Blog
Dogfooding at RudderStack: Our Data Stack
Dogfooding at RudderStack: Our Data Stack

Benji Walvoord
Director of Solutions Engineering
7 min read
July 26, 2021

Here is a quick guide on how we leverage the functionality of the RudderStack application right here at RudderStack.
Overview
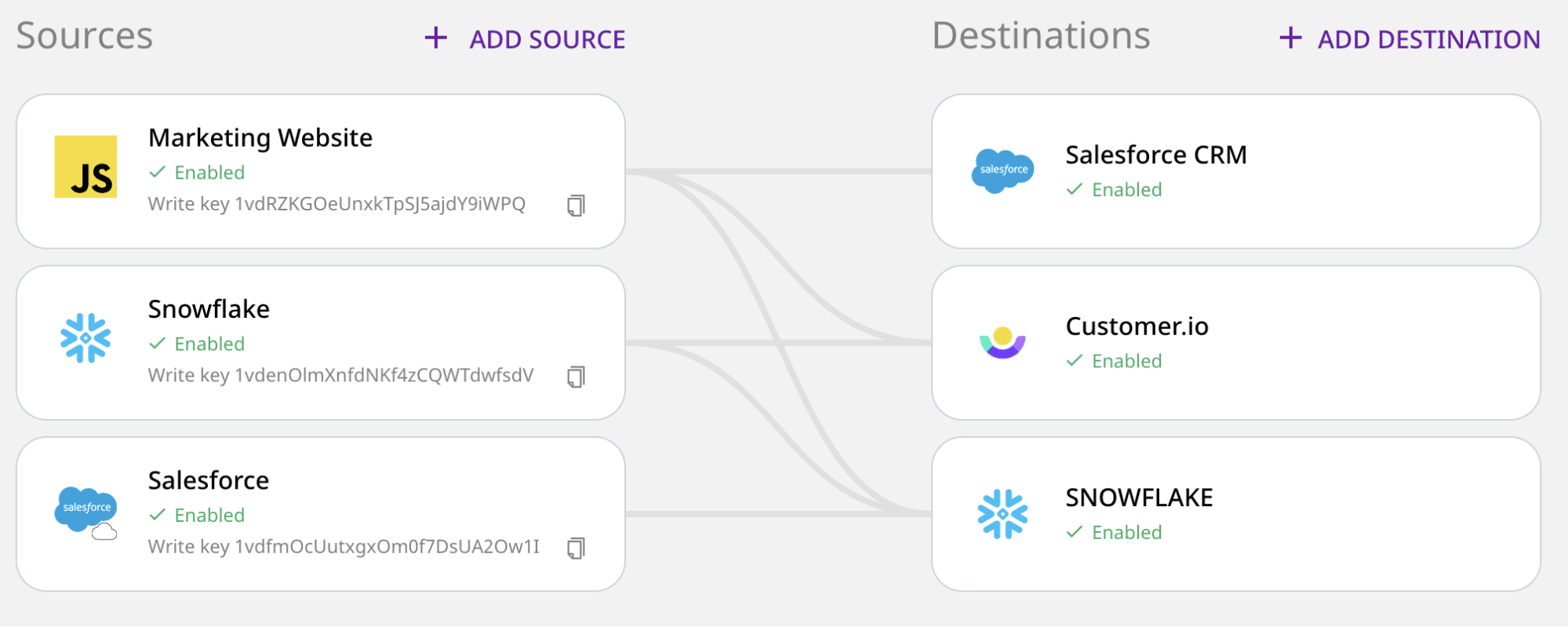
We leverage our Event Stream and ETL pipelines to ingest data from our apps, websites and cloud tools. This gives us comprehensive coverage across the stack and a full view of the user journey and user profile across every digital touchpoint. Event Stream feeds data to cloud tools in real-time and dumps behavioral data to Snowflake and S3 every 30 minutes. ETL pulls data in from our cloud marketing and sales tools as well as ad platforms and loads the data into Snowflake, making it easy for us to get a complete picture in the warehouse. As we learn more about our customers and enrich various data in the warehouse, we syndicate that valuable data back to cloud tools through Reverse ETL.
Here’s a high-level breakdown of our stack in terms of pipelines and how we use them. In this post, we’ll give a brief overview of how we use each pipeline, and in the next post we’ll dig deeper into our cloud and warehouse destinations.
Customer data pipelines
- Event Stream - analytics, conversions, 3rd-party SDK (tag) management
- ETL - ETL for cloud data for richer analytics
- Reverse ETL - sending enriched data and audiences to the stack
We also asked our internal teams for “Pro tips” on the one or two things they find most useful about using RudderStack for their particular function.
Event Streaming - Real-Time
Marketing website and web app front-end
When we say you can start streaming events in 5 minutes, we really mean it, and setting up a live stream from your website is as easy as it gets. Take for example our own marketing website, written in Gatsby and running on Sanity, where we collect a variety of client-side events (page, track and identify) as users navigate the site, submit forms for demo requests and register to attend webinars. These events are all client-side and passed to RudderStack via a Javascript SDK Source. 4 lines of code and simple JavaScript to execute page, track and identify calls and we’re off to the races.
JAVASCRIPT
These events are streamed real-time to the RudderStack data plane and then on to a variety of different downstream destinations including Salesforce (CRM), Snowflake (Datawarehouse), Customer.io (Email Marketing), and Google Analytics to name a few (we will go into more detail on our cloud tools in the next post).
JAVASCRIPT
Pro tip: Our marketing department uses distinct Anonymous ID from RudderStack as a more accurate count of site traffic and conversions than what they get from Google Analytics (because seeing is believing). They also send .track events as both client and server-side conversions to ad platforms, which they say is a hundred times more convenient than fiddling with Google Tag Manager.
Rudderstack web app sign-ups and account creation
In addition to capturing the client-side events in the web app, we also generate server-side events upon user confirmation initial sign-in using our Node.js SDK. These track and identify calls contain less contextual data than the client-side events but are not susceptible to ad-blockers and other browser tools that might prevent RudderStack events from reaching the RudderStack source. Missing signups is rare, but one of the most important events in the customer journey, so we don’t take any chances.
Pro tip: Our product and marketing teams both use Customer.io for messaging. Having both server-side and client-side events allows them to collaborate and easily build segments for behaviorally-triggered transactional emails (i.e., track calls) as well as marketing email campaigns (i.e., hasn’t created a source within 3 days of signing up).
ETL
We use ETL to pull data from multiple sources, including Salesforce, Customer.io, Google Ads, Facebook Ads and Stripe. In this overview, we’ll give you a glimpse of how we use the Salesforce data.
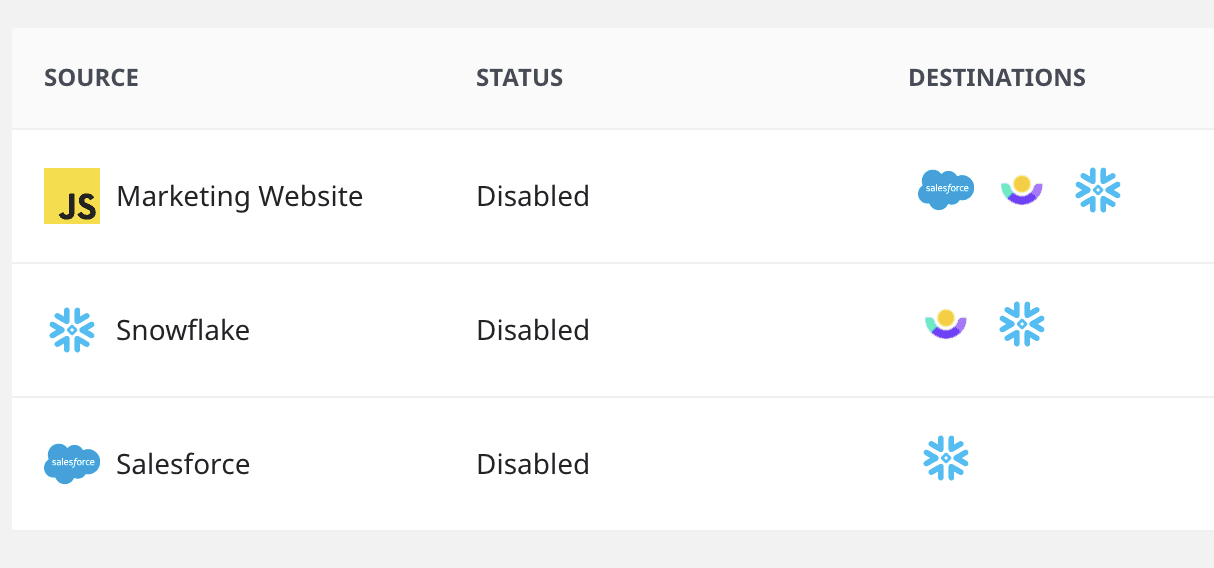
Salesforce - We use RudderStack ETL to load a variety of salesforce objects into snowflake every 24 hours. With updated sales information in Snowflake, we can inform other tools in the stack of a particular lead and account status changes through the use of Reverse ETL (more on Reverse ETL below).
Pro tip: Extracting change history logs for leads and opportunities provides phenomenal insight through event-like data from Salesforce in your warehouse. Not only can you see all of the sales interactions and timelines, but the ability to track field-level edits with user and date-time stamps makes compliance very happy!
Reverse ETL
Snowflake - Reverse ETL are the unsung hero of our stack. Our customers love using the feature, but we also love it ourselves because it’s so darn useful. With all of our customer data captured within Snowflake, Reverse ETL keep all our tools up to date. For example, when a user becomes a customer, the sales team updates the Account Type and Opportunity Status. Then a daily job runs that updates Customer.io and other marketing tools so that those users exit certain marketing campaigns and segments.
Pro Tip: Where do we begin! Opt-Out status flags are a huge concern for every business. Creating a unified view of all of your customers and their opt out statuses for each of your communications channels is paramount and Reverse ETL makes it easy to update that status in every tool and data store across the stack
Real-Time Transformations
We’ve developed a number of user transformations to support a variety of different processes, including mapping and renaming user traits prior to sending them to a cloud destination and excluding anonymous page calls from flowing to a Customer.io. We also use transformations to enhance events and modify payloads prior to passing them to their final destination. For example, when a user submits a request for an enterprise quote, we call the Clearbit API to collect additional account information on that particular business based on the email domain.
Pro Tip: To keep your Transformations code DRY and clean, leverage the Transformations Library to store functions that apply to multiple destinations. For example, our marketing and product teams are constantly testing new signup flows and conversions, so we block all rudderstack.com emails from flowing through to downstream destinations, which keeps our marketing and sales teams very happy.
Library:
JAVASCRIPT
Loading the library into a transformation:
JAVASCRIPT
Destination Transformations
You don’t see these in the UI, but our Destination Transformations in the data plane translate RudderStack payloads into the proper format for each downstream tool, automatically. Said another way, our integrations team has already done the hard work for us, so a single identify call can create a user in Salesforce, Customer.io Intercom and populate the users table in Snowflake.
Pro TIp: You can configure which destinations an event will be sent to by adding the integrations object to your payload. If Salesforce is a destination, the integrations object needs to include Salesforce: true. By default, we send to all other destinations automatically unless you specifically set the value to false (i.e., Customer.io: false).
System Observability via Grafana
System performance metrics are stored in InfluxDB and we monitor the health of all of our pipelines via Grafana, which provides us detailed insights into the performance and status of our RudderStack Cloud instance. Grafana gives us a real-time view of the events ingested, processed and delivered, along with various other metrics like performance under load, errors and delivery statistics. Our SRE team also has Grafana wired to our alerting system.
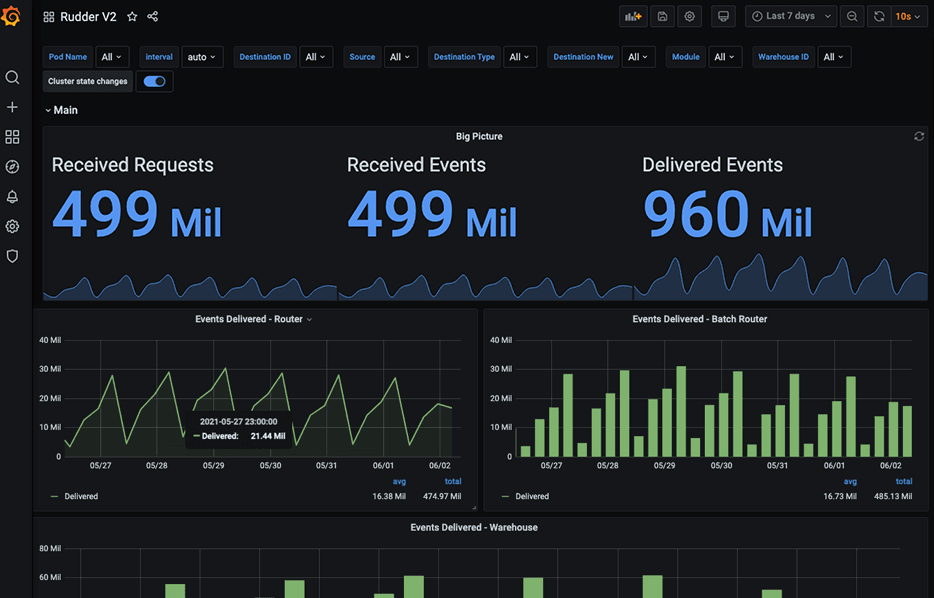
Pro Tip: We provide the same detailed Grafana dashboards we use to our customers, meaning they can get as detailed a view of RudderStack as they want.
Published:
July 26, 2021



Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.
