Connect Reverse ETL Source to Custom Audience
Private Beta
Configure a Reverse ETL source with your Custom Audience destination.
7 minute read
The Audiences feature is in Private Beta, where we work with early users and customers to test new features and get feedback before making them generally available.
Reach out to Customer Success if you are interested in enabling this feature for your workspace.
This guide takes you through the steps to connect a Reverse ETL source to your Custom Audience destination and configure field mappings.
You can connect multiple Reverse ETL sources to the Custom Audience destination.
Setup
Set up and configure your Reverse ETL source.
In the Overview tab of the source page, click Add destination > Create new destination. You can also select an already-configured destination here.
From the list of destinations, select Custom Audience and click Continue.
Configure the following settings to specify how RudderStack connects to your API:
Setting
Description
Name
A unique name that identifies this destination in your workspace.
Audience delivery API configuration
Setting
Description
Enter base URL
Specify the root URL for your API (for example, https://api.example.com). All requests are sent to this URL.
Specify authentication
Choose how RudderStack authenticates with your API.
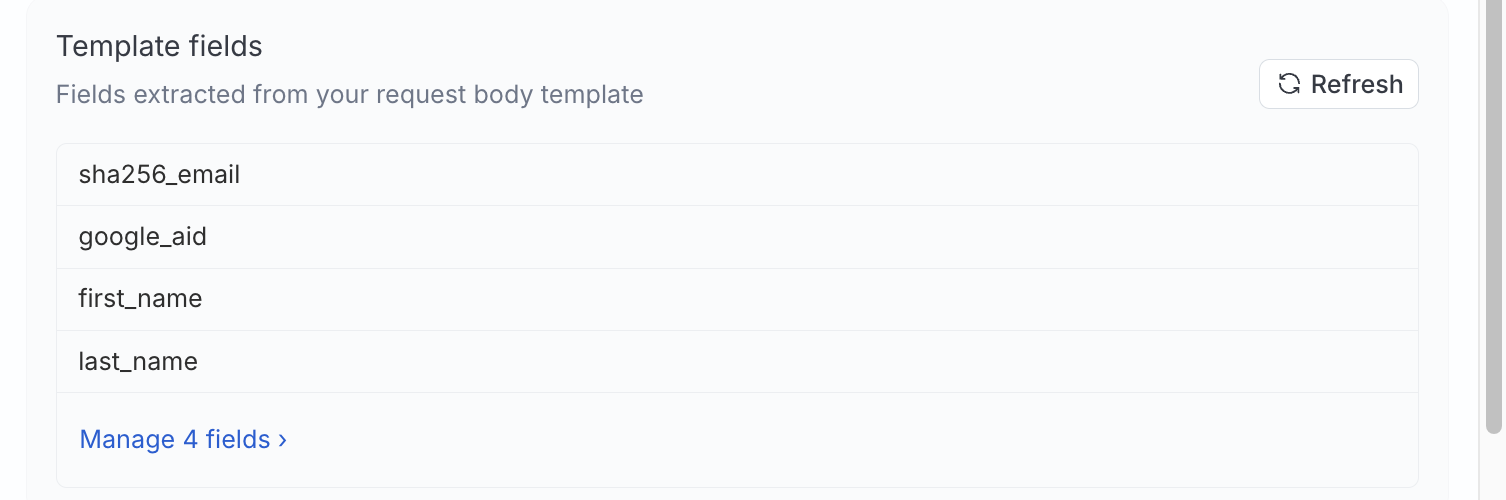
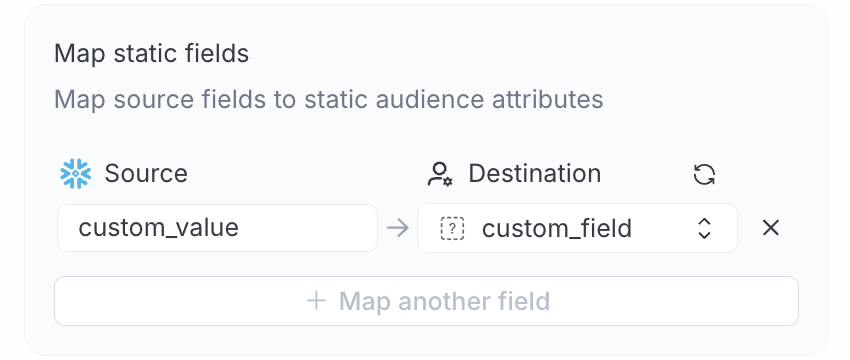
After you define a template, RudderStack extracts field names referenced under $$.records and lists them under Template fields. Click Refresh to re-scan the template, or Manage fields to configure each field.
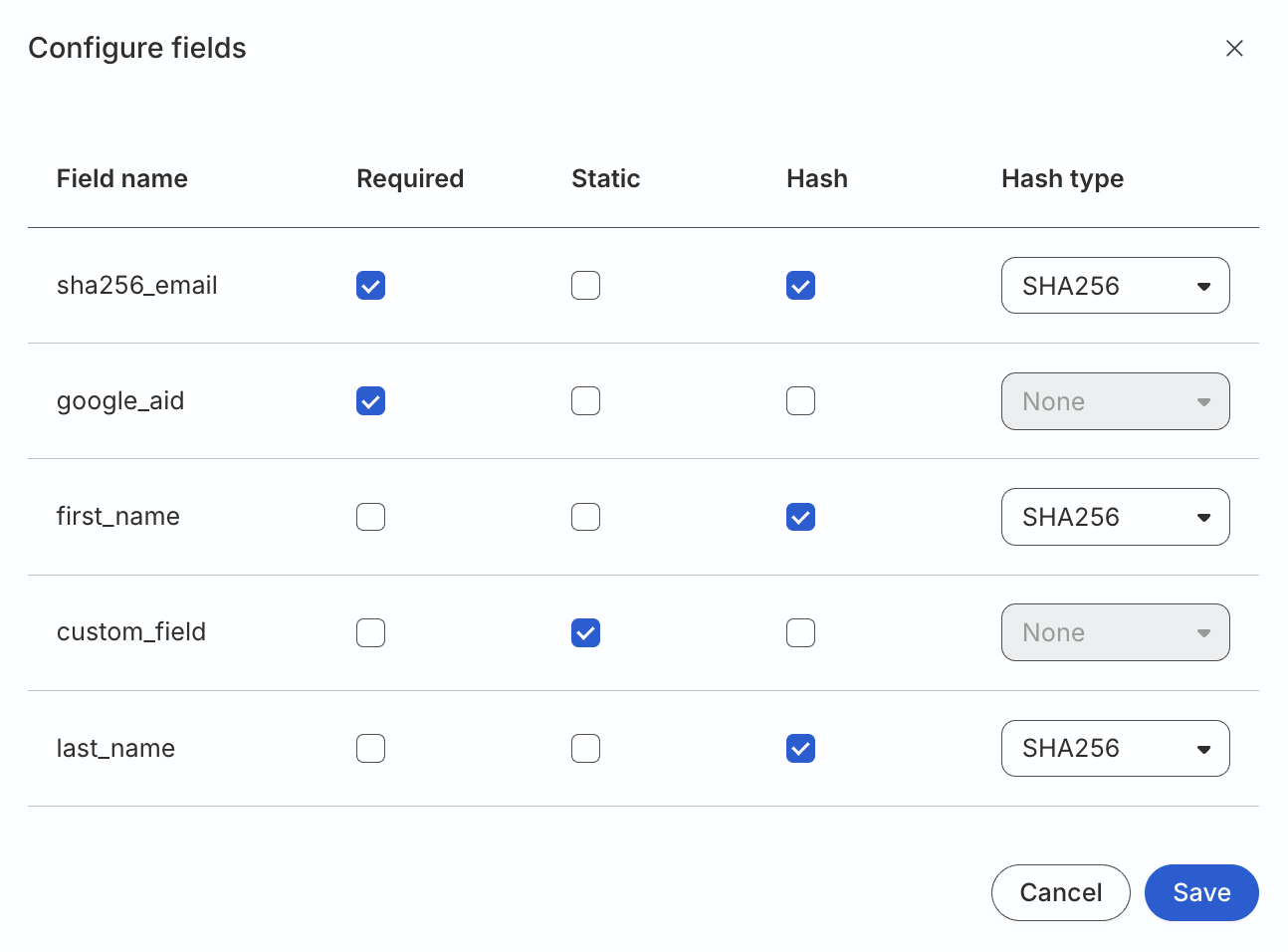
Field setting
Description
Name
Destination-side field name used in the template
Required
If enabled, you must map the field to a warehouse column in the Map identifiers section
Static
If enabled, the value is a literal you provide in the Map identifiers section
Hash
Hash algorithm applied before the template runs. You can choose between None, SHA256, SHA512, or MD5.
If you rename or remove template fields after syncs exist, make sure to update mappings on each affected sync manually.
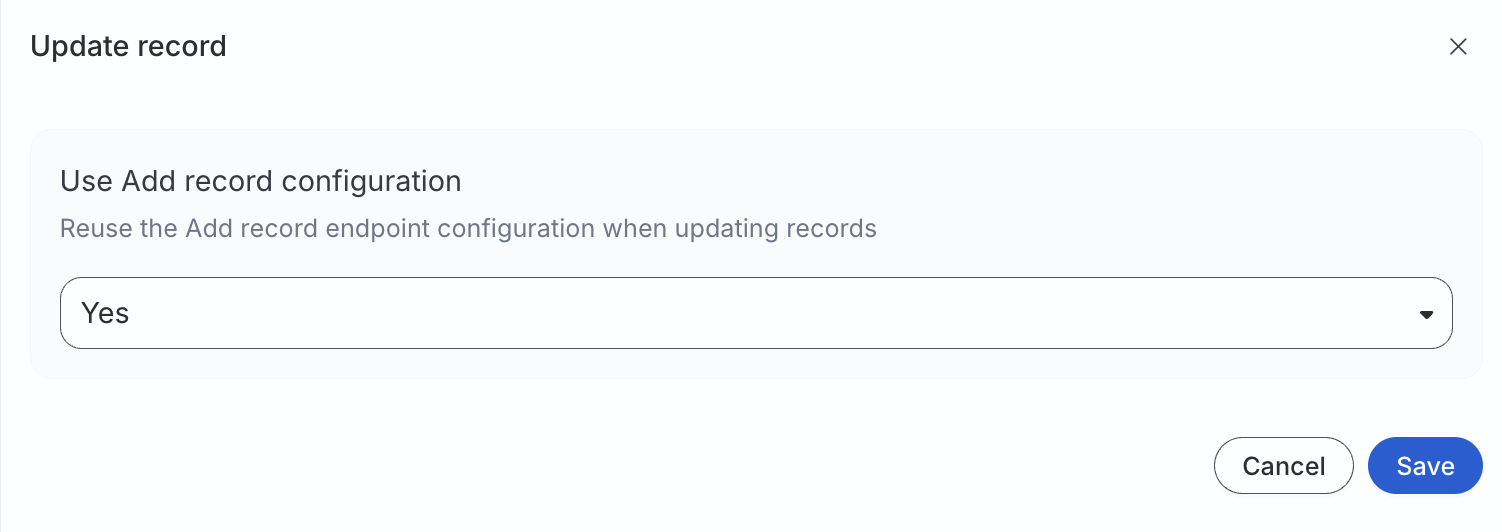
Configure the setting to Yes if your incoming data is not pre-hashed
Configure this setting to No if your data is already hashed
Incorrect configuration of the Automatically hash PII data setting will result in failures.
If the Automatically hash PII data setting is configured to Yes and your data is pre-hashed, the event will fail.
If the Automatically hash PII data setting is configured to No and your data is not pre-hashed, the event will fail.
Such events are rejected with a clear error message, for example:
Hashing is disabled but the value for field EMAIL appears to be unhashed. Either enable hashing or send pre-hashed data.
You will also see errors in the Events tab for cases that were previously marked as successful but resulted in no matches, helping you identify and fix data quality or configuration issues.
Troubleshooting
Issue
Resolution
Template is rejected on save
The syntax is outside the allowlisted operations — the error message names the action and position
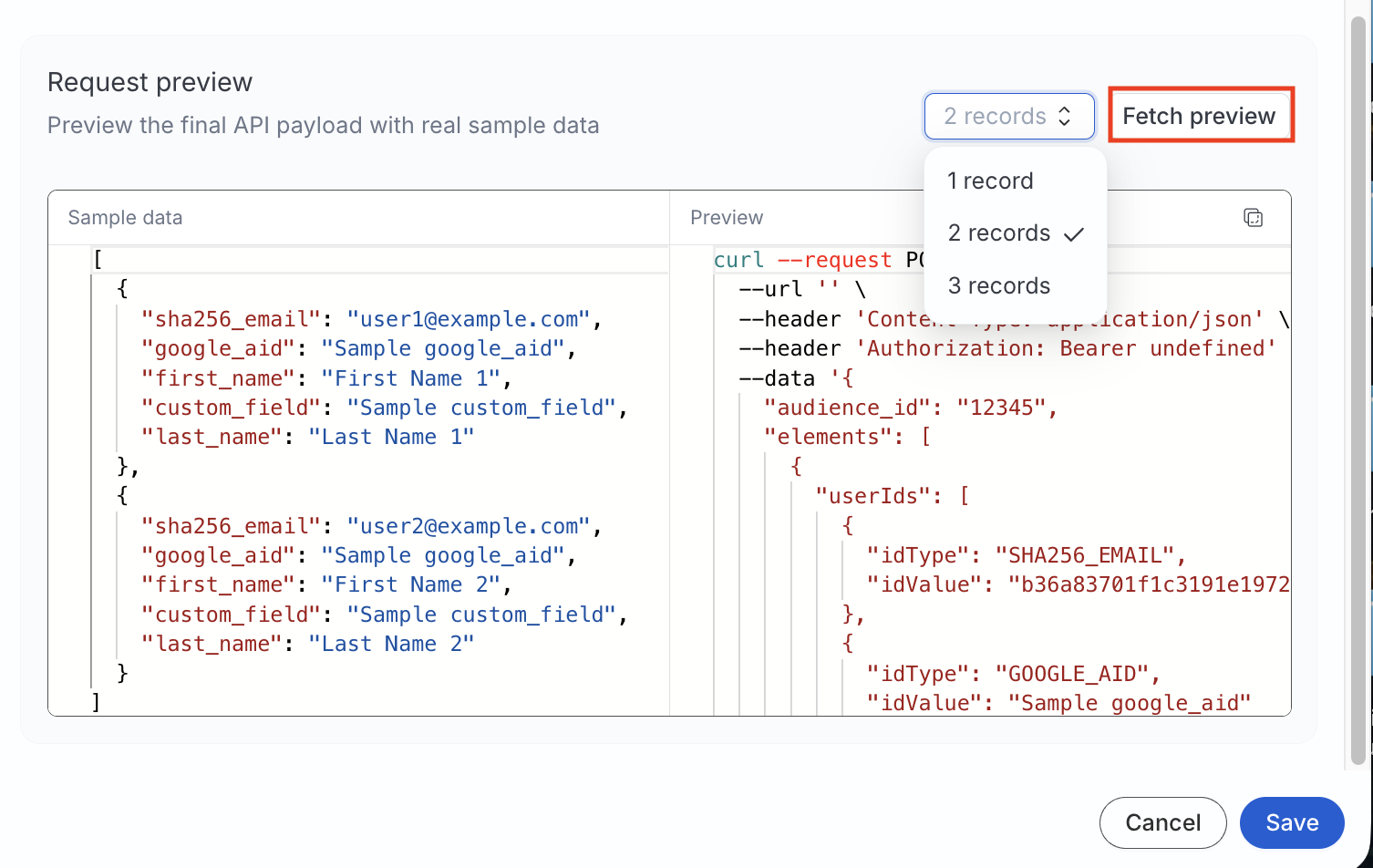
Unexpected payload shape
Use the Fetch preview with the same sample records and action type (INSERT, UPDATE, or DELETE) to verify the payload shape
400 errors for all records
Required fields are unmapped or the warehouse values are empty
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.