Sync data from Google Sheets to your warehouse destination via RudderStack.
5 minute read
Cloud Extract (ETL) is sunset
This source is deprecated and no longer supported as of January 10, 2026.
Google Sheets is a popular spreadsheet program that lets you create and manage your spreadsheets.
This document guides you in setting up Google Sheets as a source in RudderStack. Once configured, RudderStack automatically ingests your Google Sheets data and routes it to your specified data warehouse destination.
Go to Sources > New source > Cloud Extract and select Google Sheets from the list of sources.
Assign a name to your source and click Continue.
Connection settings
Next, configure the following dashboard settings:
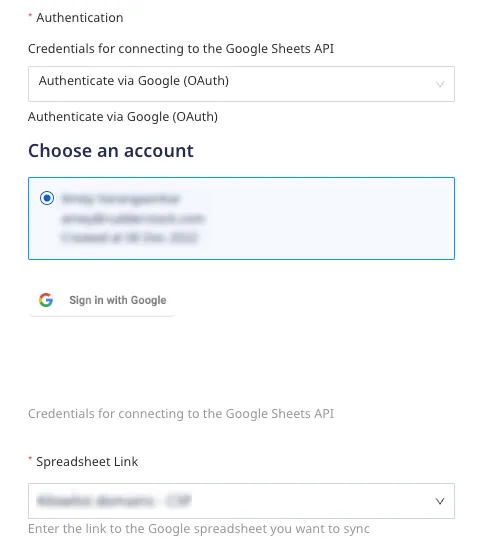
Authentication: From the dropdown, select the authentication mechanism for RudderStack to connect to the Google Sheets API.
Authenticate via Google (OAuth): To authenticate via OAuth, click the Sign in with Google button, select your Google account, and give RudderStack the required permissions.
Service Account Key Authentication: Enter your service account JSON credentials in the Service Account Information field.
Spreadsheet Link: Enter the spreadsheet’s URL from which RudderStack should ingest and sync the data.
For the Authenticate via Google (OAuth) authentication option, RudderStack will automatically populate all spreadsheets associated with the account.
For the Service Account Key Authentication option, you need to first provide access to the required spreadsheet. Only the spreadsheets for which you provide the access will be listed in the dropdown. For more information, refer to the FAQ section below.
Destination settings
The following settings specify how RudderStack sends the data ingested from Google Sheets to the connected warehouse destination:
Table prefix: RudderStack uses this prefix to create a table in your data warehouse and loads all your Google Sheets data into it.
Note that RudderStack does not add special characters like - or _ to the prefix by default. Hence, you need to specify it while setting the prefix.
Schedule Settings: RudderStack gives you three options to ingest the data from Google Sheets:
Basic: Runs the syncs at the specified time interval.
CRON: Runs the syncs based on the user-defined CRON expression.
Manual: You are required to run the syncs manually.
For more information on the schedule types, refer to the Common Settings guide.
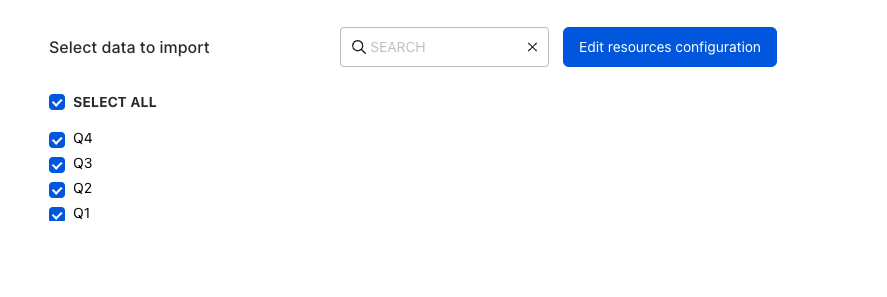
Selecting the data to import
You can specify the Google Sheets data you want to sync by selecting the required sheet. You can also sync data from multiple sheets within the spreadsheet:
RudderStack considers the first row of each sheet as the header. Empty sheets or sheets with an empty header will not be reflected in the Select data to import window.
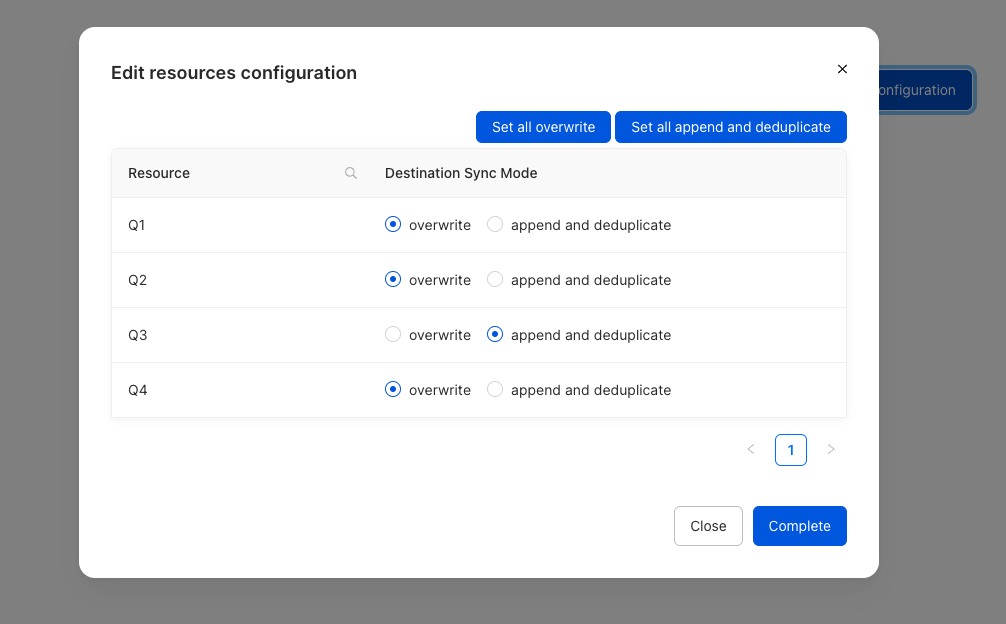
You can also define the sync mode for each data resource you want to send to the destination. Click Edit resources configuration and specify the destination sync mode for the selected resource(s):
Overwrite: RudderStack adds new rows in the warehouse destination and deletes the rows from previous syncs. This is the default sync mode.
Append and deduplicate: RudderStack adds new rows and updates modified records in the warehouse destination in each sync.
The following destinations support the above sync modes:
Snowflake
Postgres
MySQL
BigQuery
Google Sheets is now configured as a source. RudderStack will start ingesting data from Google Sheets as per your specified schedule and frequency.
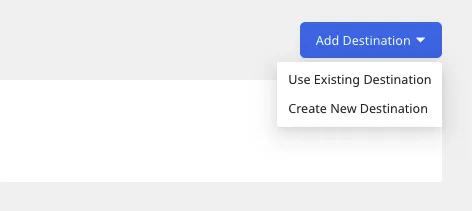
You can further connect this source to your data warehouse by clicking the Add Destination button:
Use the Use Existing Destination option if you have an already-configured data warehouse destination in RudderStack. To configure a data warehouse destination from scratch, select the Create New Destination button.
How RudderStack syncs data to the warehouse
If you select multiple sheets in the Select data to import window, RudderStack creates multiple tables (corresponding to each sheet) in the warehouse.
In the above example, RudderStack creates a table corresponding to each sheet (List of Tracking Plans, Import Template, and so on) in the warehouse.
While syncing data to the warehouse, RudderStack creates columns only for the headers (first rows in the sheet) which also have data present in the second row (mandatory) and beyond (optional).
The mere presence of a header does not create a column in the destination.
FAQ
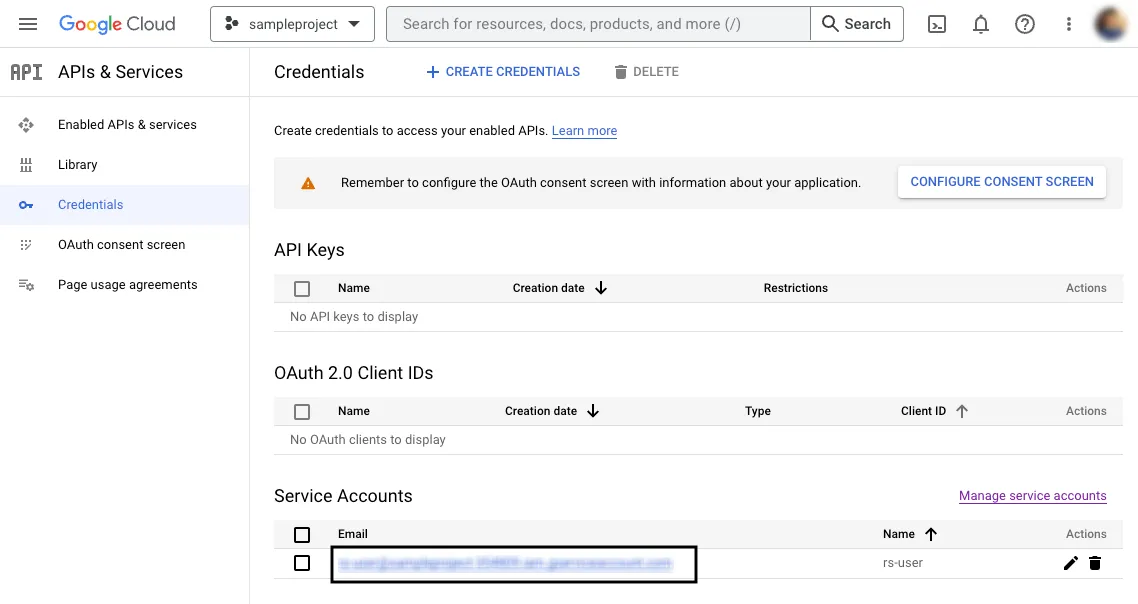
How do I provide service account access to a Google sheet?
If you’re using a service account to authenticate RudderStack to sync your Google Sheets data, you must also give the required access to the service account to access the required spreadsheet. Follow these steps to provide access to the required spreadsheet:
Under Service Accounts, copy the email address listed under Email.
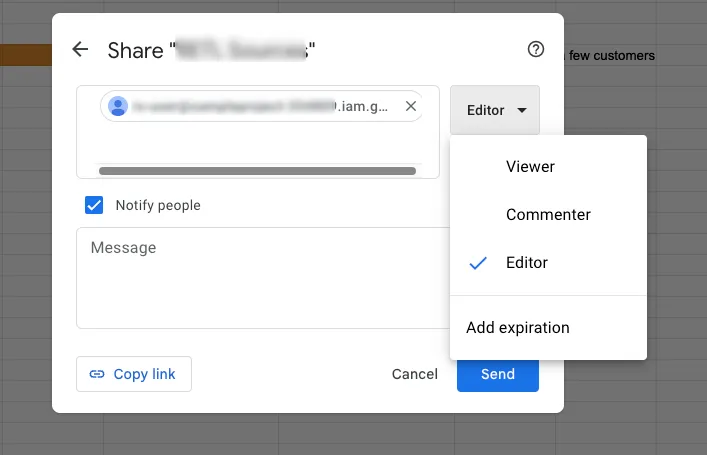
Go to the spreadsheet, click the Share button and paste the email copied above. Specify the permission you want to assign to this email.
Finally, click the Send button.
If you get the Share outside of organization popup, click Share anyway.
The Google sheet will now be accessible in the dropdown. RudderStack can now access the sheet and sync the data from it.
Is it possible to have multiple Cloud Extract sources writing to the same schema?
Yes, it is.
RudderStack associates a table prefix for every Cloud Extract source writing to a warehouse schema. This way, multiple Cloud Extract sources can write to the same schema with different table prefixes.
How does RudderStack count the events for Cloud Extract sources?
RudderStack counts the number of records returned by the source APIs when queried during each sync. It considers each record as an event.
How does RudderStack set the table name for the data sent via Cloud Extract sources?
RudderStack sets the table name for the resource you are syncing to the warehouse by adding rudder_ to the Table prefix you set while configuring your Cloud Extract source in the dashboard.
For example, if you set test_ as the Table prefix in the dashboard, RudderStack sets the table name as test_rudder_<resource_name>, where <resource_name> is the name of the resource you are syncing (for example, contacts, messages, etc.).
Note that RudderStack does not add the character _ to the prefix by default. Hence, you need to specify it while setting the prefix.
Questions? We're here to help.
Join the RudderStack Slack community or email us for support
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.