Blog
RudderStack Profiles vs. SQL for Customer 360: The benefits of declarative data modeling
RudderStack Profiles vs. SQL for Customer 360: The benefits of declarative data modeling

John Wessel
CTO, Mentor, & Data Consultant
9 min read
May 10, 2024

In the pursuit of a comprehensive customer 360 view, many data teams find themselves at a crossroads: should they invest in a dedicated tool like RudderStack Profiles or have their team write SQL to build the customer 360 themselves?
RudderStack Profiles delivers a workflow that simplifies customer 360 data modeling. Instead of writing complex code, you define your ID graph and feature spec through a simple YAML config. Profiles takes this input and uses semantic models to generate the SQL queries required to produce the customer 360. But if Profiles is just writing SQL, why not do it yourself?
While it may seem like a straightforward choice to leverage your existing skills and tools, the reality is that hand-rolling a customer 360 with SQL leads to significant challenges, especially as complexity and scale increase (and new data sources are added). If you build from scratch, you won’t be able to power your business with reliable, complete customer profiles because you’ll spend all of your time fighting data problems and doing maintenance.
Here, we’ll look at the long-term challenges DIY creates and explain how RudderStack Profiles provides a solution that delivers speed, agility, and completeness without compromising reliability, transparency, or control. We’ll also look at how Profiles complements your existing customer data modeling work.
The allure of DIY
Many companies begin implementing custom SQL to overcome the limitations of their legacy marketing CDPs, which often can’t ingest comprehensive customer data and have opinionated data models that don’t support complex business logic. Worse yet, when users unfamiliar with the data are given the ability to manipulate it, data quality suffers.
Here’s an example from a real data team:
"[Our marketing CDP] offers the ability for marketers to create new field definitions and write SQL, which is sexy as the first sales pitch, but it's just a disaster over time because there are 500 fields that mean almost the same thing, and no one knows what they mean. And the data is stuck in their system, so we can't use it in our external reporting tools."
Chief Architect, Major online DTC retailer
When you face the limitations of SaaS and start writing SQL, it’s tempting to continue down that path and just build the data set your company needs yourself. There are two broad approaches: using native SQL tools in your warehouse or using a data transformation framework like dbt or SQLmesh.
Modeling for Customer 360 with native SQL
Using native SQL tools in your warehouse provides complete flexibility and control over data transformations. You can write custom queries to join data from various sources, apply business logic, and create the exact customer 360 views required. This approach utilizes your team's existing SQL skills and allows direct work within the data warehouse environment.
However, as data volume and complexity grow, managing everything with hand-written SQL becomes increasingly challenging. Schema changes, data lineage maintenance, query performance optimization, and data quality assurance demand significant time and effort. Furthermore, manual SQL code updates, necessitated by new data sources or changing business requirements, can be error-prone and time-consuming.
Major Drawbacks:
- Complexity nightmare at scale: Lack of structure leads to a tangled mess of data as volume and complexity explode.
- Update headaches: Modifying SQL code without shattering existing queries is an error-prone, time-sucking ordeal.
- Inefficiency: Poorly optimized queries can kill your performance, blow up your expenses, and create long delays for marketing data requests.
Minor Benefits:
- Flexibility: Offers complete control over data transformations.
- No additional tools required: Leverages existing SQL skills and data warehouse environment.
Modeling for Customer 360 with dbt/SQLMesh
To streamline processes and manage growing complexity, data transformation frameworks like dbt or SQLmesh can help address some of the challenges associated with native SQL. These tools provide a structured approach to data modeling, allowing you to define transformations as modular, reusable SQL queries. Benefits include version control, documentation, and dependency management, facilitating collaboration and simplifying maintenance of your data pipeline.
Nevertheless, while these frameworks can help organize SQL transformations, they don't fundamentally alter the fact that you're still hand-writing SQL to build your customer 360. Designing and implementing data models, handling data quality issues, and optimizing query performance remain your responsibility. As data complexity increases, you may find yourself dedicating more time to data engineering and modeling tasks than actually uncovering customer insights or delivering data to drive business value.
Major Drawbacks:
- Not built for customer 360: Lacks the specialized tools needed for identity resolution and customer data unification.
- SQL slog: Still demands hand-rolling complex, time-consuming SQL for identity resolution and feature computation.
Minor Benefits:
- Software engineering best practices: Brings version control, documentation, and dependency management to analytics.
- Flexibility: Provides a structured approach to data modeling with modular, reusable SQL queries.
The problem with SQL-based Customer 360 modeling
You can build a customer 360 using SQL and tools like dbt, but it comes with significant challenges that will erode your ability to create a competitive advantage with your customer data (the whole point of the customer 360 in the first place). Here’s what you’ll be up against if you hand-roll your customer 360 modeling:
- Performance bottlenecks as the dataset grows
- Increased development time and costs to maintain and update models
- Difficulty maintaining matching rules across disparate datasets
- Risk of breaking the system with even minor tweaks
Spending your time troubleshooting complex SQL queries when you could be adding new customer features is never a good feeling. Taking away the complexity allows quicker time to value for crucial business projects that actually move the needle.
At RudderStack, we experienced these challenges firsthand when attempting to solve identity resolution and customer journeys using SQL and dbt. The complexity and maintenance burden proved to be substantial, a sentiment echoed by many of our customers.
Writing SQL to create customer profiles yourself can be time-consuming, error-prone, and difficult to scale as data complexity grows. RudderStack Profiles solves these challenges by providing a reliable, complete, and low-maintenance solution that enables you to rapidly model customer profiles in your warehouse, allowing you to focus on delivering powerful, data-driven customer experiences instead of expensive data wrangling.
Power your business with reliable, complete customer profiles
Schedule a demo with our team today to find out how RudderStack Profiles can help you solve identity resolution at the root so you can create value faster.
The power of declarative data modeling with Profiles
Profiles introduces a declarative approach to data modeling designed explicitly for customer 360 use cases. Instead of handwriting intricate SQL, Profiles allows you to define your business logic and data sources in a YAML configuration, then automatically generates the necessary SQL to build an identity graph and compute features on top of it.
It drastically simplifies the process, so you can rapidly model complete customer profiles in the data warehouse and focus on helping every team use the data to deliver powerful customer experiences.
To drive this home, let's compare some example code for stitching identities together. Below is the YAML for stitching in Profiles:
Identifies table definition
YAML
Tracks table definition
YAML
User ID stitching
YAML
That’s a few simple steps and less than 50 lines of code to stitch user identities together!
DIY SQL profiles
Now, let's look at the SQL required to get this same outcome without Profiles. The below are simplified snippets that would actually be thousands of lines of SQL in a complex scenario. We estimate that RudderStack Profiles typically results in 80%+ less code to write, manage, and maintain!
Create temporary tables for the initial user mapping. Sample is provided below. [50+ lines of code]
SQL
Create your stitching logic. Sample is provided below. [200+ lines of code]
SQL
Now, create logic for merging user IDs. Sample is provided below. [75+ lines of code]
SQL
Bring it all together in a view. Sample is provided below. [Another 50+ lines of code]
SQL
The examples above are just for building a basic, deterministic identity graph, but to build a customer 360 table, you would have to extend the model to compute features for each user as well. With Profiles, computing features is as simple as writing basic declarative statements that automatically generate the SQL required to compute features over the identity graph. Here’s an example of how you would build features in Profiles:
YAML
Move faster with RudderStack Profiles declarative data modeling
By abstracting away the low-level details, Profiles empowers you to focus on delivering value to your business rather than grappling with complex SQL. As Wei Zhou, Director of Data Engineering at Wyze, put it:
"When you have the power of RudderStack in hand, you can blast off immediately. It's so much easier to build a machine learning model once your designs are driven by clean data, useful user features, and complete 360 customer views."
Profiles elegantly handles the challenges of customer 360 modeling with Native SQL or dbt/SQLMesh. Here’s what you get when you leverage Profiles instead:
- Reduced complexity and maintenance burden
- Seamless integration of new data sources
- Transparency and portability (all of the code runs transparently in your warehouse)
- Faster time-to-value for business stakeholders
Best of all, if you’ve already done modeling work with SQL and dbt, it’s not wasted. In fact, most of our customers running Profiles use it in tandem with dbt.
Profiles + dbt: Better together
Profiles isn’t a replacement for dbt, it’s a complementary tool. Many of our customers use dbt for baseline data cleaning and modeling across all data types, with the results serving as inputs for Profiles projects.
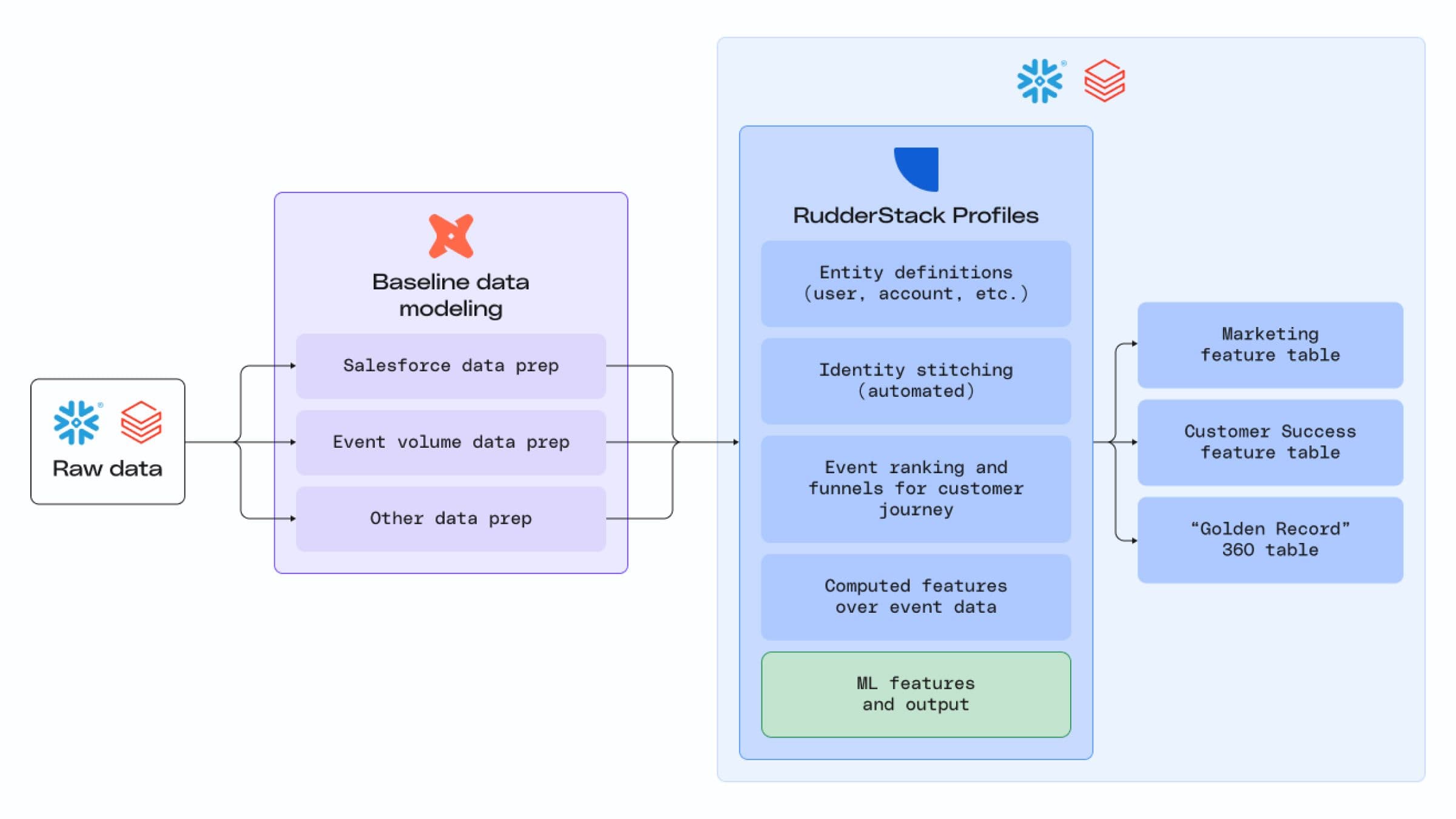
At RudderStack, we use dbt for tasks like shaping raw data, combining data for reports and analyses, and streamlining data workflows. For example, understanding customer utilization requires combining monthly event volume data (cleaned and aggregated using dbt) with product usage data. We use the resulting "utilization table" in multiple analytics use cases. However, when it comes to the tricky tasks of identity resolution and feature computation for our Customer 360, we turn to the purpose-built tool – Profiles.
Get started
As the demands on data teams continue to grow, investing in purpose-built tools like Profiles is becoming increasingly essential. If you want to deliver more value to your business, the ability to rapidly build and iterate on a customer 360 without getting bogged down in complex SQL is key. Do it yourself with dbt + SQL, and you run the risk of spending all your time wrangling data instead of powering critical business use cases to create a competitive advantage.
To learn more about how Profiles can help you power your business with reliable, complete customer profiles, schedule a demo with our team today.
Power your business with reliable, complete customer profiles
Schedule a demo with our team today to find out how RudderStack Profiles can help you solve identity resolution at the root so you can create value faster.
Published:
May 10, 2024
More blog posts
Explore all blog posts
Salesforce data enrichment: Best tools for 2025
Danika Rockett
by Danika Rockett

CIAM: What is customer identity and access management?
Danika Rockett
by Danika Rockett

Deterministic vs. probabilistic models: A guide for data teams
Danika Rockett
by Danika Rockett


Start delivering business value faster
Implement RudderStack and start driving measurable business results in less than 90 days.


