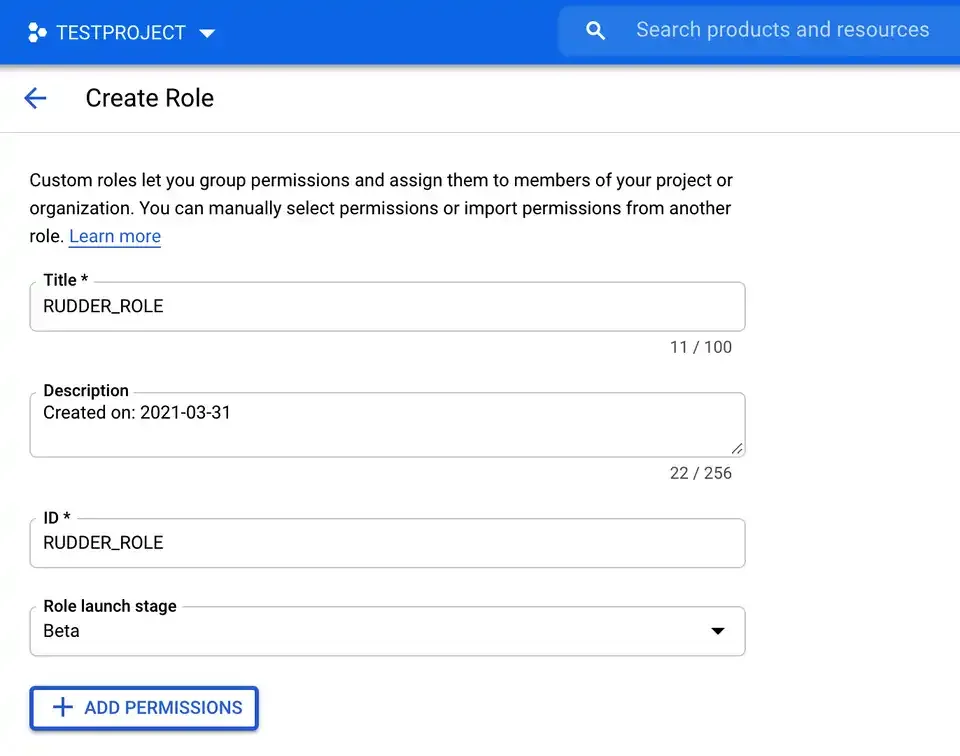
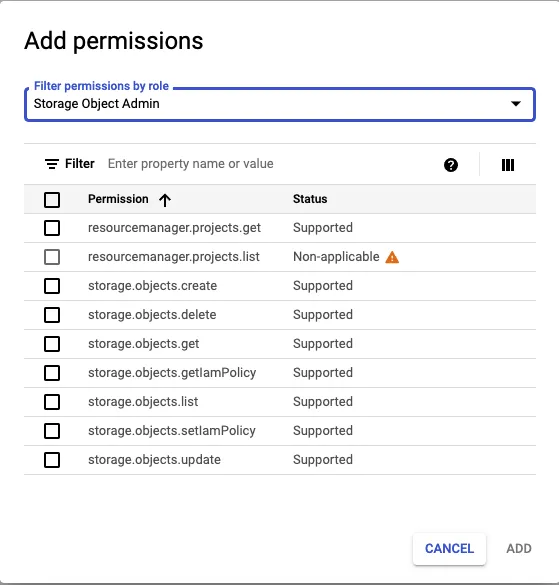
To set up GCS data lake as a destination in RudderStack, you will need to create a new user role and grant the required permissions to create schemas and temporary tables.
Then, select the project containing the dataset that you want to use.
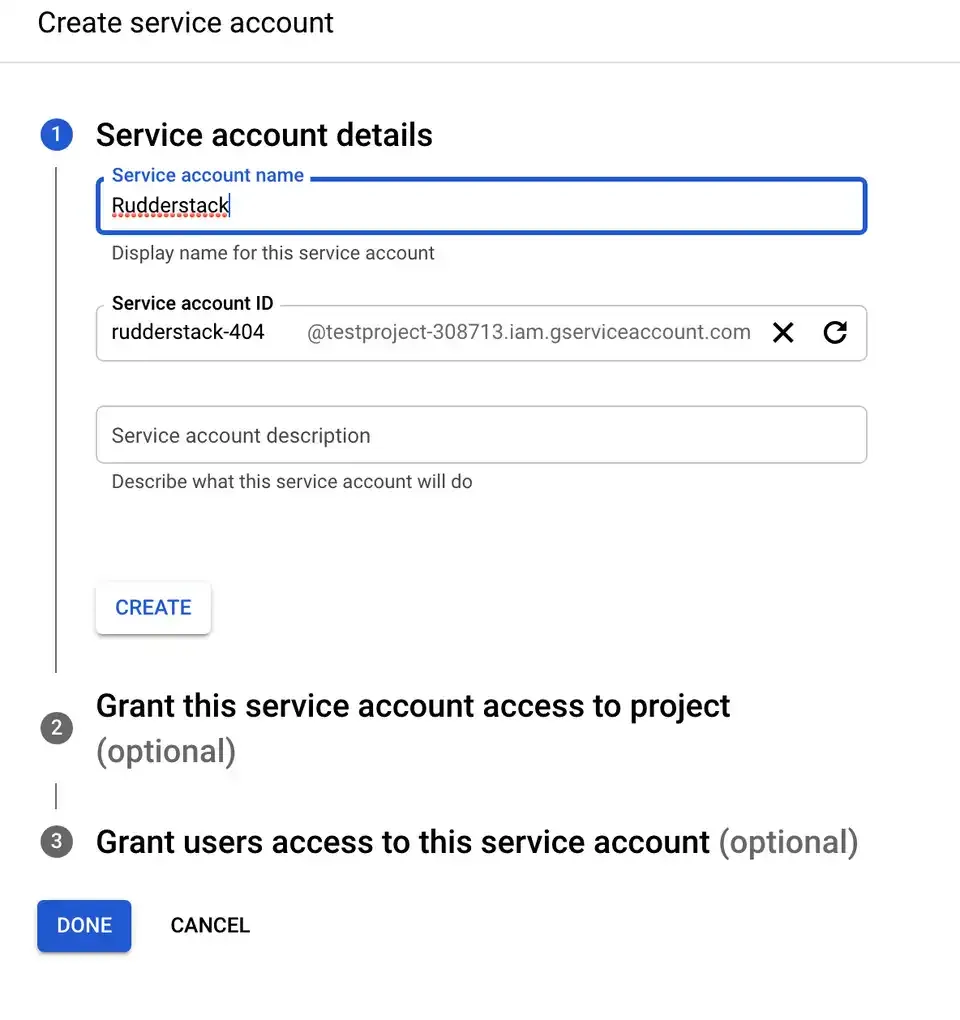
Next, click CREATE SERVICE ACCOUNT.
Fill in the details as shown below and click CREATE.
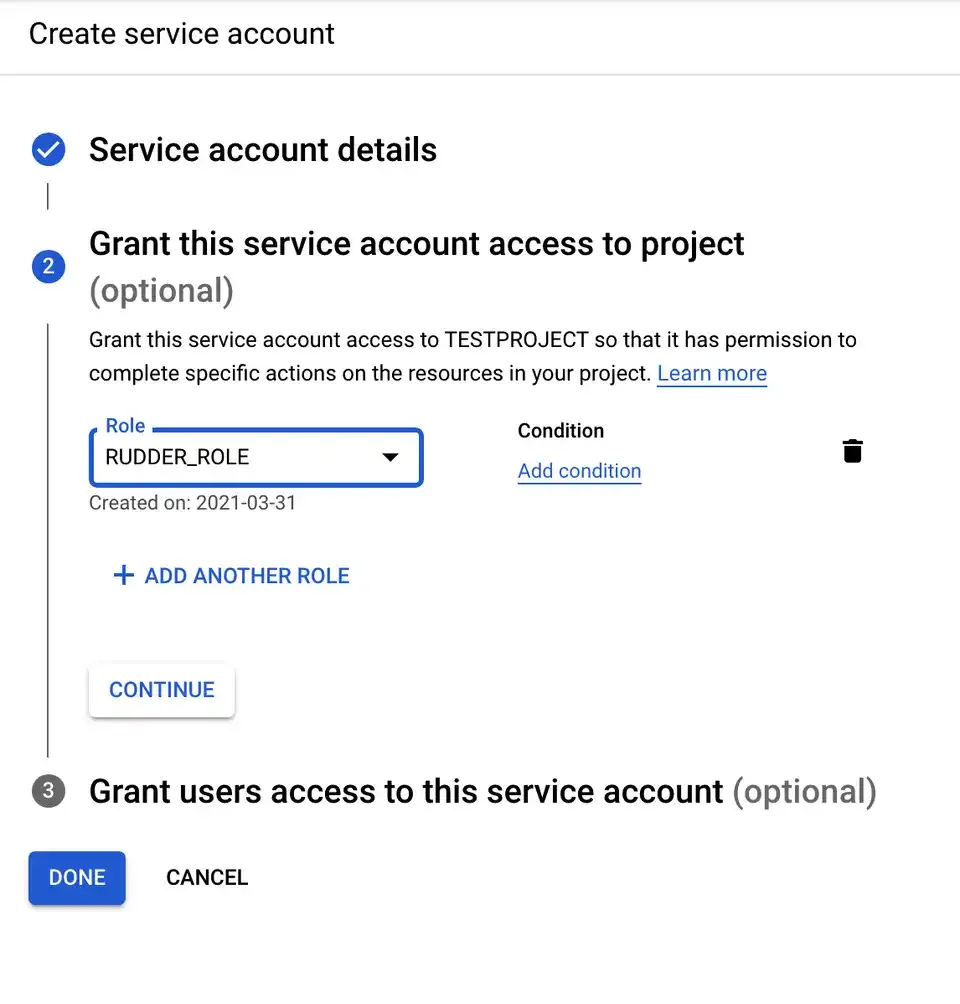
Then, select the previously created role and click CONTINUE.
Finally, click DONE.
Creating and downloading the JSON key
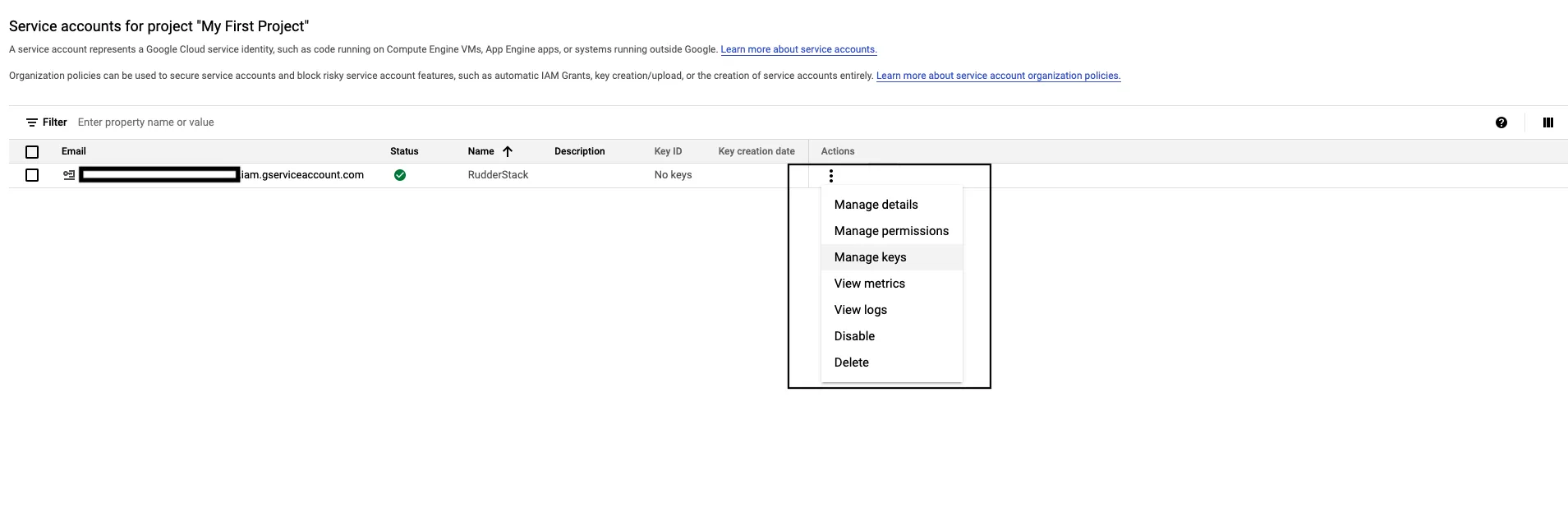
Click the three dots under Actions in the service account that you just created and select Manage keys:
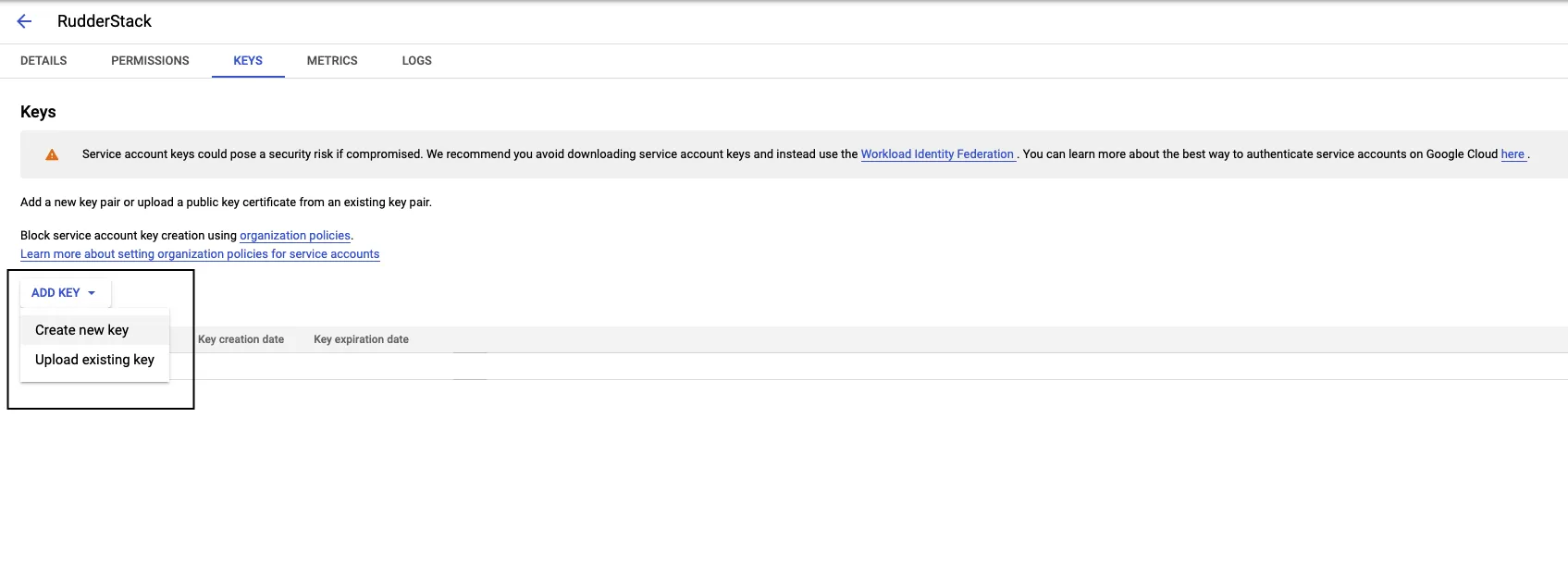
Click ADD KEY, followed by Create new key:
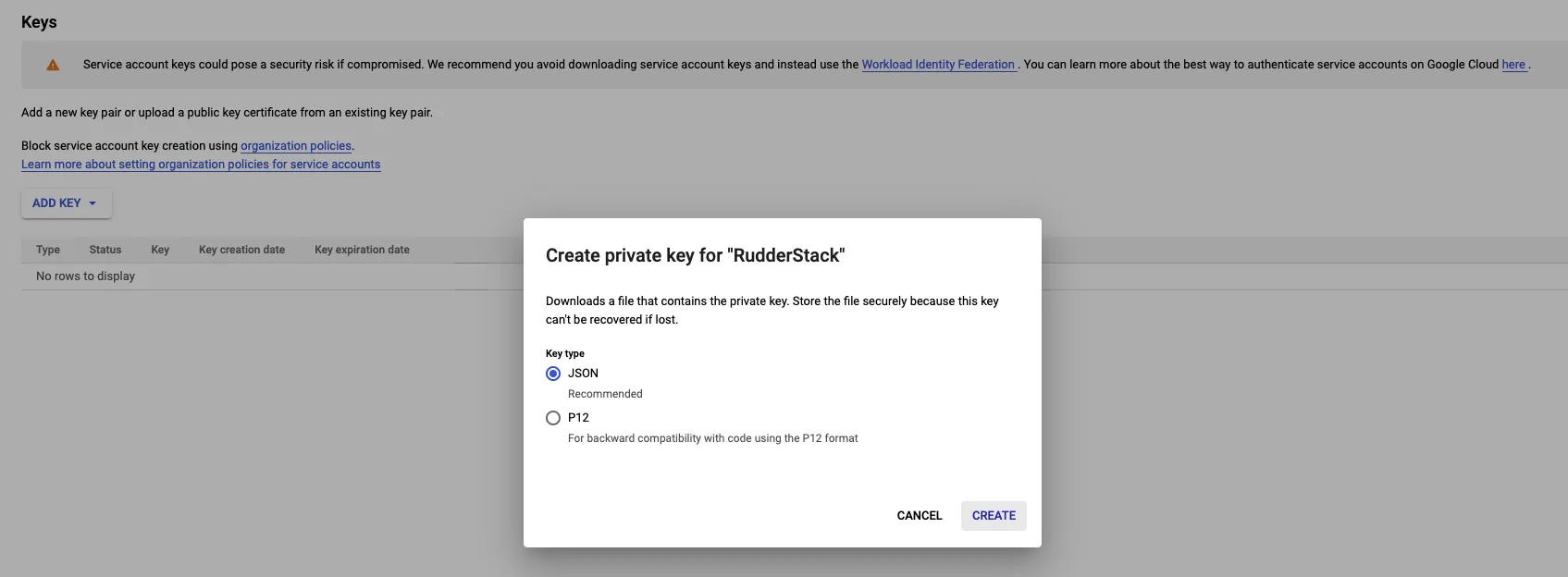
In the resulting pop-up, select JSON and click CREATE.
Finally, download this JSON file. This file is required while setting up the GCS data lake destination in RudderStack.
Configuring GCS data lake destination in RudderStack
To send event data to GCS data lake, you first need to add it as a destination in RudderStack and connect it to your data source. Once the destination is enabled, events will automatically start flowing to GCS data lake via RudderStack.
To configure GCS data lake as a destination in RudderStack, follow these steps:
In your RudderStack dashboard, set up the data source. Then, select Google Cloud Storage Data Lake from the list of destinations.
Assign a name to your destination and then click Next.
Connection settings
GCS Storage Bucket Name: The name of the GCS bucket used to store data before loading it into the GCS data lake.
Prefix: If specified, RudderStack will create a folder in the bucket with this prefix and push all data within that folder. For example, https://storage.googleapis.com/<bucketName>/<prefix>/.
Namespace: If specified, all data for the destination will be pushed to https://storage.googleapis.com/<bucketName>/<prefix>/rudder-datalake/<namespace>. If you don’t specify a namespace in the settings, RudderStack sets it to the source name, by default.
You cannot change the namespace later.
Table Suffix: This optional setting lets you define a custom path under which your table data is stored. For example, if you set this field to rs, your data will be pushed to https://storage.googleapis.com/<bucketName>/<prefix>/rudder-datalake/<namespace>/<table-name>/rs.
Clean up object storage files after successful sync: Turn on this toggle to delete the object storage files after the sync has completed successfully.
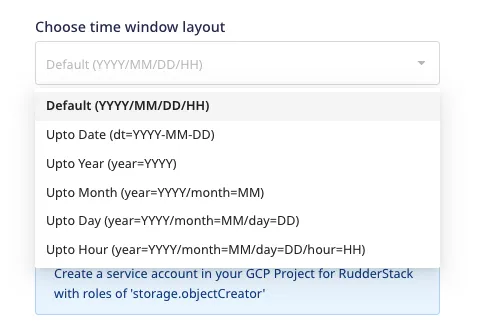
Choose time window layout: This option lets you set the timestamp-defined layout structure under which the table data will be stored.
For example, if you choose the option Upto Hour (year=YYYY/month=MM/day=DD/hour=HH) and an event called Product Clicked is received at 2022-08-06T17:30:00.000T, then the data will be stored in the following location:
The default value for this setting is YYYY/MM/DD/HH.
Credentials: Enter the content of the downloaded credentials JSON file in this field.
Sync Frequency: Specify how often RudderStack should sync the data to your GCS data lake.
Sync Starting At: This optional setting lets you specify the particular time of the day (in UTC) when you want RudderStack to sync the data to the data lake.
Advanced settings
Skip User Table: This setting is toggled on by default and sends events exclusively to the identifies table while skipping the users table. This eliminates the need for a merge operation on the users table. If toggled off, RudderStack sends the events to both the identifies and users tables.
Skip Tracks Table: Toggle on this setting to skip sending events to the tracks table.
Finding your data in the GCS data lake
RudderStack converts your events into Parquet files and dumps them into the configured GCS bucket. Before dumping the events, RudderStack groups the files by the event name based on the time (in UTC) they were received.
The folder structure is similar to the following format:
To enable network access to RudderStack, allowlist the following RudderStack IPs depending on your region and RudderStack plan:
Plan
Region
US
EU
IN
Free and Growth
3.216.35.97
18.214.35.254
23.20.96.9
34.198.90.241
34.211.241.254
52.38.160.231
54.147.40.62
3.123.104.182
3.125.132.33
18.198.90.215
18.196.167.201
Not applicable
Enterprise
3.216.35.97
34.198.90.241
44.236.60.231
54.147.40.62
100.20.239.77
3.66.99.198
3.64.201.167
3.123.104.182
3.125.132.33
3.7.235.227
13.200.113.188
35.154.198.69
3.6.122.214
All the outbound traffic is routed through these RudderStack IPs.
FAQ
What are the files written in the location <namespace>/rudder-warehouse-staging-logs/?
RudderStack collects all unprocessed data flowing to the warehouse destinations as staging files. It stores these files in the object storage at the location https://storage.googleapis.com/rudder-warehouse-staging-logs/.
Once the staging files are processed, RudderStack separates them by the event name and sends them to the specified destination in the following format:
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.