Commonly-asked questions related to RudderStack data warehouse destinations.
17 minute read
IP allowlist
Which RudderStack IPs should I allowlist?
To enable network access to RudderStack, allowlist the following RudderStack IPs depending on your region and RudderStack Cloud plan:
Plan
Region
US
EU
Free, Starter, and Growth
3.216.35.97
18.214.35.254
23.20.96.9
34.198.90.241
34.211.241.254
52.38.160.231
54.147.40.62
3.123.104.182
3.125.132.33
18.198.90.215
18.196.167.201
Enterprise
3.216.35.97
34.198.90.241
44.236.60.231
54.147.40.62
100.20.239.77
3.66.99.198
3.64.201.167
3.123.104.182
3.125.132.33
All the outbound traffic is routed through these RudderStack IPs.
Data syncs and retries
When does RudderStack load data into the warehouse destination?
RudderStack lets you choose how frequently it should sync the data into the data warehouse. The default time is 30 minutes. However, you can choose to extend this value up to 24 hours. You can also configure the time of the day when RudderStack loads the data.
Is there a way to force load my data into the warehouse?
Yes, there is - you can configure the below values in your config.yaml file:
warehouseSyncFreqIgnore = true#if set true this will ignore syncFrequency and syncStartingAt values which are configured in UI. By default this is falseuploadFreqInS=1800#This field lets you control syncPeriod if above field set to true
Where can I view the status of my data sync?
You can view the warehouse upload status in the Live Events section of the destination in the RudderStack dashboard.
How do I set frequency of syncs for a warehouse destination?
Specify how often RudderStack should sync data to your warehouse destination.
To set a particular time of the day (in UTC) when RudderStack syncs data to the warehouse, you can specify the Sync Starting At option.
What happens if the cluster or the destination service is down? Is there a possibility of data loss?
If a warehouse destination is down or unavailable, RudderStack will continue to retry sending the events (on an exponential backoff basis, for up to 3 hours).
RudderStack stores the syncs as staging files and retries sending them at a later time when the cluster is up again. This allows for a successful delivery without any missing data.
Does RudderStack keep retrying sending events indefinitely? How long can a service be down without losing any data?
After retrying for up to 3 hours, RudderStack marks the syncs as aborted. Once the service is up and running again, you can go to the Syncs tab in the RudderStack dashboard and retry sending the data.
Is there a scenario where I can lose my data without the ability to retry syncs?
RudderStack stores the data in the form of staging files in the object storage associated with the warehouse destination. Usually, the data is stored in the bucket for 30 days. However, it completely depends on the retention policy you have set for the bucket.
RudderStack also provides the event replay feature for the enterprise customers wherein you can back up your event data and replay it in case of any failures.
Can I tie a value in the rudder_discards table back to the actual event in another table?
Yes, you can.
The rudder_discards table contains columns like row_id (corresponding to the event’s messageId), table_name, column_name, and column_value.
You can use the table_name and map the row_id to the id column in your event’s table.
The rudder_discards table is applicable for all warehouse destinations except the following data lake destinations:
Will the data syncs run in parallel if I connect two or more sources to a single warehouse destination (having the same namespace/schema name)?
No, the data syncs run sequentially. This is because some destinations like Amazon Redshift and Databricks do not support writing to the same table concurrently, resulting in aborted syncs.
Staging and object storage
How does RudderStack store data in an object storage platform?
RudderStack stores the data in an object storage platform as follows:
Collects all the events in a single node and writes them into a staging file that is created every 30 seconds.
Collects all the staging files and creates table-specific files every 30 minutes (or user-defined frequency). These files are called the load files and RudderStack copies them directly into the warehouse.
What is the file storage format for staging and load files in different object storage platforms?
The load files store data in the following file format:
Warehouse destination
File format
Amazon S3 data lake Google Cloud Storage data lake Azure data lake Databricks Delta Lake
Parquet (parquet)
Microsoft SQL Server Azure Synapse Snowflake Amazon Redshift PostgreSQL ClickHouse
Compressed CSV gzip (csv.gz)
Google BigQuery
Compressed JSON gzip (json.gz)
What are the files written in the location <namespace>/rudder-warehouse-staging-logs/?
RudderStack collects all unprocessed data flowing to the warehouse destinations as staging files. It stores these files in the object storage at the location <namespace>/rudder-warehouse-staging-logs/.
Once the staging files are processed, RudderStack separates them by the event name and sends them to the specified destination.
How can I delete the staging files in my buckets?
RudderStack loads all events configured with your warehouse into staging buckets. You can set a retention policy to delete these files from the staging bucket after a certain time. If you do not set any retention policy, the files will keep on accumulating.
Make sure that the retention policy duration is longer than the warehouse sync frequency duration so that RudderStack can re-run event uploads for a longer time, if required. It is recommended to set the retention policy duration to 30 days/1 month.
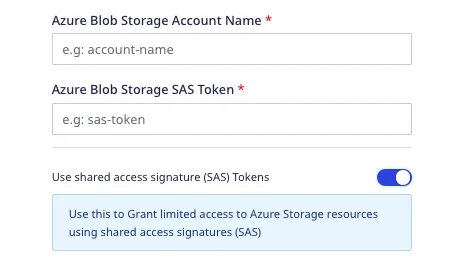
Can I grant RudderStack limited access to the Azure Storage resources?
Yes, you can enable the Use shared access signature (SAS) Tokens setting while configuring your Blob Storage in the dashboard settings:
For more information on the shared access signatures (SAS) and setting the required permissions, refer to the SAS token permissions section.
Optimizing syncs
How do I avoid lags in data syncs while heavy loads are running on my data warehouse?
You can use either of the following approaches to avoid data sync lags in your warehouse:
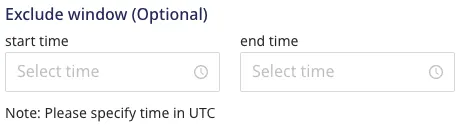
Approach 1: In the warehouse destination connection settings, set an exclusion window which lets you set a start and end time when RudderStack will not sync data to your warehouse. You can run heavy loads during this time interval.
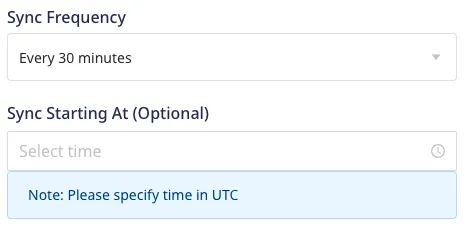
Approach 2: In the warehouse destination connection settings, your can increase the sync frequency interval so that there are lesser number of warehouse syncs throughout the day. You can also run the data syncs during the non-peak hours by setting the Sync Starting At time interval.
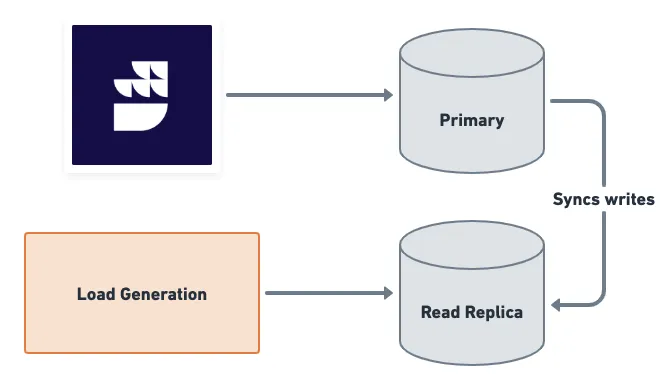
Approach 3: If you are performing only writes/updates on your data warehouse, you can set up a read replica of your database and connect it to your load generation tool. Connect the read/write replica to RudderStack:
How can I speed up my warehouse uploads?
You can speed up your warehouse uploads by configuring the following parameters in the config.yaml file in your RudderStack setup:
Parameter
Description
Tip
Default value
RSERVER_WAREHOUSE_REDSHIFT_MAX_PARALLEL_LOADS
Defines the number of concurrent tables that are synced to redshift in a given upload.
Increase this as per your infra capability.
3
RSERVER_WAREHOUSE_STAGING_FILES_BATCH_SIZE
Defines the number of staging files that are batched and synced in a single upload.
Increase this to batch more files together and reduce the number of uploads needed for a given volume of data.
960
RSERVER_WAREHOUSE_NO_OF_WORKERS
Number of concurrent uploads to a warehouse. For example, 8 uploads to different schemas in Redshift can be done simultaneously.
-
8
RSERVER_WAREHOUSE_NO_OF_SLAVE_WORKER_ROUTINES
Number of go-routines creating load files in a warehouse slave process.
Increase or decrease this as per memory allocated to the warehouse slave pod.
4
What happens if I exceed the table column limit in my warehouse destination?
If you exceed the permissible table column limit in your warehouse, RudderStack will not sync data to it.
How can I handle the column count threshold in my warehouse?
To avoid exceeding the column count threshold in your warehouse, you can use any one of the following approaches:
Go to your warehouse and drop the unwanted table columns. Refer to the following links for managing your warehouse column count:
For other warehouses, refer to their respective documentation.
If you’re syncing semi-structured event data that is not defined by a fixed schema, you can leverage RudderStack’s JSON Column Support feature to send the data to your warehouse without worrying about the column count limit.
Namespace, prefix, and warehouse schema
Can I modify the warehouse schema once it is created? Will RudderStack overwrite or discard the changes when updating the schema?
You can modify the warehouse schema once it is created by adding or altering the columns, or changing the column data type. RudderStack honors the updated warehouse schema and sends the incoming data to the warehouse accordingly.
For example, if you update a column’s data type in the schema, RudderStack will consider the latest, updated column data type and typecast all the incoming data accordingly, before sending it to that column.
How is the Namespace field populated for a warehouse destination?
RudderStack sets the Namespace field depending on the following conditions:
If the Namespace and Database fields are present in your warehouse configuration:
For ClickHouse destination, the Database field is set as the namespace.
For all the other destinations, the Namespace field is populated as it is.
If RSERVER_WAREHOUSE_(DEST_TYPE)_CUSTOM_DATA_SET_PREFIX parameter is present, the namespace is populated as (CUSTOM_DATA_SET_PREFIX)_(SOURCE_NAME). For example:
If none of the above fields are specified in the warehouse configuration settings, the source name is populated as the namespace for the first sync and picked up from the cache for all the subsequent syncs. In case the source name is changed, the namespace still remains the same as it is picked from cache.
To update the namespace as the new source name, you need to configure a new source.
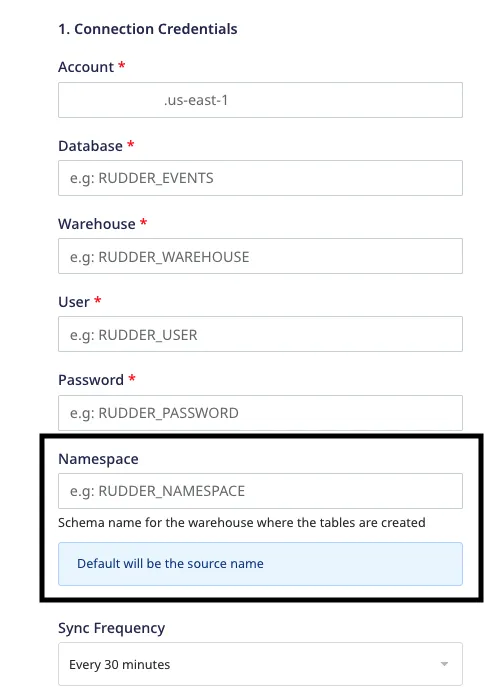
Can I change the namespace (schema name) of my data warehouse in RudderStack?
Yes, you can. RudderStack lets you change the namespace (schema name) where it loads all the data in your warehouse.
You can specify your desired schema name in the Namespace field while configuring your warehouse destination in RudderStack, as shown:
Refer to the warehouse-specific documentation for more information on configuring a namespace while setting up the destination in RudderStack.
If you do not set the Namespace field, RudderStack sets the source name as the schema name, with some modifications.
How can I add the table prefixes if there are multiple sources connected to a single destination?
You can use RudderStack’s Transformations feature to filter the events by the sourceID and then update the event name to add a prefix.
How does RudderStack configure the schema name before loading the data in the warehouse?
RudderStack configures the schema name based on the values mentioned in the below table. The table columns are defined as follows:
Sync: Indicates whether RudderStack performs the first data sync after the source is set up or the subsequent syncs.
Namespace: The Namespace field set by the user while configuring the warehouse destination in the RudderStack dashboard.
Warehouse.<destType>.customDataset Prefix: The RSERVER_WAREHOUSE_(DEST_TYPE)_CUSTOM_DATA_SET_PREFIX parameter in the config.yaml file, in case the user has a RudderStack deployment locally/in their own environment.
Source name: Name of the source connected to the warehouse destination.
Sync
Namespace
customDataset Prefix
Source name
Schema name
Notes
First sync
AB
XY
S
AB
The namespace is given priority over all the other values.
First sync
Not set
XY
S
XY_S
RudderStack combines the customDataset prefix and the source name to set the schema name, if the namespace is absent.
First sync
Not set
Not set
S
S
RudderStack sets the source name as the schema name if the namespace and customDataset prefix are absent.
First sync
AB
Not set
S
AB
The namespace is given priority over the other values.
Second sync onwards
ABC
XYZ
SS
ABC
The namespace, source name and the customDataset prefix have all been modified. The new namespace is given priority and set as the schema name.
All the data from the second sync will now be stored in the new schema (ABC) and the original schema (AB) will be left as is.
Second sync onwards
Not set
XYZ
S
XYZ_S
The customDataset prefix name has been modified.
RudderStack combines the customDataset prefix and the source name to set the schema name.
Second sync onwards
Not set
XYZ
SS
XYZ_SS
The source name and customDataset prefix have been modified.
RudderStack combines them together to set the schema name.
Second sync onwards
ABC
Not set
SS
ABC
The namespace and source names have been modified.
The namespace is given priority and set as the schema name.
Second sync onwards
Not set
Not set
SS
S
The source name has been modified. However, it does not impact the schema name and it remains the same as in the first sync.
Key takeaways:
The namespace set in the RudderStack dashboard always takes precedence when setting the schema name in the warehouse.
If the RSERVER_WAREHOUSE_(DEST_TYPE)_CUSTOM_DATA_SET_PREFIX parameter is set in the config.yaml file of your RudderStack deployment, RudderStack sets the schema name in the customDataset_sourcename format, as noted in this FAQ.
If the namespace and RSERVER_WAREHOUSE_(DEST_TYPE)_CUSTOM_DATA_SET_PREFIX parameter, both are absent, RudderStack sets the source name as the schema name.
How does RudderStack configure the table names?
RudderStack sets the table names by picking up the event names and modifying them to follow the snake case convention (for example, source name -> source_name).
For the following sample snippet, RudderStack sets the table name as product_purchased.
For PostgreSQL, the table name is truncated after 63 characters.
For Data Lake destinations (S3 Data Lake, GCS Data Lake, Azure Data Lake), there is no set limit.
For other destinations, the table name is truncated after 127 characters.
How does RudderStack handle schema data type mismatch when sending events to a warehouse destination?
RudderStack automatically handles the data type conversion in some common scenarios depending on the warehouse column data type.
Scenario
Incoming data type
Warehouse column data type
Notes
1
All data types except String, Text, or JSON
String or Text
RudderStack automatically stringifies the incoming data.
2
Integer BigInt
Float
-
3
Float
Integer BigInt
-
4
Integer Float Boolean
JSON
RudderStack automatically stringifies the incoming data.
In any scenario other than the ones covered above, that is, when the incoming data cannot be typecasted into the warehouse column-specific data type, it is sent to the rudder_discards table.
Note that this change is applicable to the subsequent events sent to the warehouse destination, after the transformation is applied.
You can also migrate the previously created table data in the warehouse to the new table.
How does RudderStack configure the column names? / How does RudderStack normalize arrays and complex event properties in the warehouse schema?
RudderStack flattens the event properties and converts them into snake case (for example, source name -> source_name). Further, each of these event properties acts as a warehouse column.
The below example shows how the standard properties are normalized:
{product:{name:"iPhone",version:11}}
Normalized properties (Column names)
product_name:"iPhone"product_version:11
The below example shows how the array properties are normalized:
How does RudderStack determine the column data type? Can I change an existing data type for a column?
RudderStack determines the data type of a column based on its value in the first event (during the first upload sync).
For example, suppose column_x is received with the value as 1. RudderStack then sets the data type of this column as int in the event table.
Although you can change the columns’ data type in the warehouse any time, the changes will be applicable to the events from the next sync.
To set your preferred data type for a particular column, it is highly recommended to follow these steps:
Create a column in the warehouse with a placeholder name and the required data type.
Cast the data from the original column and load it into the placeholder column.
Drop the original column.
Rename the placeholder column to the original column name.
During steps 3 and 4, the tables will be in a locked state. This might impact real-time data uploads/syncs.
If the above steps take too long to complete, you can halt the warehouse operations in the interim. For more information, refer to this FAQ.
Why am I not able to see the properties added at the top level of an event in warehouse destination?
RudderStack drops any non-standard properties (properties apart from the standard properties) declared at the top level of an event. However, you can add such properties in the context or properties section of the event payload.
Which integration options are supported for warehouse destinations?
The following integration options are supported for the warehouse destinations:
Integration option
Description
skipTracksTable
Skips sending the event data to tracks table. Reference.
useBlendoCasing
Retains the Blendo column names when migrating from Blendo to RudderStack.
jsonPaths
Declares given path columns as JSON fields in warehouse. Reference.
Warehouse-specific settings
While configuring the Snowflake destination, what should I enter in the Account field?
While configuring Snowflake as a destination in RudderStack, you need to enter your Snowflake connection credentials which includes the Account field, as shown below:
The Account field corresponds to your Snowflake account ID and is a part of the Snowflake URL.
The following examples illustrate the slight differences in the Snowflake account ID for various cloud providers:
In case of AWS, .aws is present in the account locator of some region accounts and hence must be included in the Account field above.
For more information on the different account locator formats depending on your region or cloud provider, refer to the Snowflake documentation.
What are the SAS token permissions required for the warehouse destinations?
If you’re using Azure Blob Storage as an intermediate object storage for your data warehouse destinations, you will need to assign the following permissions for your SAS token:
Warehouse destination
Minimum required permissions
Azure Data Lake
Read, Write
Azure Synapse
Read, Write
Clickhouse
Read, Write
Databricks Delta Lake
Read, Write
Microsoft SQL Server
Read, Write
PostgreSQL
Read, Write
Snowflake
Read, Write
For more information on the shared access signatures (SAS) and setting the required permissions, refer to the SAS token permissions section.
Event deduplication
What is event duplication?
As RudderStack receives events from different sources, sometimes there is a likelyhood of the response (ACK) is missed due to some network issue. In this case, although RudderStack receives and persists an event as a job, the client doesn’t know if that’s the case and it retries sending the event. This leads to event duplication.
How does RudderStack handle deduplication in different warehouses?
For warehouse destinations, RudderStack relies on the event’s messageId for deduplication. For cloud sources, instead of messageId, RudderStack uses a property called recordId for deduplicating events in the warehouse destination.
Once RudderStack has the dedup key(messageId/recordId), it deduplicates events as below:
For Snowflake and Delta Lake
RudderStack loads all the data into a staging table and uses a merge query to push all data from this table.
For PostgreSQL, MySQL, Azure Synapse, and Redshift
RudderStack uses DELETE to remove the duplicated events in the staging table before inserting them into the main table.
RudderStack does not support deduplication in the data lake destinations.
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.