Blog
How to track AI product usage without exposing sensitive data
How to track AI product usage without exposing sensitive data

Sumanth Puram
Head of Engineering at RudderStack
12 min read
October 9, 2025
Teams deploying AI features—chatbots, assistants, copilots—face a common challenge: measuring their actual impact. Without proper instrumentation, it's difficult to answer fundamental questions such as who's using these features, what users are trying to accomplish, whether the AI is actually helping, and where to focus improvement efforts. While API calls and costs are visible, connecting AI interactions to user behavior and business outcomes requires structured tracking that requires additional efforts.
The first problem is that AI interactions are conversational and unstructured, making them hard to analyze at scale. Second, the raw user prompts often contain sensitive data that can't be stored directly in analytics systems. This creates a measurement gap where teams know their AI features are technically operational but lack the data infrastructure to optimize them, prove value, or even understand basic usage patterns.
This guide presents a standardized event schema for tracking AI interactions that integrates with existing data warehouses and customer data platforms. We define three core events that capture AI interactions, plus an approach to intent classification that preserves privacy.
By the end of this guide, you should be able to adopt our implementation, the code examples, and the best practices to quickly implement analytics for your AI product.
A standard schema for tracking AI features
Without a standard approach, different teams instrument AI features differently, using inconsistent event names, properties, and structures. Data analysts end up writing custom queries for each AI product, dashboards can't show unified metrics, and cross-product comparison becomes nearly impossible.
Similar to RudderStack’s E-commerce Spec and Video Spec, we solved this challenge with an AI Product Spec. This specification defines a standard approach for tracking AI products. It consists of three core events and optional intent classification for privacy-preserving analytics, which are described below:
| Event name | Description |
|---|---|
ai_user_prompt_created | Tracks when a user submits a prompt to your AI system |
ai_llm_response_received | Captures AI system responses and performance metrics |
ai_user_action | Measures user interactions with AI responses |
1. ai_user_prompt_created (capture prompts)
Tracks when a user submits a prompt (query) to your AI system.
When to track: Immediately after user submits their query
Implementation example:
Note: This example uses the RudderStack JavaScript SDK. You may use any library of your choice as long as they follow the Event Spec (e.g. Segment) and allow to develop these new properties on top of the spec.
JAVASCRIPT
Key Properties:
conversation_id: Required. Links all events in a conversationprompt_text: The actual user input (consider privacy implications)
2. ai_llm_response_received (track LLM output)
Captures AI system responses and performance metrics.
When to track: After receiving response from LLM
Implementation example:
JAVASCRIPT
Key Properties:
conversation_id: Must match the prompt eventlatency_ms: Time from request to responsetoken_count: For usage tracking and cost analysisresponse_status: Track failures and timeouts
3. ai_user_action (measure user feedback)
Measures user interaction with AI responses like upvoting, copying the response, sharing, and so on.
When to track: When user provides any actions on top of LLM responses
Implementation example:
JAVASCRIPT
Key Properties:
action_type: Type of user actionaction_details: Properties for the actionfeedback_type: The mechanism of feedbackfeedback_value: Quantifiable feedback metric
Sessions vs conversations in AI interactions
Sessions vs conversations
It is important to distinguish between sessions and conversations for AI interactions. A session represents the automatic browser or app sessions which typically span from when a user opens your application until they close it or remain inactive for a certain period. Session tracking is a common thing which almost every product implements using tools such as RudderStack SDKs.
A conversation, on the other hand, is a specific AI interaction thread that you manage explicitly through the `conversation_id` parameter. The traditional analytics specification does not have this concept.
A single session may contain multiple conversations. For example, a user might start by asking about product features, complete that conversation, then later in the same session start a new conversation about pricing. Each would have its own `conversation_id` while sharing the same `session_id`. This distinction allows you to analyze both the broader user journey (session level) and specific AI interaction patterns (conversation level).
How to link AI product events with conversation
As mentioned earlier, conversation_id is critical for connecting related events within a conversation. Here's how to implement it:
Use conversation_id to connect related events:
JAVASCRIPT
Classify user intent without storing raw prompts
We recommend implementing intent classification for privacy-preserving analytics. In other words, instead of sending raw prompts to all downstream tools, classify prompts into business intents and forward only the classifications.
Why intent classification matters for privacy and analytics
In a traditional system, the user’s intent is generally linked to the button they click or the page url they visit, making it easier to understand the user intent. In AI-powered features, you’ll need the user’s chat message to understand the intent.
But can you send this raw user message to your downstream analytics systems to understand the intent?
Raw prompts often contain sensitive information that shouldn't be stored in warehouses or sent to analytics tools. Intent classification provides a solution.
For example, instead of storing "I need help resetting my password for john.doe@company.com," you store the intent "account_management." This gives you actionable analytics while protecting user privacy.
In order to remain compliant, you'll need to balance analytics depth with privacy requirements. And intent classification provides that. Intent classification transforms unstructured conversation data into actionable business intelligence while protecting user privacy. You track structured intents that enable powerful analytics like user journey mapping, conversion funnels, and cohort analysis.
This approach dramatically reduces data volume and query complexity. Write simple SQL against intent fields instead of parsing millions of text prompts. Most importantly, intent patterns reveal what your users are trying to accomplish, helping you identify feature gaps, optimize AI responses, and prioritize product development based on actual usage patterns rather than guesswork.
How to implement intent classification
In this section, we explore how you can set up intent classification in a few easy steps quickly. In this example, we used OpenRouter for LLM API calls to extract intent from the user message, and we used RudderStack Transformations to make that API request and enrich the incoming user event with the intent information before delivering to a warehouse and other downstream tools. But you may use any other tools as well following a similar strategy.
1. Plan and document intents
- Define 5-10 mutually exclusive intents
- Include an "other" category
- Write clear descriptions for each
2. Get OpenRouter API key
- Sign up at openrouter.ai
- Add credits to your account
- Copy your API key
3. Choose the right model: Intent classification is an extremely simple task for modern LLMs - even basic models can accurately classify intents. Using GPT-4 or Claude for classification is like using a Ferrari for grocery shopping. Check OpenRouter's pricing page and start with cheaper models like openai/gpt-5 nano ($0.05/1M tokens), mistralai/mistral-7b-instruct ($0.25/1M tokens), or even meta-llama/llama-3-8b-instruct hosted on your infrastructure. These smaller models can handle classification just as well as flagship models at a fraction of the cost. For such a simple task, you don’t even need LLM, DistillBERT models will work. Test different models with your actual prompts to find the sweet spot between accuracy and cost.
4. Experiment with your classification prompt: The prompt you use will significantly impact accuracy. You may use tools like OpenAI Playground to test your prompt without coding. When you jump into code, you may test adding different kinds of business context, but too much context might confuse smaller models. Some models work better with examples, others with just descriptions. You may also want to maintain different versions of prompt in your code as well:
JAVASCRIPT
5. Enrich AI events with classified intent using Transformations
With RudderStack Transformations, you can use simple JavaScript code to process incoming customer event data before they are delivered to the warehouse or other downstream tools. So, you may leverage this functionality to make the LLM API call for the intent extraction and enrich the event data with the intent. Here’s how:
- Go to Transformations in RudderStack
- Create new transformation with the code below
- Add your OpenRouter API key in the transformation code and customize intents
- Connect this transformation to sensitive destinations where you planned to send this event data
- Keep raw data for development/debugging environments
Want to see Transformations in action, or do a RudderStack deep dive? Book a demo
Transformation code
Use this RudderStack tran sformation to add intent classification:
JAVASCRIPT
⚠️ Important
Before rolling out to all users, calculate your expected costs. For example: if you have 1000 users generating 100 queries/day at 200 tokens per classification, that will be 1000 × 100 × 200 = 20M tokens/day consumed. If you’re using openai/gpt-5-nano (costs $0.05/M), that will cost $1/day. The cached hits are 10 times cheaper, so the cost can be a lot less than this. For budget purposes, consider this much cost with the gpt-5-nano model and the given constraints. It is recommended to set up expense limits and cost monitoring alerts.
SQL queries to analyze AI feature usage
In this section, we provide example SQL queries for some of the key metrics you may want to track. Using AI Product Analytics Spec while storing the analytics data in your warehouse makes it possible to use these queries without much change as long as you want these metrics to be tracked. RudderStack SDKs follow these specs already, so RudderStack users can directly go ahead and use these queries.
💡 Tip
If you’re in doubt, reach out to the RudderStack support community on Slack.
Track AI usage: Engagement metrics
SQL
Track AI performance: Latency and cost
SQL
Track AI quality: Ratings and feedback
SQL
What to include in your AI analytics dashboard
For real-time monitoring, build dashboards that track active conversations, response latency compared to historical baselines, and error rates broken down by model. This helps you quickly identify and respond to performance issues as they happen.
To understand user behavior, create visualizations showing intent distribution through charts, conversation flows using sankey diagrams to see how users move between intents, and identify peak usage times to optimize resource allocation and support coverage.
Cost management becomes critical at scale, so track token usage by different models, calculate cost per conversation to understand unit economics, and segment costs by user type to identify which segments drive the most AI usage and ensure pricing aligns with value delivered.
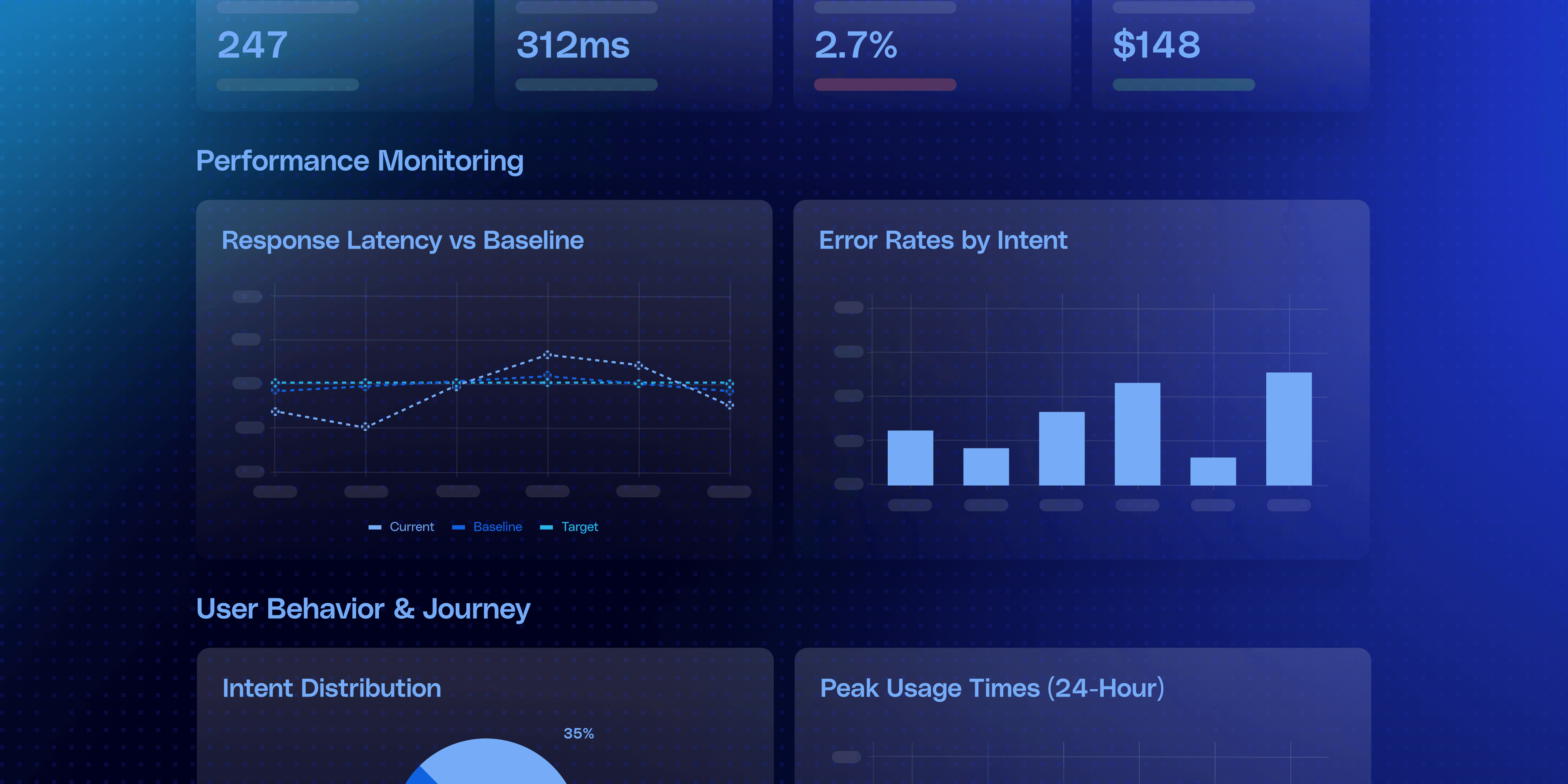
Here’s a sample dashboard we created using Claude Artifacts:
Sample dashboard created using Claude Artifacts
Best practices for rolling out AI tracking
Start with a simple implementation by tracking the three core events first. Once you understand your usage patterns and see what questions you need to answer, you can add intent classification and expand the event properties based on actual analytical needs rather than trying to anticipate everything upfront.
Track errors to improve LLM reliability
Error handling is crucial for maintaining data quality. Always track both successful and failed AI interactions to understand your true system performance:
JAVASCRIPT
Privacy in production, debugging in development
Privacy considerations should be built in from the start, not added later. Decide early what data you'll track versus what you'll classify into intents, implement intent classification for sensitive industries like healthcare or finance, and clearly document your data retention policies for both internal teams and compliance purposes.
During development and testing, use environment-specific configurations to control data sensitivity. This allows you to debug with full data in development while protecting user privacy in production:
JAVASCRIPT
Use sampling to keep costs and latency in check
Intent classification at high volumes requires a strategic sampling approach. While classifying every prompt might work initially, as your AI feature gains adoption and volumes increase, the cost and latency of calling LLMs for every single event becomes prohibitive. Implement sampling strategies that balance comprehensive insights with operational efficiency.
Consider sampling by user ID to get complete conversation flows for a subset of users rather than fragmented data across all users. You might classify all prompts for users where hash(userId) % 100 < 10 to get a consistent 10% sample. Alternatively, prioritize classification for specific cohorts that matter most to your business - new users in their first week to understand onboarding patterns, high-value enterprise customers who need detailed analytics, or users in a specific geographic region you're expanding into.
Here's how to implement intelligent sampling in your transformation:
JAVASCRIPT
Track your sampling rate and adjust based on business needs. Start with a higher sampling rate (maybe 50%) to establish baseline patterns, then reduce as patterns stabilize.
Always maintain 100% classification for critical user segments and consider time-based sampling during peak hours versus off-hours to optimize costs while maintaining visibility when it matters most.
Your framework for privacy-safe AI analytics
In this guide, we introduced a standard schema for AI Product analytics events. We leveraged this standard to implement analytics for AI products using RudderStack JavaScript SDK and Transformations. Our implementation used LLM to classify intent ensuring the tracking follows the privacy compliance. We provided code examples and best practices that you can adopt for your use case. Whether you’re building chatbots, AI assistants, or LLM-powered products, this guide provides a framework tracking and analyzing AI interactions while maintaining user privacy.
This guide is part of RudderStack’s early alpha program for AI Product Analytics. We’re actively developing native platform support for intent classification and would love your feedback on this specification.
Published:
October 9, 2025
More blog posts
Explore all blog posts
How to improve data quality: 10 best practices for 2026
Danika Rockett
by Danika Rockett

AI is a stress test: How the modern data stack breaks under pressure
Brooks Patterson
by Brooks Patterson

Generative AI risks and how to approach LLM risk management
Danika Rockett
by Danika Rockett


Start delivering business value faster
Implement RudderStack and start driving measurable business results in less than 90 days.


