Go to Sources > New source > Cloud Extract and select Facebook Marketing from the list of sources.
Assign a name to your source and click Continue.
Connection settings
Click Connect with Facebook Marketing and grant RudderStack the necessary permissions to access your Facebook Marketing data.
Your Facebook account and the related details will then automatically appear under Choose an account.
Then, configure the following settings:
Account ID: Enter the Facebook Ads account ID that RudderStack uses to pull the data from the Marketing API.
Start Date: Specify the date from which RudderStack should replicate the data for all incremental streams. RudderStack will not sync any historical data generated before this date.
End Date: RudderStack syncs all data generated between Start Date and this date. If you do not specify this date, RudderStack will sync all latest available data.
Include Deleted: Enable this setting to include the data from all deleted campaigns, ads, and ad sets.
Fetch Thumbnail Images: Enable this setting to fetch and store the thumbnail data for each Ad Creative.
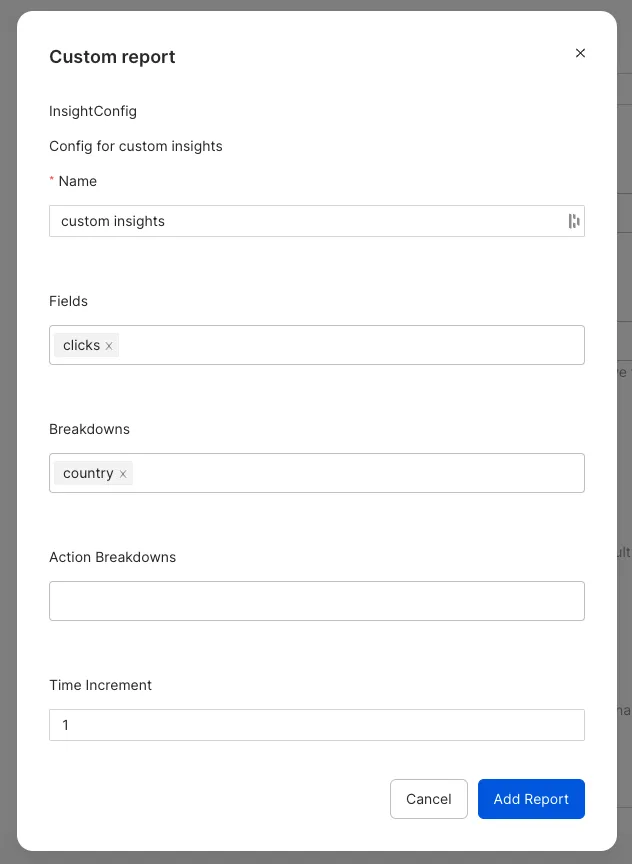
Custom Insights: This setting lets you add a list containing the ad insights entries. You can specify the following configuration settings by clicking the Add Item button:
Page Size of Requests: Use this option to specify the number of records per page when the Marketing API response has pagination.
It is not recommended to set this field unless you want to fine-tune the connection for addressing specific issues or use cases.
Insights Lookback Window: Specify the number of days in the attribution window.
Maximum Size of Batched Requests: Specify the maximum batch size to use when sending batch requests to the Marketing API.
It is not recommended to set this field unless you want to fine-tune the connection for addressing specific issues or use cases.
Allow Empty Action Breakdowns: Enable this setting to allow action breakdowns to be an empty list.
Destination settings
The following settings specify how RudderStack sends the data ingested from Facebook Marketing to the connected warehouse destination:
Table prefix: RudderStack uses this prefix to create a table in your data warehouse and loads all your Facebook Marketing data into it.
Note that RudderStack does not add special characters like - or _ to the prefix by default. Hence, you need to specify it while setting the prefix.
Schedule Settings: RudderStack gives you three options to ingest the data from Facebook Marketing:
Basic: Runs the syncs at the specified time interval.
CRON: Runs the syncs based on the user-defined CRON expression.
Manual: You are required to run the syncs manually.
For more information on schedule types, see Common Settings.
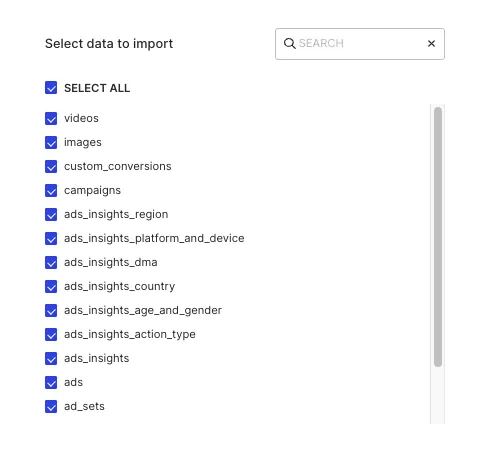
Selecting the data to import
You can choose the Facebook Marketing data you want to ingest by selecting the required resources:
The below table mentions the syncs supported by these resources from Facebook Marketing to your warehouse destination:
For more information on the Full Refresh and Incremental sync modes, see Common Settings.
Facebook Marketing is now configured as a source. RudderStack will start ingesting data from Facebook Marketing as per your specified schedule and frequency.
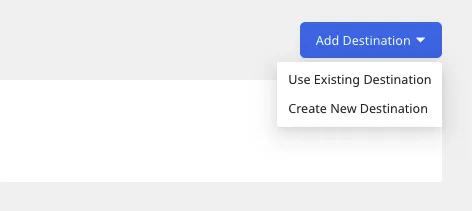
You can further connect this source to your data warehouse by clicking on Add Destination:
Use the Use Existing Destination option if you have an already-configured data warehouse destination in RudderStack. To configure a data warehouse destination from scratch, select the Create New Destination button.
FAQ
Is it possible to have multiple Cloud Extract sources writing to the same schema?
Yes - RudderStack implements a feature wherein it associates a table prefix for every Cloud Extract source writing to a warehouse schema. This way, multiple Cloud Extract sources can write to the same schema with different table prefixes.
How can I avoid sync errors due to rate limits?
To avoid sync errors due to rate limits, set the Page Size of Requests setting to 500 from the default value of 50. This allows RudderStack to make fewer calls to the Facebook API. Note that the maximum value for this setting is 1000.
How does RudderStack count the events for Cloud Extract sources?
RudderStack counts the number of records returned by the source APIs when queried during each sync. It considers each record as an event.
How does RudderStack set the table name for the data sent via Cloud Extract sources?
RudderStack sets the table name for the resource you are syncing to the warehouse by adding rudder_ to the Table prefix you set while configuring your Cloud Extract source in the dashboard.
For example, if you set test_ as the Table prefix in the dashboard, RudderStack sets the table name as test_rudder_<resource_name>, where <resource_name> is the name of the resource you are syncing (for example, contacts, messages, etc.).
Note that RudderStack does not add the character _ to the prefix by default. Hence, you need to specify it while setting the prefix.
Questions? We're here to help.
Join the RudderStack Slack community or email us for support
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.