Blog
The Profiles Handbook: Models in Profiles
The Profiles Handbook: Models in Profiles

Nishant Sharma
Technical Director
9 min read
June 13, 2023

This is the second installment in a series of posts exploring our customer 360 solution – RudderStack Profiles. Profiles makes it easier for every data team to build a Customer 360 and activate comprehensive customer profiles to drive better business outcomes.
In the first installment, I gave an overview of Profiles. In this installment, we'll dive into the building blocks of a Profiles project – models. Read on to learn about the different types of models, their classifications, and how they fit into the larger Profiles ecosystem.
What are models in Profiles?
Models are the building blocks of a Profiles project. Fundamentally, they are recipes for generating artifacts within data warehouses using SQL or Python. These recipes can be used for cleansing data, summarizing data into more consumable pieces, or even filtering data prior to being layered into the profile. The input of models are data from your data warehouse, and the output artifacts commonly manifest as tables or views.
Profiles models are designed to be idempotent, meaning that they can be run multiple times without causing changes in output. This is achieved through Profiles’ unique approach to snapshotting incoming event streams. Each model run is guaranteed to consume only a specific snapshot of input data. Input events with an occurred_at timestamp with a time after the timestamp of the run context are excluded. Each model is also tagged with a hash of its recipe text and a hash of the recipe texts of its input models. This ensures the output of a specific run is guaranteed to be the same, no matter how many times you run it.
In a Profiles project, all the models are specified in YAML. Internally, these YAML model specs may be processed in two different ways. For SQL models, the model_spec YAML is set as an input to the SQL template corresponding to the model_type selected. This means that YAML is first converted into transformation SQL which is then executed in the warehouse. For Python models, the model_spec YAML is sent to a Python notebook, and the Python notebook implements the data transformation using the model specification in YAML.
Using these two universal languages makes models accessible and drives a number of benefits:
- Easy writing and maintenance
- Straightforward testing
- Easy version-controlling
- Simple documentation
These benefits combine to make Profiles models a reliable and scalable solution for transforming your customer data.
To successfully execute a model's recipe, it may rely on outputs from multiple other models. These models and their input dependencies create a graph, with models as nodes and dependencies as edges. For effective model execution, this graph must be free of cycles. This configuration is frequently called a model DAG (Directed Acyclic Graph) or execution DAG.
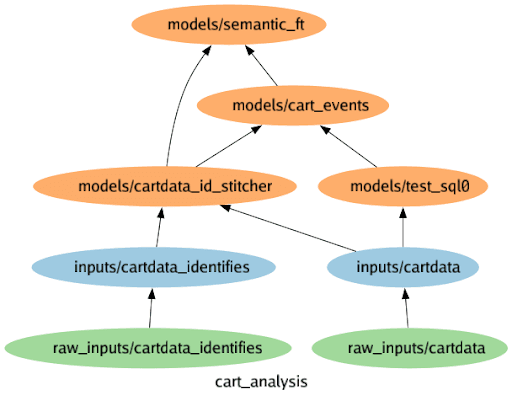
Model classifications
As we dive deeper into the intricacies of Profiles, the concept of models emerges as a fundamental building block. Given their broad-ranging applications, it's easy to get tangled in the semantics of exactly what constitutes a Profiles model.
In this section, we aim to simplify this concept by shedding light on the different classifications of models. These categories highlight the vast scope of this core concept and illustrate how models interact with data and with other models within the Profiles ecosystem.
Models in Profiles can be classified based on:
- Creator recipe language
- Application
- Generated warehouse artifact
- Data consumption pattern
- Explicit vs Implicit deduction
Classification based on creator recipe language
Models in Profiles are typically defined as YAML in models/profiles.yaml. The model’s creator recipe uses this YAML to configure itself for running the model. Because the model creator recipe could be written as a SQL template or as Python, it’s possible to classify models by language.
SQL
The creator recipe of SQL models is a SQL template written in Pongo2.
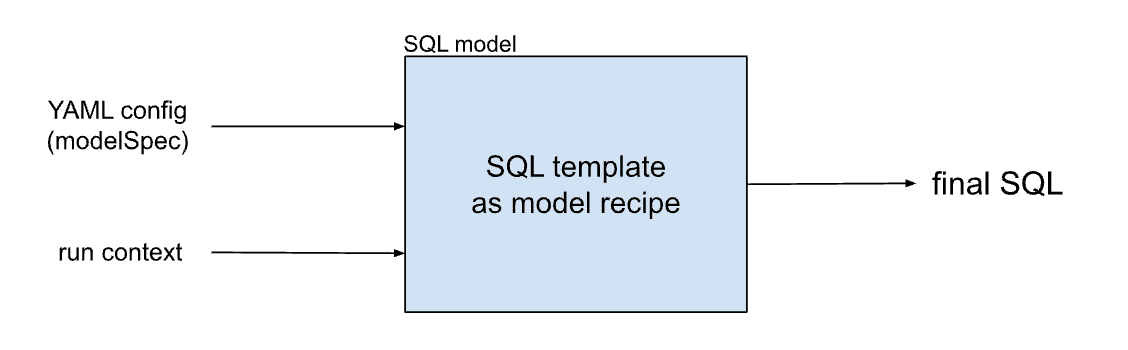
The SQL template is compiled into SQL at the time of model compilation. There are two different types of SQL models: Single Select and Multi SQL.
Creator recipes for Single Select models compile into a single SQL SELECT stat
Template SQL:
SQL
Output SQL:
SQL
Multi SQL models employ a series of SQL statements for more complex data manipulation and transformation tasks. They are used in cases where a large and complex SQL logic is required to compute the model output. An Id Stitcher (shown below) is an example of a Multiple SQL Statement model. The last SQL statement is usually to create the output SQL table.
Template SQL:
SQL
Python
Python models utilize Python code for data processing, enabling more advanced logic and functionality, such as machine learning algorithms.
Classification based on application
There are several applications for Profiles models. These applications are perhaps the most tangible way to classify the models.
- ID Stitcher – These are models which consolidate and link customer records based on unique identifiers. By connecting disparate data sources and merging customer information, the Id Stitcher creates a unified view of customer data, enhancing the accuracy and usability of the data for analysis and personalization purposes.
- EntityVars – Considering a user as an entity, a complete view of each user consists of a number of user features, one for each user ID. The EntityVar concept builds upon this concept of a single value per user ID. An EntityVar is a model with output as a column containing one value per user ID. Usually, this column is added to the entity's var table.
- InputVars – InputVars are similar to EntityVars. An InputVar is also a column model which appends a column to another table. They are typically used to append a column to project inputs, Hence the name InputVars. However, they can also be used to add columns to other model outputs.
- Feature tables – These models bundle a subset of EntityVars from the feature table entity into a table or a view.
- ML models – These models incorporate machine learning algorithms to generate predictive or classification-based traits, such as churn prediction or customer lifetime value.
- SQL models – Pre-existing models may not be sufficient to model unique requirements for every customer. In those cases, you can create your own custom models using SQL.
Classification based on generated warehouse artifact
Most models create warehouse artifacts that bear data such as tables or views. Even ephemeral concepts like temporary tables, CTEs, and sub-query results bear data (even if they exist only for the lifetime of query execution). However, not all warehouse artifacts created by a model carry data. Conceivably, a model could be creating a UDF. So, we can classify models as data-carrying or non-data-carrying.
Data-carrying models
- Tables – These models generate tables in the data warehouse.
- Views – These models create views with the query behind the view specified by the creator recipe.
- Table column models – These models add an additional column to an existing model output in the warehouse. They are useful for scenarios where it is desirable to define a concept as a model but undesirable to create an independent table for it. User traits provide a good example for this use. Conceptually each individual trait is a model, but it’s not performant to create a new table for each new trait.
- Ephemeral models – Subtypes of ephemeral models include CTEs and temporary tables. Their output artifacts are intermediate data storage structures that exist only for the duration of a particular session or query.
Non-data-carrying models
HTML reports: When an HTML report model is run, it creates an Id Stitcher run report from tables in the warehouse. These reports include the number of new ID clusters added, the number of clusters merged, and the largest Id cluster found.
Classification based on explicit declaration vs implicit deduction
In a profiles project, models are usually explicitly declared at models/inputs.yaml or models/profiles.yaml. While inputs.yaml declares input models, the profiles.yaml lists user-specified models for things like feature table creation and ML predictive analysis. However, there are other models that are not explicitly listed by the user but are implicitly deduced by Profiles.
- For entities linked with multiple ID types, Profiles automatically deduces a default ID stitcher. It is used to stitch entity IDs, unless overridden in entity declaration in pb_project.yaml.
- For entities linked with a single ID type, Profiles automatically deduces a default ID collator model. It is used as an authoritative list of entity IDs, unless overridden in entity declaration in pb_project.yaml.
- When one declares one or more entity vars for a certain entity, Profiles automatically deduces the creation of an entity var table.
- When one declares one or more input vars on a certain input, Profiles automatically deduces the creation of an input var table.
This distinction between explicit declaration and implicit deduction offers another helpful way to classify models in RudderStack Profiles.
By providing a versatile framework for creating data warehousing artifacts, models in Profiles empower data teams to easily build and maintain an elegant customer 360. With the heavy technical lifting handled by Profiles, you can focus on delivering insights rather than managing infrastructure.
Build a customer 360 in your warehouse
Check out RudderStack today to see how you can unify all of your customer data into a single source of truth for every tool and team
Published:
June 13, 2023



Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
