Blog
Why data teams must separate support work from development work
Why data teams must separate support work from development work

Matt Kelliher-Gibson
Technical Product Marketing Manager
19 min read
February 27, 2024

Surveys show that 55% of data scientists and 97% of data engineers are burnt out. According to Data Kitchen, 80% of data engineers have considered leaving the field entirely. If the current state is bad, the outlook doesn’t look any better.
Businesses are turning up the pressure to do more with less and increasingly questioning the value they’re getting from data teams. Leading or working on a data team can feel like running on a treadmill with increasing speed. You’re running faster, but you’re not moving forward. You want to focus on projects with long-term value, but you can’t get away from the daily urgent tasks.
The business demands more impact but still expects the data team to field all the requests thrown at it. The burnout-inducing issue stems from an organic but problematic integration of two opposed workstreams:
- Data support: Similar to an IT help desk, this work focuses on helping business users with their data problems as quickly as possible. It’s reactive in nature and includes things like accounting for missing data and fixing broken pipelines.
- Data development: This work is the data equivalent of software development. It focuses on building internal and external products that drive revenue, increase efficiency, and improve decision-making. It requires planning, building out infrastructure, and putting automation in place.
These two functions require different processes and skills. Combining them results in problematic context switching, inefficient workflows, and misallocated talent. But there is a better way. Data work will never be free from business pressure, but getting back to a place where the pressure is energizing, not burnout-inducing, is possible.
There’s already a blueprint for us to follow. Using the model set by IT and software development teams, we can build a structure that allows data teams to thrive even as pressures mount to do more with less.
How we got here: Data team origins
How did we get to this point where any work assigned to the data team falls into the undifferentiated bucket of data work? It starts with how data teams typically emerge. Data teams are rarely founding teams, and they usually grow organically out of need, not strategically. Young companies can manage their data in Excel and do basic analyses independently. Data professionals aren’t brought in until data volume and complexity reach a tipping point.
Usually, a specific team drives the decision. Finance or product may hire a data analyst to maintain their growing number of Excel files and dashboards, or marketing may hire a data or analytics engineer to help move data to and from their various tools. Regardless of team or role, these initial data hires are brought in specifically to do data support work like:
- Data dumps
- “Quick” analyses (“Do we have…?”)
- Excel wrangling
- Dashboard changes
Continuous, ad hoc emails and instant messages are the norm for data support work at young companies. Requests never end and often come with countless follow-ups. It can quickly become all-consuming for a single practitioner or small team. In this scenario, the data function’s focus isn't on creating competitive advantage. It's on getting the next task done.
Companies eventually form a stand-alone data team as they grow and hire more data professionals. The decision is rarely a strategic one, though. It’s usually made just because there are enough data roles to warrant a team, and the team just sits within whichever department had the most data people.
Strategically implemented or not, new visibility and scrutiny comes to the data function when the team is formalized. The business expects measurable ROI, so the data team must go beyond data support and begin data development initiatives.
But this pivot causes problems. It’s like trying to turn an IT support team into an app development team. At a strategic level, the team wasn’t designed for data development, well-vetted data product use cases don’t exist yet, and the team is likely unsure how to get started with development-style work.
At a tactical level, old ad hoc workflows remain, and because the business is growing, the demand for data support is increasing. Work comes in from all sides of the company. It’s all “urgent,” but there’s little to no tracking or triaging. The focus is short-term, but development requires a medium to long-term focus. You can’t stop or significantly reduce support because it keeps the lights on for the business, but it’s blocking all progress on data development.
Managing the evolution of a data team at this point feels like trying to untie a Gordian knot. However, this tension is not new in technology, and there’s a blueprint for resolving it. If we look at the model set by IT and software development teams, we find a solution for balancing the seemingly opposed goals of short-term support and long-term development.
Lessons from IT and software
Acknowledging the difference between reactive support work and proactive development work, our predecessors in tech wisely separated work between two different functions with clean edges: IT support and software development. Support focuses on the urgent needs of internal stakeholders, while development focuses on building things that generate long-term value for the company. We don’t ask a software engineer to troubleshoot an issue with our laptop. Similarly, we shouldn’t ask a data scientist to spot-check last Thursday’s sales data.
At a fundamental level, IT and software development teams have different incentives and priorities that require different processes and strategies. The support team works in a Kanban style, triaging and prioritizing tickets by problem severity. This team is held accountable by metrics like tickets closed, uptime, and compliance with agreed-upon SLAs. The development team is organized into scrum teams, working in sprints, and held accountable to deliver on a roadmap.
To deliver on both data support and development initiatives, data teams must learn to separate the urgent support work from development work, just like IT and software teams. Doing so frees up space for each function to excel.
Even if you don’t have the resources or interest at your company to formally create separate support and development teams, you can begin establishing clear edges for the work you have with the team you have. IT support teams were once in the same position and made it through the fire. They paved the path to success, and as a data professional, you can take control of your destiny by following in their footsteps. At a high level, this involves:
- Streamlining communication with internal stakeholders
- Tracking and prioritizing requests
- Establish SLAs
Streamline communication
Ad hoc communication can be a useful way of working on small teams, but as businesses scale, communication must evolve in sophistication. For data support work, you need to create one or two channels for all requests to remove the constant interruptions so everyone can focus and work more efficiently. The fewer channels, the better (while balancing the expectations of stakeholders). Your setup can be as simple as an #ask-data slack channel, a data.support@company.com email address, or an online form. The key is to make it easy for stakeholders to use. You’ll likely get pushback for taking away direct access to individuals, so requiring them to fill out a form with a dozen required fields at the outset probably won’t go over well.
You can start with a simple three-field form: name, email, and a text field for requests. This method requires a little work on the stakeholder side, but it allows them to send their requests the way they’re used to. It might be tempting to make a complex request system that forces stakeholders to articulate and categorize their requests perfectly, but remember the goal at this point is stakeholder adoption not perfection.
Once you have high adoption, you can add some friction to the request process. Friction can improve request quality and discourage urgent last-minute demands. Caitlin Hudon’s data intake form is a great resource for some guidance as you evolve your request system.
Track and prioritize all requests
Even with streamlined communication, data support will be chaotic unless you can capture, track, and prioritize every request. You’ll need a ticketing system like Jira or Linear for this. The system you use is less important than adopting it and integrating it into your workflow. You may find it‘s easiest to use whatever system is already in place at another part of the company. Just ensure that it integrates with your communication channels because you’ll need to create tickets for each request automatically.
Capturing and tracking requests enables you to quantify work volume and team performance, making it easier to share wins and articulate challenges to the rest of the business. Over time, it will also provide valuable intelligence to help you decide where to build automated solutions and infrastructure.
Establish SLAs
If stakeholders don’t trust that there’s a process to ensure their requests get handled on time, urgent requests will be the norm. Humans are naturally wired to eliminate uncertainty and typically take the path of least resistance. When it comes to data support requests, “just do it right now” is the easiest way for a stakeholder to handle uncertainty. But the fire drill approach isn’t sustainable and will undermine your ability to provide real insight. It’s up to you to change the paradigm.
It might feel like stakeholders value speed and instant availability, but what they’re really looking for is clarity and predictability. Use SLAs to deliver it. You can eliminate uncertainty by implementing a transparent policy and tracking your work. A trusted process will help you change behavior and make life easier for all parties. Well-defined SLAs will also help prevent real emergencies. If historical analysis has an SLA of 5-7 business days, your stakeholders will begin to plan accordingly when they need a historical analysis.
The trick to building useful SLAs is to ensure you’re promising something that’s achievable for your team and reasonable for the stakeholder. To ensure buy-in and make enforcement easier, involve your stakeholders. Here are a few pro tips:
- Include timing by category for when requests will be acknowledged and when they will be completed.
- Don’t make your categories too granular. Look at the work you’re doing now and group it into a few large buckets like data investigation, data analysis, and data dumps.
- Explicitly note that unusual requests (ones that involve new data sources or particularly complex analysis) may take longer and put it on your team to communicate updates for these scenarios proactively.
From data support to data development
When you make these three process changes, you can take control of data support work. Assigning and scheduling tasks will give your team the ability to work more methodically and efficiently. Greater focus will create space on calendars and give mental capacity back to everyone.
So how do you fill the time you get back? If you’ve been swamped with support work, you probably haven’t been thinking about data use cases for the business. Now is the time to figure out those use cases and get to work on data development initiatives. Here are a few tips to help you get started.
Put your product owner/manager hat on
Support is reactive, development is proactive. You can’t sit back and wait for the business to come to you with data development ideas and use cases. You have to go and find them. This means talking with the business, thinking strategically, and developing a strong understanding of your business’s strategy.
Ideally, you could spend most of your time on this work or have a dedicated position. However, if that’s not in the cards, you can still successfully deliver on data development. You just have to make it a priority and put some structure around it. Schedule standing meetings with important stakeholders to learn how data can support their work. Don’t just ask them what they want. Find out what their goals are, what they’re doing to achieve them, and what pain points they have.
Build an intelligence document in Notion or Google Docs detailing each department’s KPIs, goals, major initiatives, and pain points. Once you get this information in one place, you’ll start to see opportunities for the data team to create significant competitive advantages for your company. Sometimes you’ll find opportunities that cross teams or departments – these are the hardest opportunities for business to see. When you deliver on initiatives that capture this type of opportunity, the rewards can be massive, so pay particular attention to them.
Consider both sides of data development value
Data development can affect the bottom line either by increasing revenue or reducing costs. Development to reduce costs focuses on internal efficiencies. Initiatives in this bucket focus on automating how the company uses data and include projects like:
- Replacing manual data ingestion with data pipelines
- Automating decision making with data
- Creating predictive models and analytics
Development to increase revenue focuses on customer facing products and involves applying data to your current products and processes or creating new data products. Initiatives in this bucket require close collaboration with business teams and include projects like:
- Personalized recommendations in your website or app
- Predictive models to reduce churn and increase cross-selling
- Embedding AI into the product experience
Reducing cost is a great place to get started. These initiatives are easier to define and deliver. Starting here will give your team a chance to build trust and momentum. However, there’s a cap on the overall value of cost-reducing initiatives. Eventually, you’ll need to make the jump to revenue initiatives. As you work on efficiency projects across the company, keep your eyes open for revenue projects. You’ll start to see those opportunities that span teams hiding in plain sight. And with the credibility you build through cost-reducing initiatives, stakeholders will be open and excited for the larger projects with bigger potential.
Focus on what the business needs, not on what they ask for
It’s tempting to ask business stakeholders what they want and then build to spec. Don’t fall into this trap. Solutions prescribed by business stakeholders aren’t informed by a deep understanding of data or an awareness of the data available at your company. To get to the art of possible, you need to combine your knowledge of data with their knowledge of business problems to formulate a plan that creates maximum leverage.
Instead of just giving stakeholders what they want, focus on the problems they are trying to solve. Once you’ve got a strong understanding of their problems, your team can do the design and ideation work. Ask the 5 whys to get to the root. The first request is usually a solution “I want a dashboard/model/report/pipeline.” Asking a series of why questions will help you get past their solution to the actual problem they’re trying to address.
Here’s how a request from operations for a predictive model of volume might play out in this scenario:
- Why do you want a predictive model? To forecast volume for the next two weeks
- Why? To do employee scheduling for the next two weeks
- Why? To make sure they don’t over schedule on days that are going to be light in volume
- Why? To reduce labor costs
- Why? To increase our KPI of store efficiency
Drilling down gives you more context – operations needs to increase store efficiency. With this information, you can partner with the operations team to develop the best solution. A predictive model of volume could help, but you may more efficiently accomplish the goal with a historical analysis, or you may find the issue is a lack of timely data for decision making. Only by understanding the root problem and assessing all potential solutions can you pick the best one.
Build POCs vertically not horizontally
When you start designing initial iterations of your data development projects, build a vertical slice of the final product. It’s easy to deep dive into building a large project horizontally without thinking about how data will be imported and transformed upfront or how you’ll deliver results downstream. This can result in a project that looks great in isolation but can’t be integrated into the business for real-world use.
To avoid this painful scenario, build a skeleton of the end-to-end system upfront. Even if you begin by simply reading in a csv file, doing the main project, and writing out a csv file, this approach will force you to think through the entire workstream of the mature product and catch potential issues before they become problems.
Prioritize your projects
Prioritizing data development projects can be tricky. Here’s a helpful framework you can use. Make a two-dimensional grid with business value on one axis and complexity of work on the other, then plot all your potential projects on the grid.
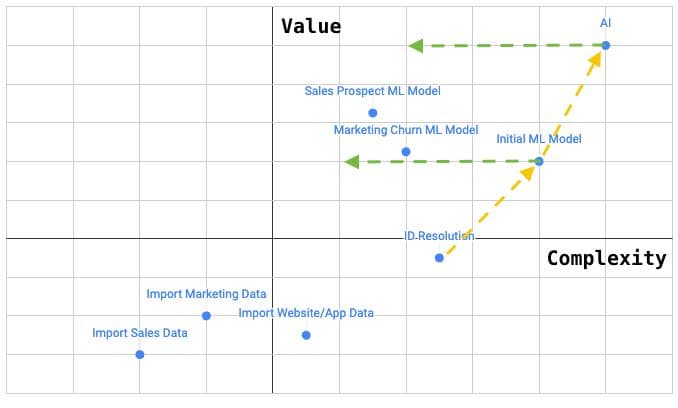
This will help you quickly identify your highest-impact projects. However, it could cause you to ignore some projects with low initial value that are required to unlock higher-value projects. To account for this, draw lines (yellow in the example above) connecting these lower-value projects to the higher-value initiatives they support. You can also draw lines (green in the example above) representing the reduction in complexity for the higher-value initiatives upon completion of prerequisite projects. It’s a simple framework, but it gives you a clear roadmap to accomplish those high-value, high-complexity projects.
Jumping into data development is difficult. After being stuck exclusively in data support mode, it can feel intimidating, especially without explicit guidance from the business. Embrace the challenge. Data development work has the potential to create sustained competitive advantage for your business, and it can be the most rewarding work in data. It also goes a long way in expanding your teams influence within the company. If you start with simple use cases, you can string together a series of small wins. Before you know it, you’ll be tackling higher value, higher complexity projects and making major contributions to your business.
Structuring the team for support and development
Data team structures aren’t as mature as other technology teams. The current model where undifferentiated ‘data work’ gets dumped into one function is problematic. It’s part of why burnout is so rampant among data professionals. Using IT and software development as a guide, we can see the value in formally separating different workstreams. There are two main approaches you can take to create separation:
- Dedicated data support – This approach copies IT support and involves creating a team that focuses exclusively on data support work with dedicated processes, tooling, and personnel, just like a traditional support team.
- Embedded data support – This approach puts data support professionals back into individual business units, similar to how data support began. To overcome challenges with siloing and resource constraints, it necessitates the addition of a data platform team. The platform team provides tooling for embedded data professionals and gives them a forum for knowledge sharing with their counterparts in other business units.
Start creating clean edges for your data work
If you feel like your team is working nonstop to keep the lights on but struggling to deliver long term value, you’re not alone. Constant ad hoc requests and increasing pressure to prove bottom-line results are taking their toll on data professionals everywhere. Working in data today can feel like being stuck in a vise with pressure squeezing you from all sides.
The problem stems from a one-size fits all approach to data work, and the way out has already been paved by IT and software development organizations. To perform their work most effectively, they created clean edges for their work and their functions. Following their roadmap, you can separate urgent data support work from longer-term data development initiatives. With clean edges, you’ll enable your team to do their best work, and the entire company will benefit.
Turn your customer data into competitive advantage
Schedule a demo with our team today to learn how RudderStack can help you go from raw data to revenue with speed and agility.
Published:
February 27, 2024
More blog posts
Explore all blog posts
Understanding event data: A guide to behavioral data collection
Danika Rockett
by Danika Rockett

How AI data integration transforms your data stack
Brooks Patterson
by Brooks Patterson

Behavioral segmentation: Examples, benefits, and tools
Brooks Patterson
by Brooks Patterson


Start delivering business value faster
Implement RudderStack and start driving measurable business results in less than 90 days.


