This guide covers the common destination-specific settings to be configured while setting up your Cloud Extract sources. Common settings include: table prefix, schedule settings, and sync modes.
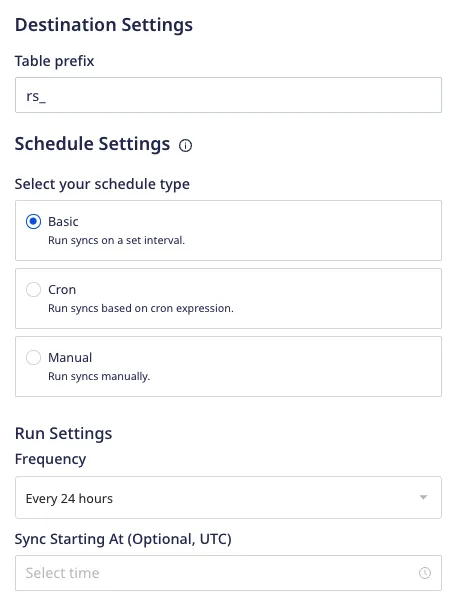
Table prefix
RudderStack uses your specified table prefix to create a table named prefix_table_name in your data warehouse and load all imported source data into it.
If you do not specify a prefix, RudderStack creates a table in your warehouse as table_name, where table_name refers to the resource you are importing.
For example, if you set the prefix to rs_ and the resource you are importing is named valid_emails, then RudderStack creates the table rs_valid_emails in the warehouse.
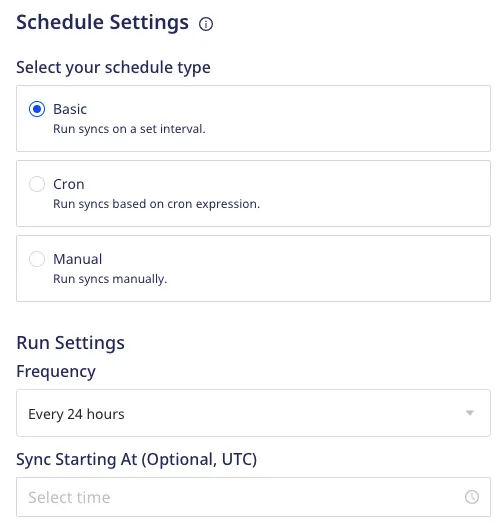
Schedule settings
RudderStack lets you set a schedule for importing data from your Cloud Extract sources while setting them up in your dashboard. It lets you specify the schedule type that defines how and when the syncs will run.
RudderStack supports the following three schedule types:
Schedule type
Description
Basic
Run syncs at a given time interval and specified time.
CRON
Run syncs based on a CRON expression defined by the user.
Manual
Run syncs manually.
Basic
This schedule type lets you run the data syncs at a set interval. You can specify the sync frequency as well as the time(in UTC) when you want the sync to start.
Frequency: You can choose the data sync frequency from the following options:
15 minutes
30 minutes
1 hour
3 hours
6 hours
12 hours
24 hours
Sync Starting At: Specify the time at which the data sync should start.
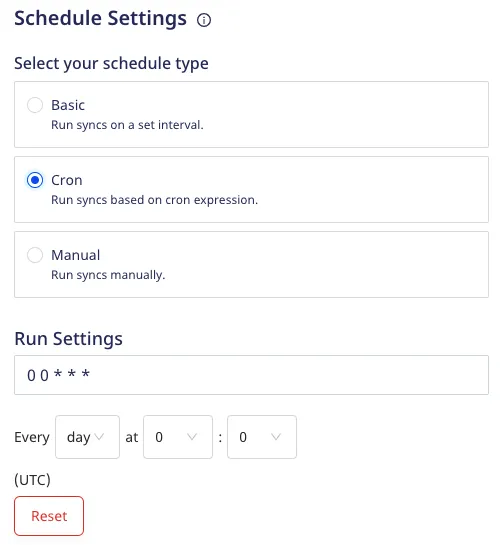
CRON
This schedule type lets you define a custom CRON expression and runs the data syncs based on this setting.
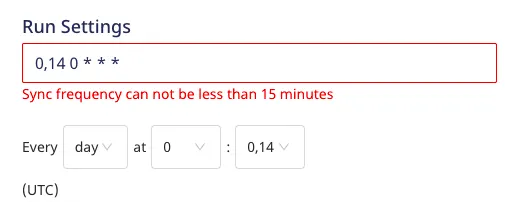
The sync frequency specified under Run Settings needs to be greater than or equal to 15 minutes. Otherwise, you will encounter an error as shown below:
Manual
This schedule type lets you run your data syncs manually. RudderStack won’t sync the data until you explicitly trigger it.
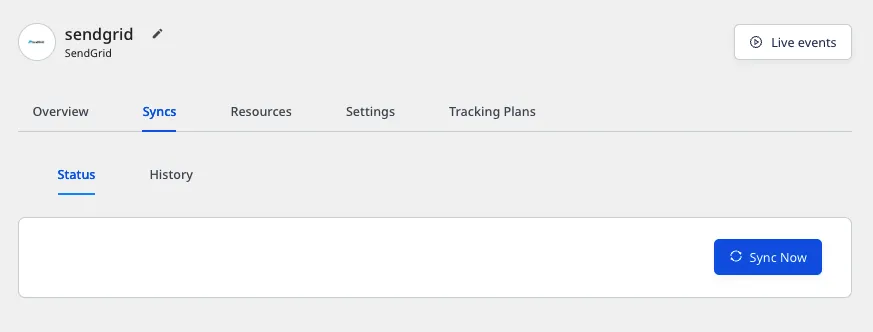
To trigger a sync manually, go to the Syncs tab in your Cloud Extract source details page and click Sync Now:
Sync modes
A sync mode determines how RudderStack reads the data from a source and writes to a warehouse destination. RudderStack supports the following sync modes:
Full Refresh
In this mode, RudderStack retrieves all the available information from the source, regardless of whether it has been synced previously.
In this mode, RudderStack replaces all existing data with the new data.
Incremental
In this mode, RudderStack syncs or replicates only the new or modified data starting from the date specified in the Start date RudderStack dashboard setting. It does not replicate the data that has been already synced before.
During the incremental syncs, RudderStack only updates the the existing rows that have been modified as opposed to adding a new version of the row with the updated data.
Any resource that supports the Incremental sync mode also supports Full Refresh, by default.
If you want to do a Full Refresh sync only for particular Incremental resources, then contact the RudderStack team. This is helpful in cases where your destination’s data gets corrupted or you want to sync your data all over again.
If you want to do a Full Refresh sync for all the resources associated with an Extract source, then change the Start date setting in your existing source configuration. Refer to the FAQ section for more information.
Semi-Incremental
This sync mode is a combination of Full Refresh and Incremental sync modes. RudderStack reads all data from the source and filters it to sync only the new or modified data starting from the date specified in the Start Date RudderStack dashboard setting.
The data synced in the Semi-Incremental mode is exactly the same as in the Incremental mode. The only difference is that in the Semi-Incremental mode, RudderStack internally filters the data to be synced instead of the source API.
FAQ
Can I change my sync schedule type?
Yes, you can.
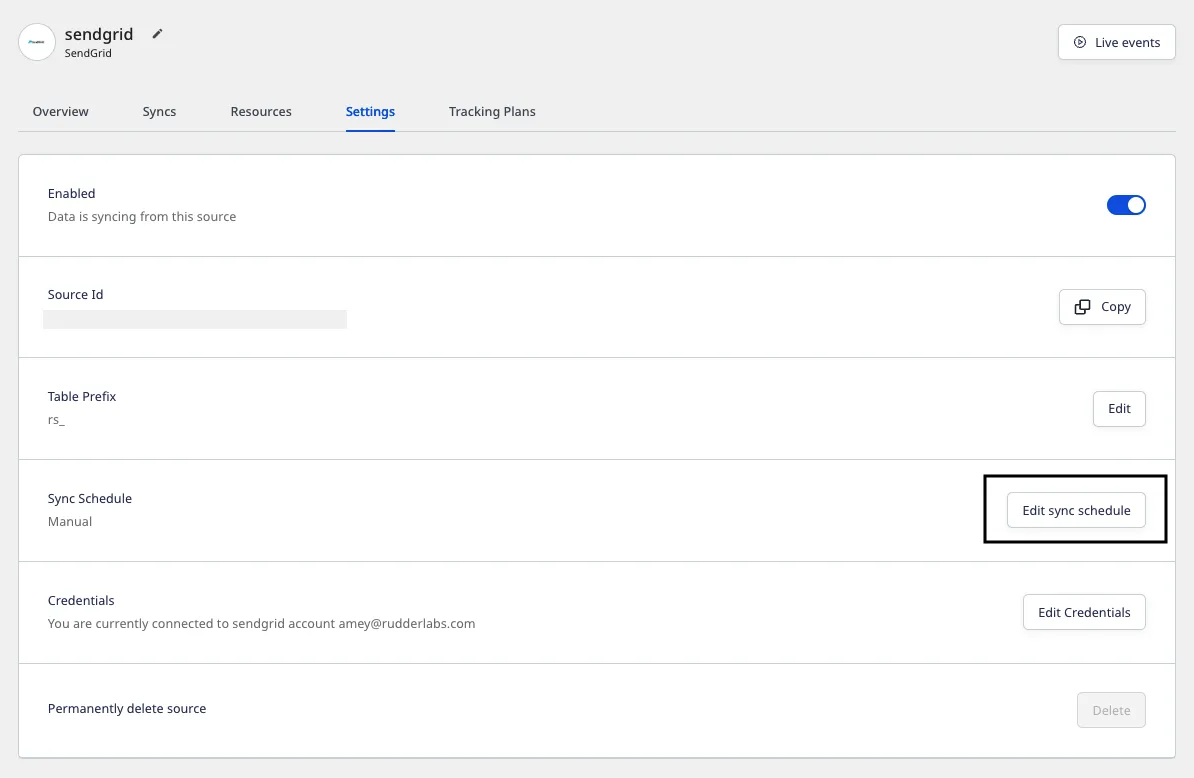
Go to the Settings tab in your Cloud Extract source details page and click Edit sync schedule option:
Then, select your new sync schedule type.
What happens if I don’t set the Sync Starting At time?
RudderStack considers strict time windows to schedule syncs if you do not explicitly set the time under Sync Starting At.
Suppose you create a source at 12:30 hrs UTC, specify the Frequency as 3 hours, and do not specify any time under Sync Starting At. In this case, as the time falls in the 12:00-13:00 time window, RudderStack will run the next sync at 15:00 hrs UTC (12:00 + 03:00 = 15:00 hrs).
How do I force a Full Refresh sync for all the resources?
To force a Full Refresh sync for all the resources supported by the Extract source, change the Start date setting in your existing source configuration.
Disconnecting and reconnecting an Extract source to a warehouse destination does not force a full sync.
Questions? We're here to help.
Join the RudderStack Slack community or email us for support
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.