SQL DATETIME explained – An MS SQL primer
7 min read
January 12, 2024
Data types internal representation
The first concept that requires clarification has to do with how SQL Server stores the different data types. To begin with, all date and time-related data types are not stored in any human-readable format. In contrast to common belief, the data types of this kind are stored either as a set of floats or as a set of integers. The exact type being stored has to do with the actual DateTime data type.
The most widely used one is the DATETIME (look here), as it has been present since the earlier versions of MS SQL Server. When choosing the DATETIME data type, the timestamp is internally represented by two integers: The first represents the date, and the second is the time. Translating in bytes, the DATETIME type takes up 8 bytes, 4 bytes for storing the date, and 4 for storing the corresponding time.
As a baseline for this representation has been set the 1/1/1900 00:00:00. Negative numbers represent dates prior to the baseline.
So, if one wants to check the internal representation of a value of type DATETIME, the varbinary() function can convert the initial data into a hex number. By converting this hex into an integer, dates prior to the baseline date are indeed negative numbers while the date after this date is positive.
According to the documentation, the time precision of the DATETIME type is set to 0 at midnight and increments by 1 every 0.003333… seconds.
Apart from DATETIME, some other data types, including DATETIME2, TIME, and DATE, alternatives to DATETIME, are internally represented a bit differently.
In these types, the representation precision is set to 7 bytes. The first out of them is used to store precision, the last three to store date and those in between to store time. The larger the specified precision, the larger the number of bytes devoted to this.
Language dependent data types
Another important topic in MS SQL Server has to do with the fact that the MS SQL Server settings are not universal. Depending on the language that you have set during configuration, the format of the DATETIME data type can be different. Indicatively is the difference between the representations when the language set is British and US.
Suppose we have a date formatted like this: ‘DD/MM/YYYY HH:MM:SS’. While the SQL Server will successfully interpret this input as DateTime if the language is set to British, it will probably throw an exception for English_US setup. Wondering why? It is because in the second case, SQL Server will try to interpret the DD as Month. So, even in cases where the day is by coincidence at most 12, thus interpretable as months too, you will end up producing nonsense.
In order to avoid any confusion, there are two options to choose from. The first has to do with choosing a data type that is type and language independent. The two formats that satisfy this condition are the one specified by the ISO8601 (2017-11-13T14:00:14Z) and the YYYYMMDD.
Another option, the most preferable, is moving from DATETIME to DATETIME2 (look here), which is not affected by language configuration.
Taking timezone into consideration
And what is going on in cases where the timezone of the events stored in a database is not the same? 2017-11-13T14:00 is a completely different point in time depending on where you are and this can make a huge difference in all sorts of applications, especially in those that have to do monitoring of critical processes, such as a server’s uptime.
At this point, it becomes evident why knowing the internal representation of each data type is useful. Based on what we have mentioned before regarding the internal representation of DATETIME, DATETIME2, DATE, and TIME, it becomes evident that none of them is actually sufficient for this work since they do not specify any timezone leading to ambiguous types. The is no way to distinguish if timestamps are measured based on the local machine’s timezone, on UTC, or according to the server time.
The best way to avoid wrong aggregations of data measured in a different timezone is by working with the DATETIMEOFFSET format. The representation of this data type, apart from what we mentioned before, also includes two extra bytes for storing the timezone offset from the UTC.
In case you want to compare a DATETIMEOFFSET (look here) column with the current timestamp you can use the SYSDATETIMEOFFSET function which returns current datetime with an offset from UTC or the DATENAME if only the offset is needed.
In case you want to change the datetimeoffset, Microsoft SQL Server have you covered too. The function that implements exactly this functionality is the SWITCHOFFSET(), which takes the input data of type DATETIMEOFFSET along with the desired timezone and performs the conversion.
Datetime values in search conditions
A sneaky and insidious pitfall that will cause you a lot of trouble if not handled with caution. Assume you have defined a column of type DATETIME, DATETIME2 or DATE and have populated it with data like 2017-11-13 14:00:14.234 and 2017-11-13 00:00:00.000.
Now let’s assume that later on, you want to retrieve all the records that refer to that specific day, 2017-11-13. A first approach would probably be to write something like this:
JSX
In this case, what MS SQL Server will return is only the record with date = 2017-11-13 00:00:00.000. So long story short, what is going on is that when you are trying to retrieve data of a data type that stores both date and time, without specifying the time, SQL Server assumes that you mean midnight and so “fills up” the given date with the midnight timestamp.
Datetime data rounding
The date rounding operations that the SQL Server performs for date/time data types can be a complete headache for someone who wants to perform analytic processes that require a high degree of precision. Although some precision restrictions do exist inevitably as all data type have a finite precision, there are also cases where rounding mechanisms are triggered out of the blue, causing weird behavior.
So assume that you want to store the datetimes presented in the following tables as DATETIME2:
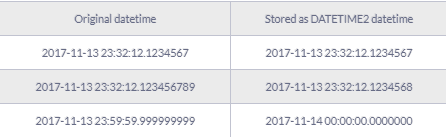
Obviously, SQL Server has rounded the initial dates by paring the nine digits down to seven. This behavior is completely predictable as the DATETIME2 precision is by default 7 digits. Although this may cause some misunderstanding at first like in the third case where we moved to the next day, the behavior can be predicted and thus avoided.
Yet, there are other cases where things get more blur. For example, assume we have a similar example with the one before. This time we are going to use the DATETIME data type and the input date will have 3 digits precision (as many as DATETIME supports) and observe the outcomes:
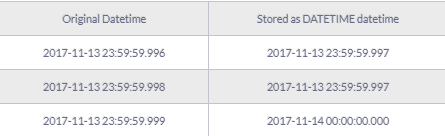
This is happening because DATETIME stores data in increments of .000, .003, and .007. Thus, .996 and .998 get rounded to .997 and .999 to .000, having jumped to the next second.
Conclusion
It seems that, after all, no behavior is unexplainable when it comes to databases. In contrast, everything works in a pretty deterministic and predictable way if only you acquire some knowledge regarding your system’s “internal stuff”.
By understanding how things are getting stored, how certain functions are implemented, and what assumptions are made during architectural design, you can avoid unexpected results and save yourself from a lot of frustration and effort.
Sign Up For Free And Start Sending Data
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app.
Published:
January 12, 2024
Get started today
Start driving better business outcomes with your customer data in less than a week
Book a demo
Explore use cases with an expert and see RudderStack in action.
Implement RudderStack
Start collecting and enabling real-time customer data everywhere it's needed.
Drive better outcomes
Supercharge your analytics, product, growth, and AI teams.