Send your event data from RudderStack to Confluent Cloud.
2 minute read
Confluent Cloud is a cloud-native, fully-managed event streaming platform. Powered by Apache Kafka, it is simple, secure, and simplifies data ingestion and processing on all major clouds. With Confluent Cloud, you can easily handle large-scale data workloads without compromising on performance.
RudderStack allows you to seamlessly configure Confluent Cloud as a destination to send your event data.
Find the open source transformer code for this destination in the GitHub repository.
Once you have confirmed that the platform supports sending events to Confluent Cloud, perform the steps mentioned below:
Choose a source to which you would like to add Confluent Cloud as a destination.
Select the destination as Confluent Cloud. Give your destination a name, and then click Next.
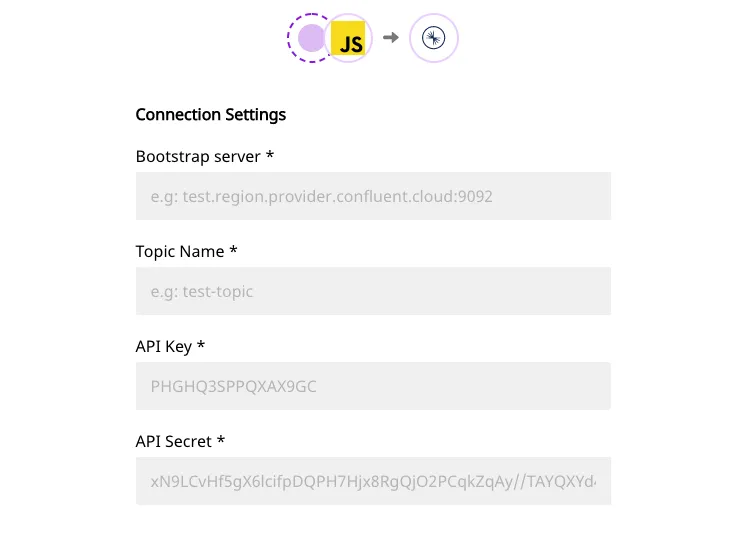
In the Connection Settings, fill the required fields with the relevant information and click Next.
Confluent Cloud connection settings
The required fields are as follows:
Bootstrap server: Enter your bootstrap server information here. This is in the format hostname::port . You will get this information in your cluster settings.
Topic Name: Enter the name of the Kafka topic in this field.
API Key: This is the key you need to generate in the Confluent Cloud UI to give RudderStack the required API access. Enter the key in this field.
API Secret: Enter the API Secret in this field - you can generate this in the Confluent Cloud UI.
Partition Key
RudderStack uses userId as the partition key of a given message.
If userId is not present in the payload, then anonymousId is used.
If you have a multi-partitioned topic, then the records of the same userId (or anonymousId in the absence of userId) will always go to the same partition.
Questions? We're here to help.
Join the RudderStack Slack community or email us for support
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.