Google BigQuery is an industry-leading, fully-managed cloud data warehouse that lets you efficiently store and analyze petabytes of data.
Find the open source code for this destination in the GitHub repository.
See the Warehouse Schema guide for more information on how the events are mapped to the tables in BigQuery.
Setting up the BigQuery project
Before you set up BigQuery as a destination in RudderStack, follow these steps to set up your BigQuery project:
Create a Google Cloud Platform (GCP) project if you don’t have one already. For more details, refer to this BigQuery documentation.
Make sure to enable billing for the project to allow RudderStack to load data into your BigQuery cluster.
Enable the BigQuery API for your existing project if not done already. See the Google Cloud documentation for more information.
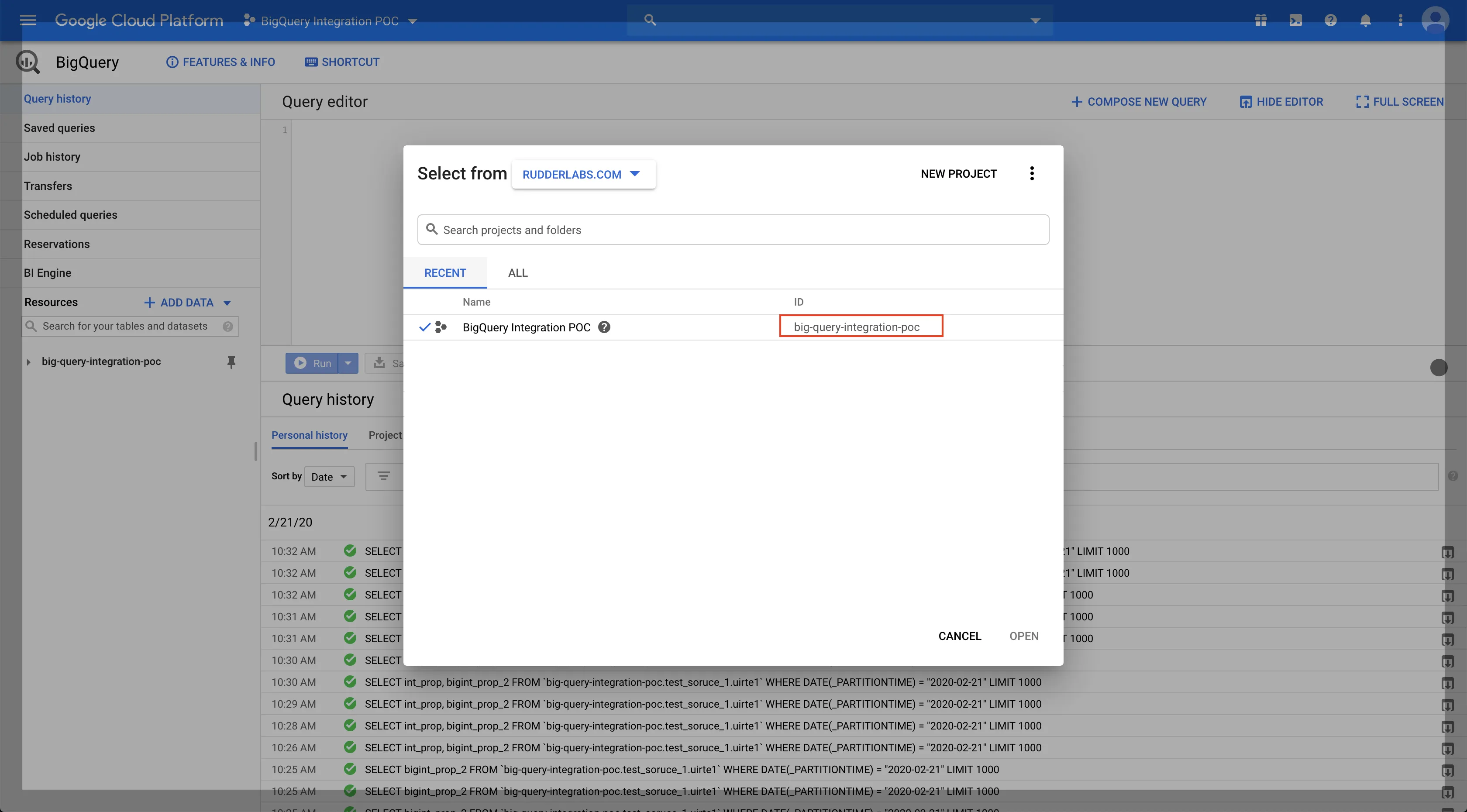
Log into your BigQuery console. Copy the project ID as shown below. This ID is required for configuring BigQuery as a destination in RudderStack.
Create a new Google Cloud Storage (GCS) bucket or provide an existing one to store files before loading the data into your BigQuery instance. Also, ensure that the data loads from GCS to BigQuery by co-locating your GCS storage bucket with BigQuery. For more information, see the Google Cloud documentation.
Setting up the service account for RudderStack
Make sure to create the service account for the BigQuery project you set up above.
For RudderStack to successfully send events to your BigQuery instance, you need to set up a service account with a role containing the following permissions:
You can skip the bigquery.datasets.create permission if the dataset already exists.
Follow these steps to set up a service account:
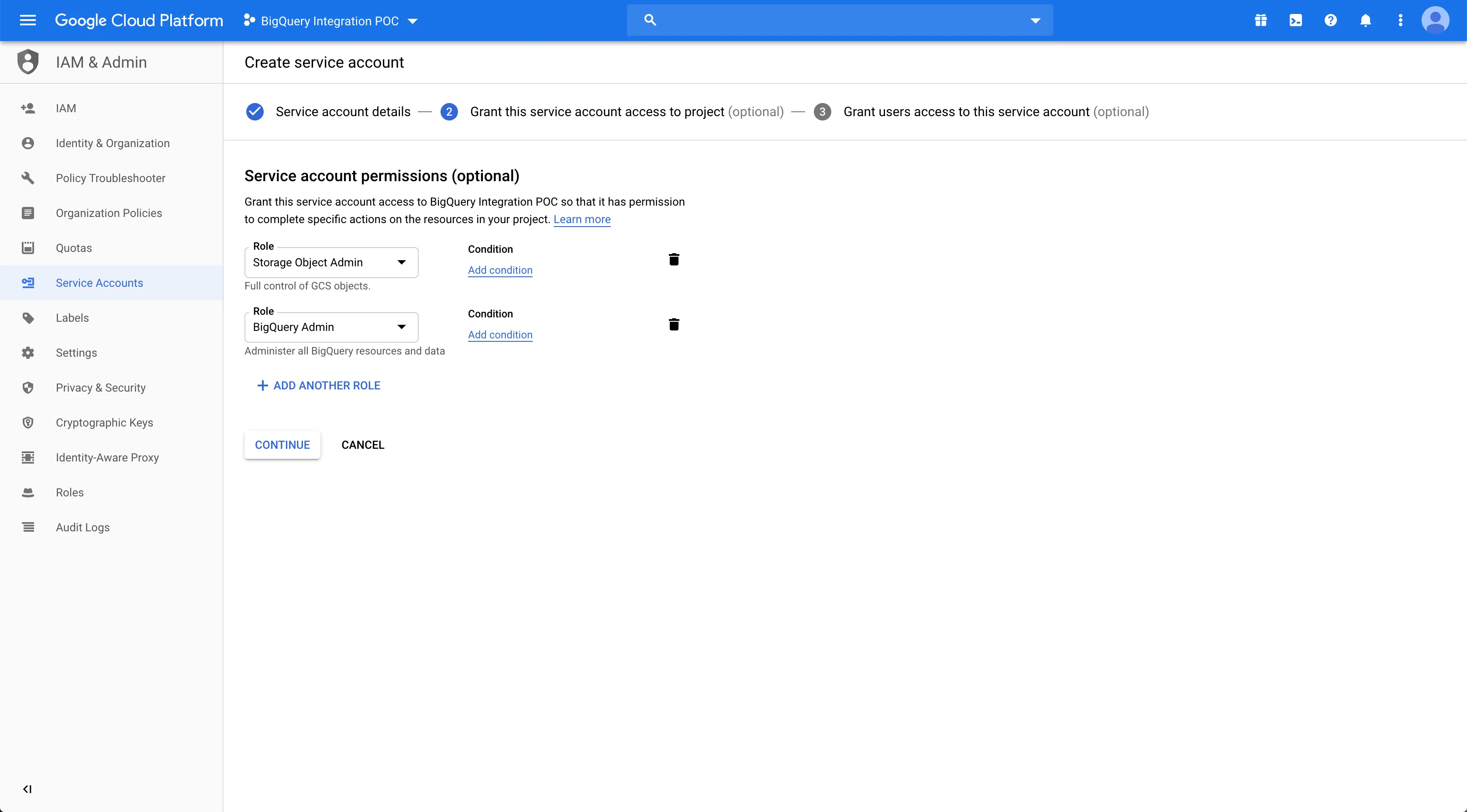
Create a new service account by going to IAM & Admin > Service Accounts.
Create a new role with the permissions mentioned above. Then, assign it to the service account.
If you do not want to add the above fine-grained permissions to the service account individually, you can add the below roles to your service account:
Storage Object Creator
Storage Object Viewer
BigQuery Job User
BigQuery Data Owner
If the dataset name already exists (configurable by the Namespace setting in the RudderStack dashboard), you can assign the BigQuery Data Editor role instead of BigQuery Data Owner.
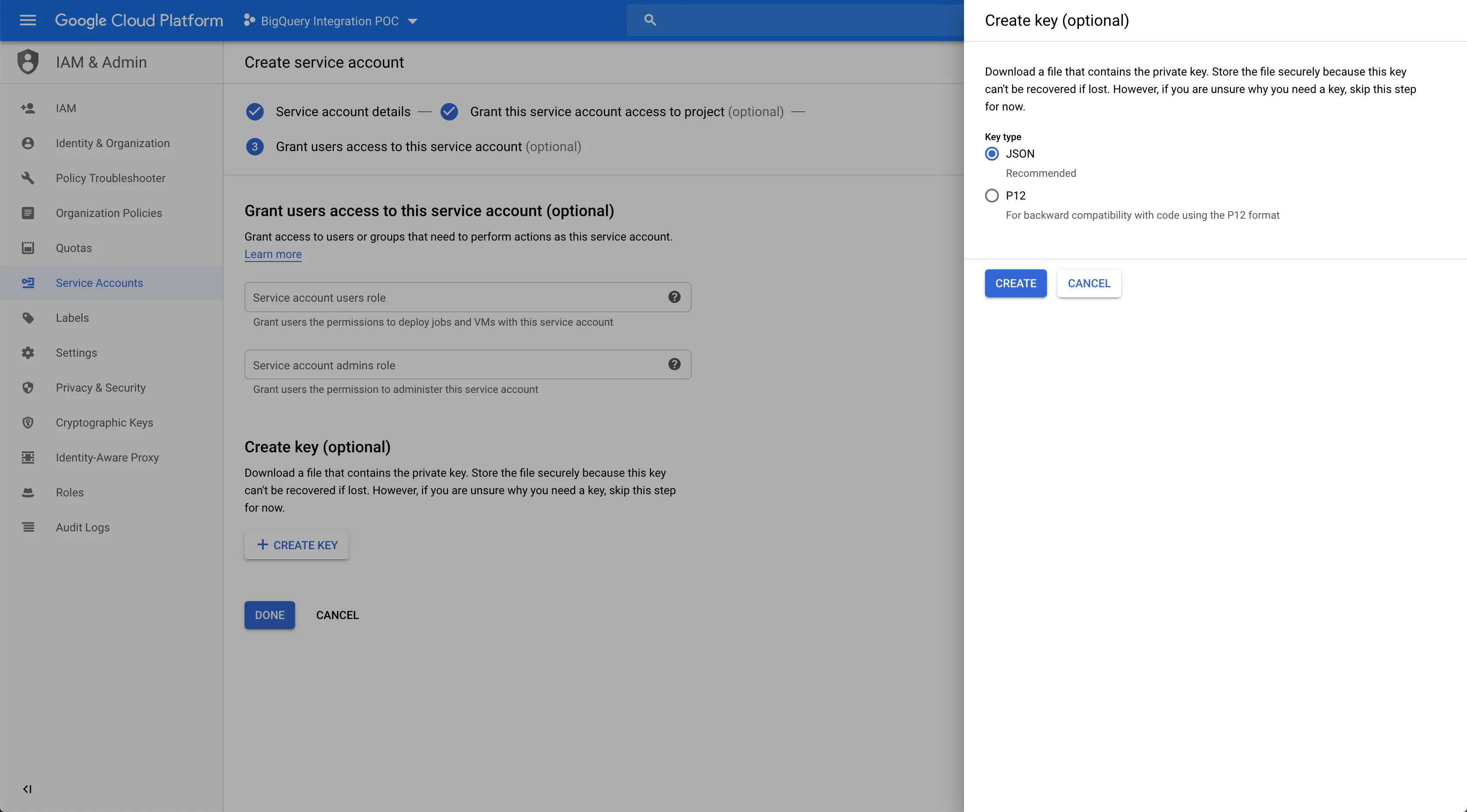
Create a key for the service account with JSON as the type and store it.
Create and download the private JSON key required for configuring BigQuery as a destination in RudderStack:
IPs to be allowlisted
By default, you can access BigQuery via the Google APIs, which are publicly accessible. As such, allowlisting any IPs is not required. However, if your VPC service restricts the BigQuery APIs, you will need to allowlist the below IPs by setting up network access control for BigQuery.
To enable network access to RudderStack, allowlist the following RudderStack IPs depending on your region and RudderStack plan:
Plan
Region
US
EU
Free, Starter, and Growth
3.216.35.97
18.214.35.254
23.20.96.9
34.198.90.241
34.211.241.254
52.38.160.231
54.147.40.62
3.123.104.182
3.125.132.33
18.198.90.215
18.196.167.201
Enterprise
3.216.35.97
34.198.90.241
44.236.60.231
54.147.40.62
100.20.239.77
3.66.99.198
3.64.201.167
3.123.104.182
3.125.132.33
All the outbound traffic is routed through these RudderStack IPs.
Configuring Google BigQuery destination in RudderStack
To send event data to BigQuery, you first need to add it as a destination in RudderStack and connect it to your data source. Once the destination is enabled, events will automatically start flowing to BigQuery via RudderStack.
To configure BigQuery as a destination in RudderStack, follow these steps:
In your RudderStack dashboard, set up the data source. Then, select BigQuery from the list of destinations.
Assign a name to your destination and then click Next.
Connection settings
Project: The GCP project ID where the BigQuery database is located.
Location: The GCP region for your dataset.
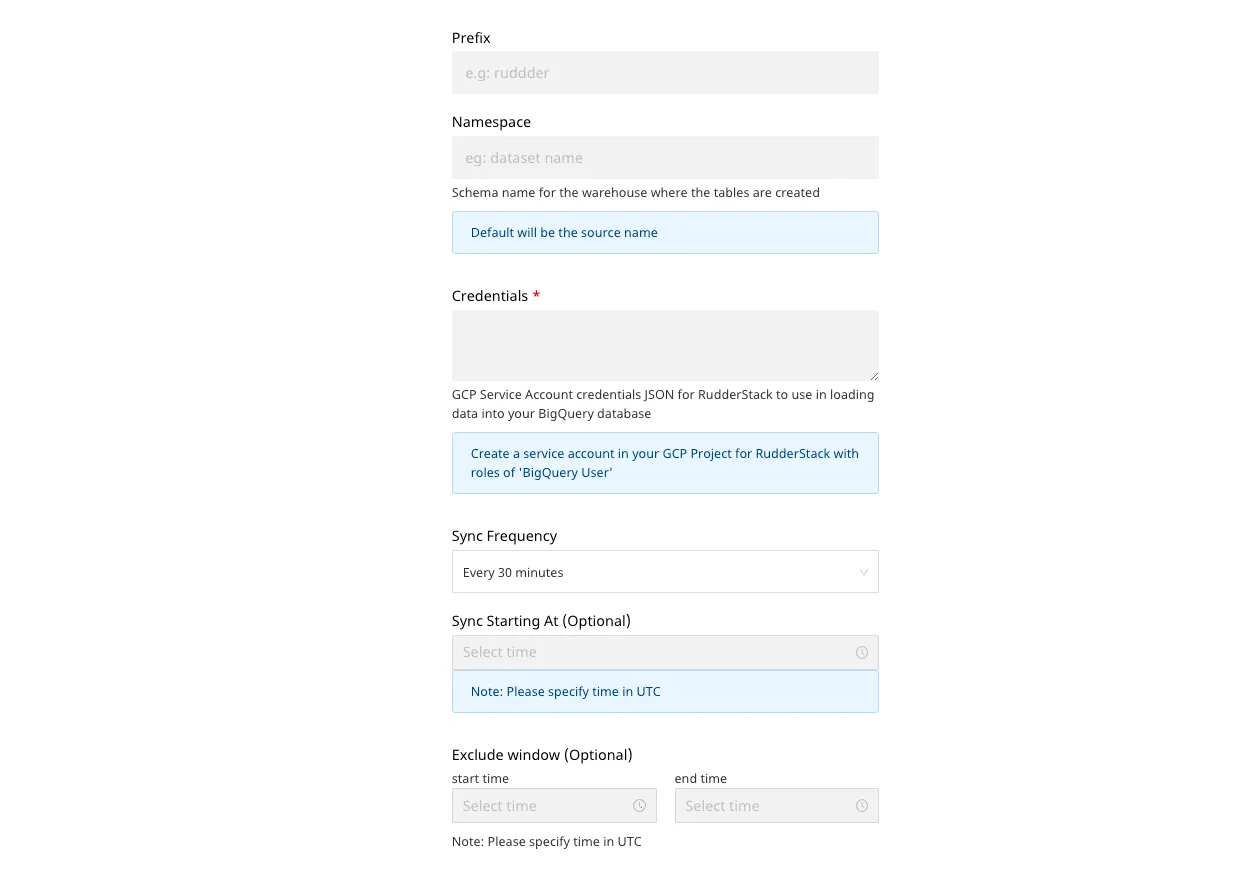
Staging GCS Storage Bucket Name: The name of the storage bucket as specified in the Setting up the BigQuery project section.
Prefix: If specified, RudderStack creates a folder in the bucket with this prefix and pushes all data within that folder.
Namespace: Enter the schema name where RudderStack creates all tables. If you don’t specify any namespace, RudderStack sets the namespace to the source name, by default.
Clean up object storage files after successful sync: Turn on this toggle to delete the object storage files after the sync has completed successfully.
Sync Frequency: Specify how often RudderStack should sync the data to your BigQuery dataset.
Sync Starting At: This optional setting lets you specify the particular time of the day (in UTC) when you want RudderStack to sync the data to BigQuery.
Exclude Window: This optional setting lets you set a time window when RudderStack will not sync the data to your database.
Partition Column: Specify how you want to partition your tables by choosing from the following options:
Ingestion Time: Time at which BigQuery ingests the data. See Ingestion time partitioning for more information.
Loaded At: Time at which RudderStack loads the data in the warehouse (loaded_at column).
Received At: Time at which RudderStack receives the data (received_at column).
Timestamp: Timestamp calculated by RudderStack to account for the client-side clock skew (timestamp column).
Sent At: Time at which the data was sent from the client to RudderStack (sent_at column).
Original Timestamp: Time when the data was generated at the source (original_timestamp column).
See Time-unit column partitioning for more information on how BigQuery puts the data into the partition based on the values in the Loaded At, Received At, Timestamp, Sent At, and Original Timestamp columns.
Partition Type: Specify the partition’s granularity level from the dropdown. RudderStack provides two options - Hour and Day.
You cannot edit the partition settings for existing BigQuery destinations through the dashboard. RudderStack automatically sets their partitioning type to Ingestion time partitioning with a day level granularity.
To change your partition configuration, RudderStack recommends creating a new BigQuery destination and deprecating the old one.
To apply partition changes to an existing destination, contact RudderStack Support.
Advanced settings
Skip User Table: This setting is toggled on by default and sends events exclusively to the identifies table while skipping the users table. This eliminates the need for a merge operation on the users table. If toggled off, RudderStack sends the events to both the identifies and users tables.
Skip Tracks Table: Toggle on this setting to skip sending events to the tracks table.
Skip Views Creation: Toggle on this setting to disable views creation in BigQuery. See Partitioned tables and views for more information.
This setting is configurable only while creating a new BigQuery destination and cannot be changed later.
JSON Columns: Use this setting to specify the required JSON column paths in dot notation separated by commas. This option applies to all incoming track events for this destination.
With the JSON columns feature, you can ingest semi-structured event data not defined by a fixed schema.
How RudderStack creates the dataset
RudderStack uses the source name (written in snake case, for example, source_name) to create a dataset in BigQuery.
See the Warehouse Schema guide for more details on the tables and columns created by RudderStack.
By default, RudderStack uses the partitioned tables method to ingest data into BigQuery.
Partitioned tables
RudderStack creates ingestion-time partition tables based on the load date, so you can take advantage of it to query a subset of data.
For information on how RudderStack creates these tables on load, see the Creating partitioned tables section of the BigQuery documentation.
RudderStack does not discard duplicate data while loading it into BigQuery.
Views
In addition to tables, RudderStack creates a view (<table_name>_view) for every table for de-duplication purposes, ensuring that queried events are unique and contain the latest records.
Note that:
RudderStack recommends using the corresponding view (containing the events from the last 60 days) to avoid duplicate events in your query results.
Since BigQuery views are merely logical views and are not cached, you can create a native table from it to save costs - by avoiding running the query that defines the view every time.
You can modify the view query to change the time window of the view - the default value is set to 60 days.
Skip views creation
Toggle on the Skip Views Creation connection setting to disable creating views in BigQuery.
RudderStack recommends skipping views creation only if:
You do not need views and want to take care of deduplication by yourself.
You have alternative deduplication methods (for example, partition columns and types).
You have any security reasons and want to limit access to the tables.
FAQ
I am getting an “Failed to add columns for table <table_name> in the name ” error even though the table column limit is not reached. How do I resolve this issue?
According to BigQuery documentation, the maximum columns in a table, query result, or view definition cannot exceed 10000 columns. This includes recently deleted columns that persist in the total columns quota until it resets.
To circumvent the “Failed to add columns for table <table_name> in the name ” error when the table column limit is not reached, you can create a new table using CLONE and take a backup of the existing table to resolve the issue:
Create new table using CLONE by using the below query:
By default, BigQuery is accessible via publicly accessible Google APIs. As such, allowlisting any IPs is not required. However, if your VPC service restricts the BigQuery APIs, you will need to allowlist the IPs by setting up network access control for BigQuery.
How are reserved words handled by RudderStack?
There are some limitations when it comes to using reserved words in a schema, table, or column names. If such words are used in event names, traits or properties, they will be prefixed with a _when RudderStack creates tables or columns for them in your schema.
Besides, integers are not allowed at the start of the schema or table name. Hence, such schema, column or table names will be prefixed with a _.
For instance, '25dollarpurchase’ will be changed to '_25dollarpurchase'.
When sending data into a data warehouse, how can I change the table where this data is sent?
By default, RudderStack sends the data to the table/dataset based on the source it is connected to. For example, if the source is Google Tag Manager, RudderStack sets the schema name as gtm_*. However, you can override this behavior by setting the Namespace field in the BigQuery destination settings:
I’m looking to send data to BigQuery through RudderStack and I’m trying to understand what data is populated in each column. How do I go about this?
Refer to the Warehouse Schema documentation for details on how RudderStack generates the schema in the warehouse and populates the data in each column.
I am trying to load data into my BigQuery destination and I get the error “Cannot read and write in different locations”. What should I do?
Make sure that both your BigQuery dataset and the bucket have the same region.
When piping data to a BigQuery destination, I can set the bucket but not a folder within the bucket. Is there a way to put RudderStack data in a specific bucket folder?
Yes, you can set the desired folder name in the Prefix field while setting up your BigQuery destination in RudderStack.
Does open source RudderStack support near real-time syncing to BigQuery and event replay?
The near-realtime BigQuery syncing feature is currently under development and is planned to be released in the coming months. Unfortunately, Event Replay is not a part of open-source RudderStack currently.
What is the current sync frequency for BigQuery?
If you’re using open source RudderStack, the minimum sync frequency is 30 minutes. If you’re self-hosting the data plane or using RudderStack’s Enterprise plan, you can assign the required value for sync frequency to the uploadFreqInS parameter in config.yaml file. Note that the minimum value can be 1800 (30 minutes).
Do I need to stop the running pipeline to change my sync frequency? Or will the new change be effective even without stopping the pipeline?
To change the sync frequency, you need not stop the pipeline.
When configuring the BigQuery destination, where does Google use the credentials JSON from?
BigQuery uses the credentials JSON from the dashboard configuration when setting up the destination. For more information, refer to the Setting up the service account for RudderStack section.
When configuring the BigQuery destination, should the user permissions be set for the specific dataset or the whole project?
You need to set the user permissions for the whole project. Otherwise, you may encounter issues.
How long are the failed syncs retried before being aborted?
RudderStack retries the failed syncs for up to 3 hours before aborting them. For more information, refer to this FAQ.
For a more comprehensive FAQ list, refer to the Warehouse FAQ guide.
Questions? We're here to help.
Join the RudderStack Slack community or email us for support
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.