What is a Headless CDP?



Many of us in the industry have stated ad nauseum that the current CDP architecture is not working (see our thoughts here and here, and industry data here). Every vendor claims they are the solution to the problem and most ignore the fact that it will take an ecosystem to solve for all of the customer data use cases across such a wide variety of tools and downstream teams.
CDPs came into existence to solve two problems with existing toolsets:
- Customer data ingestion at scale: Traditional marketing suites (think Salesforce, Oracle, Adobe) were not designed to handle multiple kinds of customer data at scale. This problem became especially acute with the explosion of first party data sources and digital touchpoints. There had to be a dedicated data layer to collect and make sense of all that data.
- Omni-channel experiences: Early marketing tools were built for delivering digital experiences in one channel, primarily email, but digitization required an increasing need to reach customers on multiple channels, from email to SMS to mobile to ad platforms.
CDPs attempted to solve both of these problems, but being both a data layer and cross-channel marketing platform is extremely hard. The technology itself is complex, but the bigger challenge is that the buyer and user personas for each component are very different.
CDPs failed at #1 as they were traditionally built for (and sold to) marketing teams with limited buy-in and support from data and engineering teams. Building a data layer that can not only ingest data at scale from any source but also ensure the data is clean and trustworthy data requires performant APIs, SDKs, pipelines, monitoring, governance, and more. These non-trivial technical requirements demand tooling built for data and engineering teams.
In terms of problem #2, both marketing suites and marketing tools evolved and got really good at activation through omni-channel messages (often calling themselves CDPs) and diminishing the need for a standalone CDP. Still, these more advanced marketing tools too lacked robust data, which meant that few marketing teams could use them to their full potential. Neither CDP providers or these more advanced marketing tools addressed the core issue.
Even today, if you ask marketing teams (or any other team) what their number one problem is, the answer almost always relates to data, regardless of the level of sophistication in the tooling they use. It’s little surprise that traditional CDPs have not been able to live up to the hype.
Reinventing the customer data platform
The CDP needs to be reinvented. Instead of trying to be the source of truth for customer data (problem #1) or compete with the UI/workflow/delivery layer (problem #2), the CDP should really be trying to solve the fundamental challenge faced by all stakeholders: business teams, whether it’s Marketing, Sales, Product, Customer Success, or Data Science lack access to a complete view of the customer.
The massive adoption of cloud data warehouses as the place to build a 360º view of the customer (problem #1) presents the foundation for an elegant solution: a “headless customer data platform” architecture that serves as the connective tissue between customer data, the cloud data warehouse, and the rest of the stack.
What is a Headless CDP?
A Headless CDP is a tool with open architecture, purpose built for data and engineering teams, that makes it easy to collect customer data from every source, build your customer 360 in your own warehouse, then make that data available to your entire stack. Like other headless architectures (i.e., headless CMS), the primary function of the headless CDP is hydrating the warehouse and business tools with data—not serving as the data store or the data interface.
This architecture solves all of the pain points of traditional CDPs and other business tools:
- Data teams don’t have to build expensive infrastructure in-house or deal with limited marketing tools, but still have full control over data management and access to the customer 360. This enables them to focus on adding value through analytics and machine learning use cases instead of spending time on managing pipelines or cleaning data.
- Marketing (and every other business team) can use their tools of choice (their front-end ‘interface’) no matter how it integrates with the warehouse or the headless CDP (more on integration patterns below). Because their tools have access to the full customer 360, they can use them to full potential.
- No one has to use software that only solves part of their problem and wasn’t built with their specific team in mind.
This architecture creates a separation of technological concern in the tech stack between the different teams that interact with customer data. Data teams are responsible for data ingestion into the warehouse or directly to APIs, running models (dbt/sql/yaml) to build the customer 360 in the warehouse, and exposing that data to the business teams that need the data (hydration). Business teams (marketing, product, customer success, etc.) can activate that data using their tools and workflow of choice.
Here is a very high level diagram of how the headless CDP architecture hydrates marketing tools:
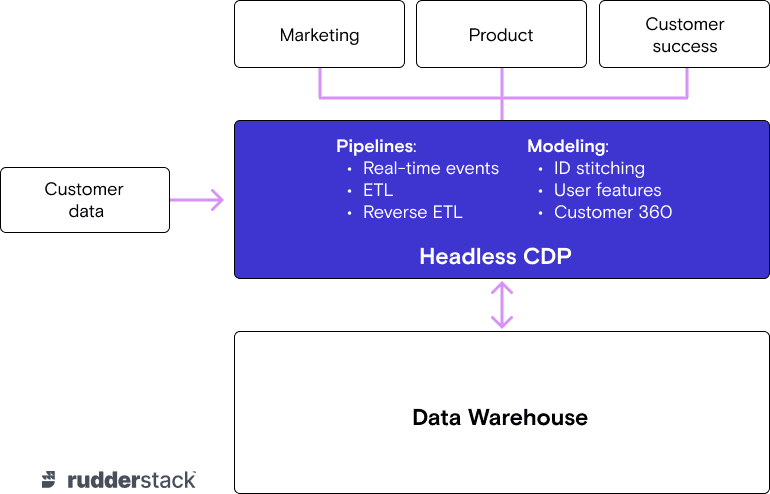
The beauty of this architecture is that it doesn’t force either the data team or the business teams to adopt a single, prevailing integration pattern for putting the customer 360 to work across downstream systems.
Consider marketing tools: there are multiple patterns for using both real time data and data generated in the warehouse. Because the Headless CDP focuses on collecting data and building the 360º customer view in the same warehouse, marketing teams can bring whatever SaaS tool and connection type they want.
Here are a few specific examples:
- Tools like Salesforce and Braze are building direct integrations into the data warehouse to pull data into their ecosystems. More and more vendors will eventually build out these capabilities and this will likely be the most popular way of working with the headless CDP, in addition to using it for real time streaming of data where needed.
- There is a long tail of tools that don’t have native connections to the warehouse, or need 1st party data sent directly to their API (most often for real-time use cases). For those tools, the Headless CDP itself is responsible for managing the connection and delivering or syncing data.
- Finally, a set of new generation tools like MessageGears and SuperGrain run natively on top of the data warehouse. Existing reverse ETL vendors like Hightouch and Census are likely to build competing capabilities. The headless CDP fully supports both patterns with the customer 360.
Conclusion
Cloud data warehouses have solved the data problem and business tools are better than they ever have been. Now is the time for a robust layer that completes the relationship between the data stack and the business stack—the headless CDP.
Published:
October 11, 2022

Event streaming: What it is, how it works, and why you should use it
Event streaming allows businesses to efficiently collect and process large amounts of data in real time. It is a technique that captures and processes data as it is generated, enabling businesses to analyze data in real time


How Masterworks built a donor intelligence engine with RudderStack
Understanding donor behavior is critical to effective nonprofit fundraising. As digital channels transform how people give, organizations face the challenge of connecting online versus offline giving.


How long does it take you to see a customer event? If it's over five seconds, you're missing out
Access to real-time customer data is no longer a luxury. This article explains how a modern, modern, real-time infrastructure can help you close the gap between customer intent and action—before it’s too late.



