Blog
How Data Teams use RudderStack to Support Marketing
How Data Teams use RudderStack to Support Marketing

Eric Dodds
Head of Product
9 min read
July 21, 2021
We previously covered the inherent challenges involved in the data / marketing relationship. Thankfully, the relationship between the two teams is getting better. Not only are marketers becoming more technical, enabling them to understand and collaborate with developers, but the tooling available to engineers has also improved significantly.
While there are many uses for RudderStack across the customer data stack, a primary use case for most developers and data engineers is eliminating pain points that plague marketing projects from a data perspective (like the ones we outline here). Instead of being forced to use tools built for marketers, laboring through building internal tools, or dealing with the always-problematic Google Tag Manager, developers can much more easily manage infrastructure from the data layer and get marketing the data they want in the tools they want.
Here’s an overview of the specific ways data teams support marketing from the data layer with RudderStack.
Step 1: Consolidate and standardize 1st-party data collection
One of the core challenges marketing faces is different versions of the truth when it comes to 1st-party data. The symptoms often show up in comparing two different marketing/sales tools. You’ve likely heard that “the data in Google Analytics doesn’t match what’s in HubSpot,” or been asked, “why are there so many discrepancies between Klaviyo, Salesforce, and our Looker reports?”
Data discrepancies almost always happen because various tools use different technical mechanisms for collecting data and each tool’s definitions and formats are slightly different. Returning to the examples above, Google Analytics and HubSpot both require you to run their JavaScript snippets and they collect browsing behavior differently. Klaviyo and Salesforce have native sync functionality, but custom fields, list membership, and other data points don’t translate well. Looker data comes from the warehouse, where the data has likely been cleaned up by an analytics team. As the number of tools in the stack continues to grow, this problem gets worse.
The solution is consolidating tracking into a single source and standardizing data collection.
The nature of this problem begs for standardization and simplification at the source, which is exactly what RudderStack’s SDKs enable. With RudderStack, you only have to instrument tracking one time, and our simple JSON payloads follow standardized schemas.
Here’s an example. Let’s say you’re an eCommerce company and the marketing team uses coupon offers to get people to sign up for their weekly deals newsletter. Marketing wants to add additional data to newsletter signup events. Specifically, they want to know the name of the coupon that drove the signup. Normally, that would be a gigantic pain, requiring slightly different code for every separate destination that is tracking signups (Google Analytics, Klaviyo, Salesforce, etc.)...and that’s not even considering updating conversions for ad platforms (which we will cover below).
In RudderStack, you only have to instrument one signup event and identify the new user. You could send a .track call named `newsletter_signup`. To add a coupon code, you’d simply grab the value and add it to the properties of the track call, which will send the same, standardized payload to every marketing tool (more on integrations below). You can also identify the user so that a contact record is created in marketing, email, and CRM tools.
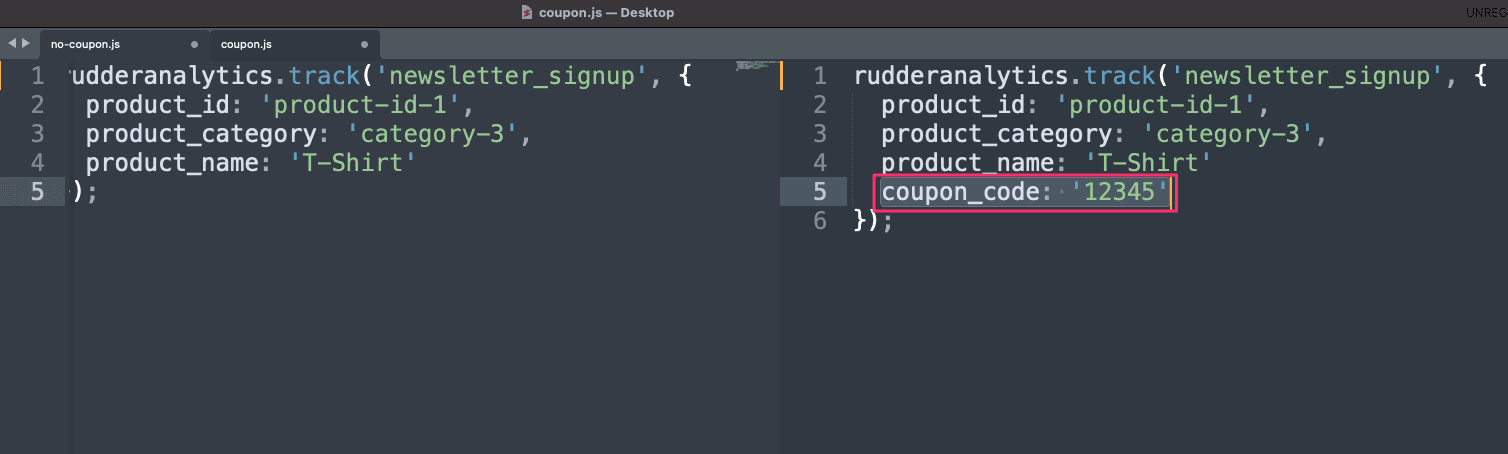
For developers, this means a drastically simplified workflow for both instrumentation of 1st-party tracking and, more importantly, the standardization of the data that is being collected. This also means control—no more surprise tags being implemented in Google Tag Manager...in fact, you can eliminate Google Tag Manager altogether (hallelujah!). Best of all, schemas can be version-controlled in your codebase, so you know exactly what data is being collected.
For your marketing team, this means data consistency across tools and much faster turnaround times when they request data from you and the data team.
Step 2: Remove integrations work from the equation
Even if you standardize data collection, you still have to send it to all of the tools used by marketing. Normally this means developers have to do a bunch of custom API work to send the standardized payloads.
RudderStack removes tedious integration work from the equation. The standardized events your instrument can be automatically sent to any destination in your stack, including marketing tools. That’s right—no integration work required. Let’s return to the `newsletter_signup` and user identification examples from above.
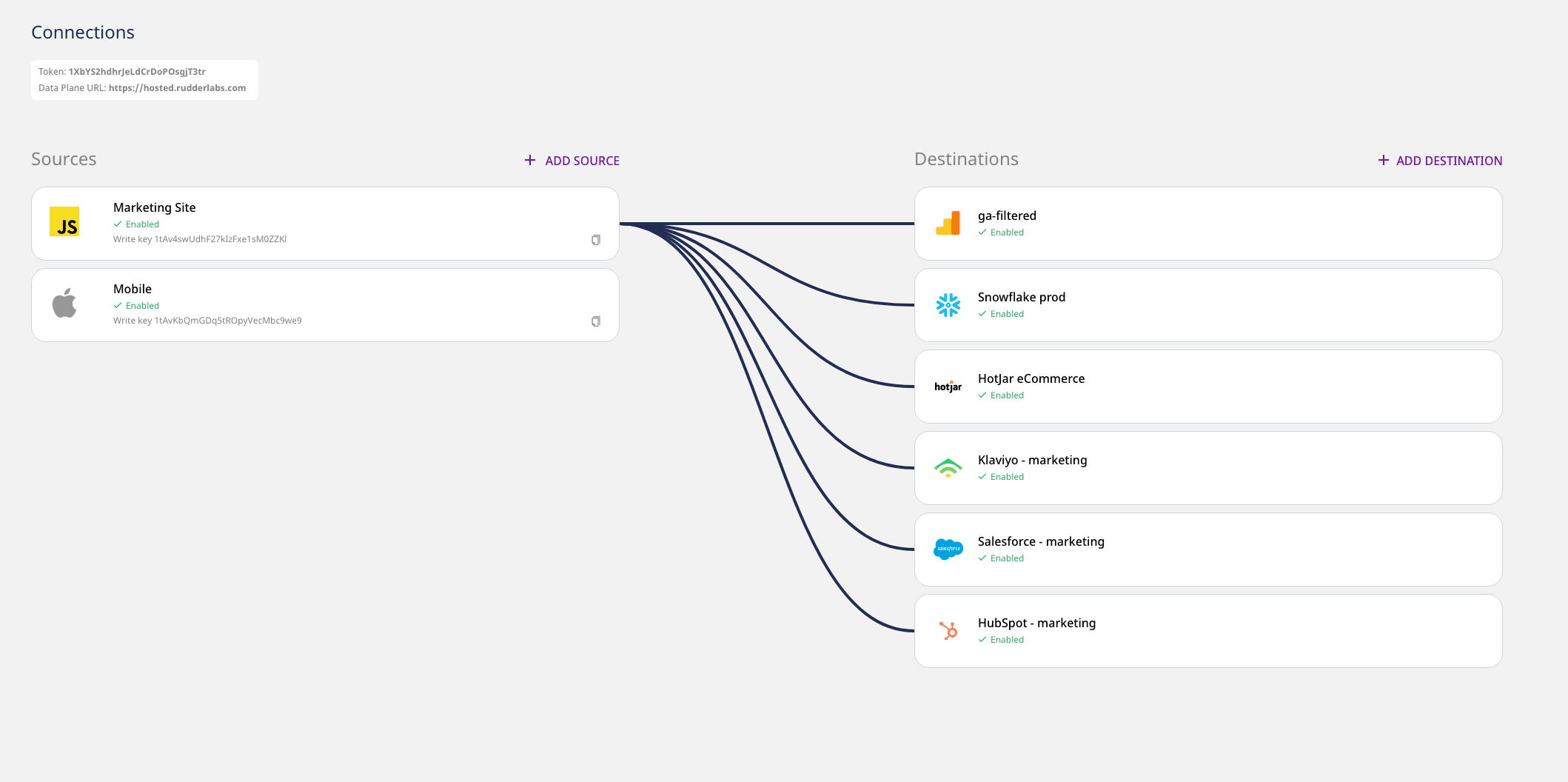
When the identify call runs, RudderStack will create user records in all of the applicable downstream tools. In this case, users would be created in Klaviyo, Salesforce, and any other downstream tool you’ve added as a destination in RudderStack. If you add your data warehouse as a destination, we’ll also update the users table so that your Looker reports have the latest data.
The `newsletter_signup` .track call is a behavioral event, which doesn’t apply to every destination. In this case, marketing wants to send the event to Klaviyo (so that they can segment those signups into a list) and Google Analytics (so that they can analyze conversion funnels). Again, RudderStack will automatically populate both Kalviyo and Google Analytics with the event information.
Step 3: Streamline client and server-side conversion management for ad platforms
For developers, the only thing worse than working on custom integrations with marketing’s cloud tools is dealing with the gigantic mess of sending conversions to paid ad platforms.
Instrumenting dedicated conversion events across Facebook, Google, Pinterest, Bing, etc. requires constant attention as marketing runs experiments and means either lots of custom code or painful troubleshooting and complex sequencing in Google Tag Manager. Yuck.
In RudderStack, your existing events can be sent directly to ad platforms as conversions, both on the client-side and server-side. So, let’s say marketing wants to create a remarketing audience to serve ads to everyone who signs up for the newsletter. To accomplish that, you simply need to add your ad platforms as destinations, then map your existing `newsletter_signup` event to the corresponding conversion in the platform (i.e., for Facebook you could map `newsletter_signup` to the Lead conversion).

Step 4: Customize and fix destination integrations on the fly with Transformations
No matter how streamlined you make your data flow to marketing tools, marketing’s needs change as they learn through experiments that they run. That means that inevitably data payloads will need to be updated and requirements will change, even on a destination-by-destination basis.
For example, let’s say that the marketing team wants the `most_recent_coupon` value to be pushed to Salesforce, but the custom field they created is “Latest_Coupon_Code__c”. Instead of having to add another key to the original event, you can use simple JavaScript in a RudderStack Transformation to customize the payload for the Salesforce destination. In this case, you would rename the `most_recent_coupon` key to “Latest_Coupon_Code__c”.
Because Transformations are written with JavaScript, the sky is the limit and our customers have found hundreds of uses, from customizations to on-the-fly fixes.
JAVASCRIPT
Finally, work on the fun stuff
Once you get the low-level data plumbing work out of the way, you can start to collaborate with marketing on the fun stuff—projects that can really move the needle for the company. Here are a few examples.
Send enriched data from the warehouse directly to marketing’s tools
It’s becoming more common to build enriched customer views in the warehouse using tools like dbt, but getting those enriched data points to cloud tools is a huge pain. With RudderStack’s Reverse ETL feature, you can turn tables into payloads and populate the same downstream tools.
For example, you may have a list of customers in your warehouse who have purchased products from another brand your company owns and marketing wants to exclude them from certain email campaigns in Klaviyo. With Reverse ETL you create that cohort in your warehouse and push it to Klaviyo, making it easy for marketing to build the right logic.
Send audiences and cohorts directly to ad platforms
The data data team often has access to the data required to build the most interesting and valuable marketing audiences. Let’s say you’ve enriched high lifetime value customers with third-party intent data and have that cohort in your warehouse.
RudderStack can push that audience directly to ad platforms like Facebook Custom Audiences.
Enable more advanced marketing automation
Marketing teams are often limited to using custom fields or in-platform tracking to build marketing automation logic. With RudderStack, though, you can populate tools like Klaviyo, Salesforce Marketing Cloud, Marketo and other marketing automation tools with real-time behavioral events, enabling much more advanced triggering and automation.

Competitive advantage, check
When marketers are willing to grow their technical muscles and data engineers are equipped with proper tooling, the relationship quickly moves from contentious to symbiotic, and the whole company benefits. We dare say marketers and engineers could even grow to appreciate each other and enjoy working together.
Power up your data-marketing relationship today
Sign up for RudderStack for free, and test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app. Get started.
Published:
July 21, 2021
More blog posts
Explore all blog posts
Understanding event data: A guide to behavioral data collection
Danika Rockett
by Danika Rockett

How AI data integration transforms your data stack
Brooks Patterson
by Brooks Patterson

Behavioral segmentation: Examples, benefits, and tools
Brooks Patterson
by Brooks Patterson


Start delivering business value faster
Implement RudderStack and start driving measurable business results in less than 90 days.


