, you should make sure that it is presented in a format supported by it, so for example if the API you pull data from returns XML you have to first transform it into a serialization that BigQuery understands. Currently, two data formats are supported:
You also need to make sure that the data types you are using are the ones supported by BigQuery, which are the following:
- STRING
- INTEGER
- FLOAT
- BOOLEAN
- RECORD
- TIMESTAMP
for more information please check the Preparing Data for BigQuery page on the documentation.
Load Data from Braintree to Google BigQuery
If you want to load data from Braintree to Google BigQuery, you have to use one of the following supported data sources.
- Google Cloud Storage
- Sent data directly to BigQuery with a POST request
- Google Cloud Datastore Backup
- Streaming insert
- App Engine log files
- Cloud Storage logs
From the above list of sources, 5 and 6 are not applicable in our case.
For Google Cloud Storage, you first have to load your data into it, there are a few options on how to do this, for example, you can use the console directly as it is described here and do not forget to follow the best practices. Another option is to post your data through the JSON API, as we see again APIs play an important role in both the extraction but also the loading of data into our data warehouse. In its simplest case, it’s just a matter of one HTTP POST request using a tool like CURL or Postman. It should look like the following example.
JAVASCRIPT
and if everything went ok, you should get something like the following as a response from the server:
HTML
Working with Curl or Postman, is good only for testing, if you would like to automate the process of loading your data into Google Bigquery, you should write some code to send your data to Google Cloud Storage. In case you are developing on the Google App Engine you can use the library that is available for the languages that are supported by it:
If you are using one of the above languages and you are not coding for the Google App Engine, you can use it to access the Cloud Storage from your environment. Interacting such a feature-rich product like Google Cloud Storage can become quite complicated depending on your use case, for more details on the different options that exist you can check Google Cloud Storage documentation. If you are looking for a less engaged and more neutral way of using Cloud Storage, you can consider a solution like RudderStack.
After you have loaded your data into Google Cloud Storage, you have to create a Load Job for BigQuery to actually load the data into it, this Job should point to the source data in Cloud Storage that have to be imported, this happens by providing source URIs that point to the appropriate objects.
The previous method described, used a POST request to the Google Cloud Storage API for storing the data there and then load it into BigQuery. Another way to go is to do a direct HTTP POST request to BigQuery with the data you would like to query. This approach is similar to how we loaded the data to Google Cloud Storage through the JSON API, but it uses the appropriate end-points of BigQuery to load the data there directly. The way to interact with it is quite similar, for more information can be found on the Google BigQuery API Reference and on the page that describes how to load data into BigQuery using POST. You can interact with it using the HTTP client library of the language or framework of your choice, a few options are:
- Apache HttpClient for Java
- Spray-client for Scala
- Hyper for Rust
- Ruby rest-client
- Python http-client
The best way to load data from Braintree to Google BigQuery and possible alternatives
So far, we just scraped the surface of what can be done with Google BigQuery and how to load data into it. The way to proceed relies heavily on the data you want to load, from which service they are coming from, and the requirements of your use case. Things can get even more complicated if you want to integrate data coming from different sources. A possible alternative, instead of writing, hosting, and maintaining a flexible data infrastructure, is to use a product like RudderStack that can handle this kind of problem automatically for you.
RudderStack integrates with multiple sources or services like databases, CRM, email campaigns, analytics, and more.
Sign Up For Free And Start Sending Data
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app.