In the left sidebar, click Database and the corresponding Schema to view the list of all tables. You can hover over a table to see the full table name along with its creation date and time.
Write a SQL query like select * from <table_name> limit 10; and execute it to see the results:
Open Postico2. If required, create a new connection by entering the relevant details. Click Test Connection followed by Connect.
Click the + icon next to Queries in the left sidebar.
You can click Database and the corresponding schema to view the list of all tables/views.
Double click on the appropriate view name to paste the name on an empty worksheet.
You can prefix SELECT * from the view name pasted previously and suffix LIMIT 10; at the end.
Press Cmd+Enter keys, or click the Run button to execute the query.
Enter your Databricks workspace URL in the web browser and log in with your username and password.
Click the Catalog icon in left sidebar.
Choose the appropriate catalog from the list and click on it to view the contents.
You will see list of tables/views. Click on the appropriate table/view name to paste the name on the worksheet.
Then, you can prefix SELECT * FROM before the pasted view name and suffix LIMIT 10; at the end.
Select the query text. Press Cmd+Enter or click the Run button to execute the query.
Select Bigquery from Product and Pages to open the Bigquery Explorer.
Select the correct project from top left drop down menu.
In the left sidebar, click the project ID, then the corresponding dataset view list of all the tables and views.
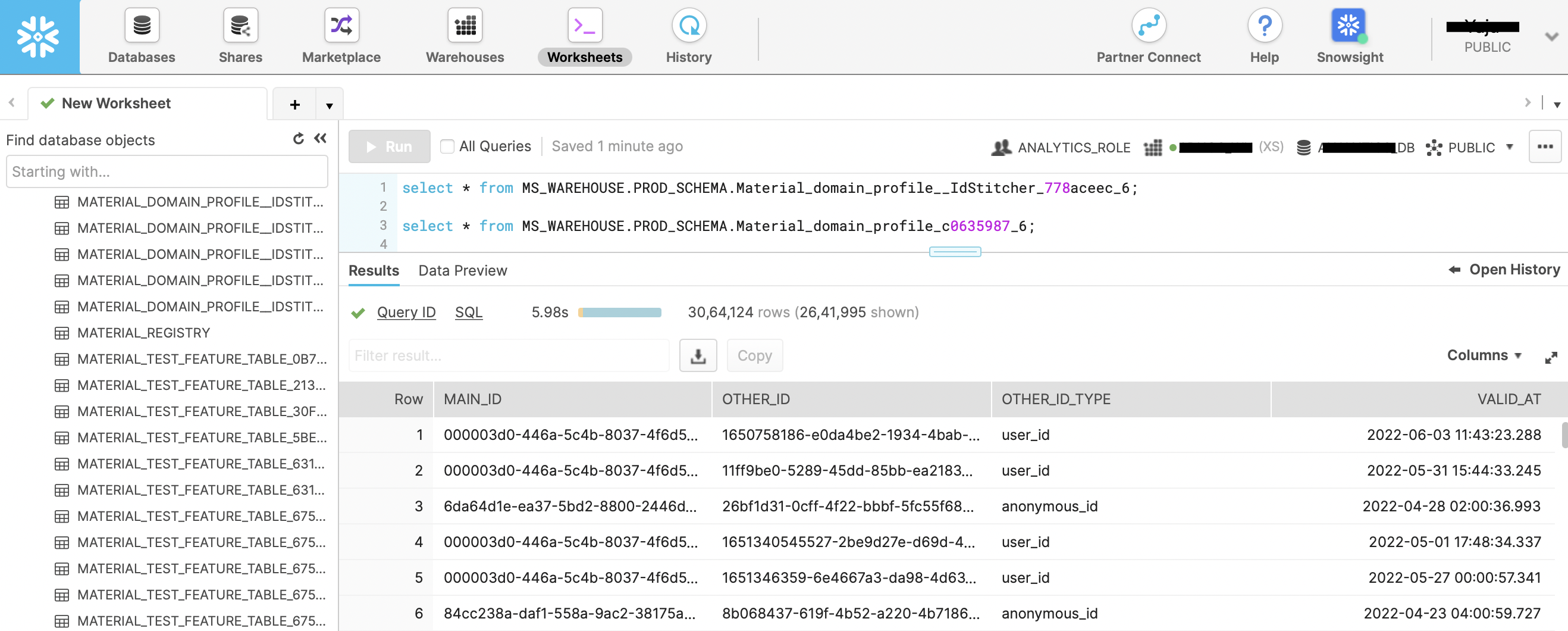
Write a SQL query like select * from <table_name> limit 10; and execute it to see the results.
A sample output containing the results in Snowflake:
Profiles creates a default ID stitcher even if you do not define any specs for creating one. It takes default ID stitcher as the input and all the sources and ID types defined in the file inputs.yaml. When you define the specs, it creates a custom ID stitcher.
Sample project for Custom ID Stitcher
This sample project considers multiple user identifiers in different warehouse tables to ties them together to create a unified user profile. The following sections describe how to define your PB project files:
Project detail
The pb_project.yaml file defines the project details such as name, schema version, connection name and the entities which represent different identifiers.
There can be different ID types for an entity. You can include all such identifiers in the id_types field under entities. main_id specified under id_types is not an ID type but a placeholder for the column which serves as the primary identifier for that entity.
In case of id_stitcher model, the main_id for the entity is rudder_id (predefined ID type) by default. For other models, any other ID type can be the main_id, for example session_id. Hence, if you want to specify the ID type of a column as a primary identifier, you can specify main_id.
# Project namename:sample_id_stitching# Project's yaml schema versionschema_version:61# Warehouse connectionconnection:test# Allow inputs without timestampsinclude_untimed:true# Folder containing modelsmodel_folders:- models# Entities in this project and their ids.entities:- name:userid_stitcher:models/user_id_stitcher# modelRef of custom ID stitcher modelid_types:- main_id # You need to add ``main_id`` to the list only if you have defined ``main_id_type:main_id`` in the id stitcher buildspec.- user_id# one of the identifier from your data source.- email# lib packages can be imported in project signifying that this project inherits its properties from therepackages:- name:coreliburl:"https://github.com/rudderlabs/profiles-corelib/tag/schema_{{best_schema_version}}"# if required then you can extend the package definition such as for ID types.
Input
The input file (models/inputs.yaml) file includes the input table references and corresponding SQL for the above-mentioned entities:
inputs:- name:rsIdentifiescontract:# constraints that a model adheres tois_optional:falseis_event_stream:truewith_entity_ids:- userwith_columns:- name:timestamp- name:user_id- name:anonymous_id- name:emailapp_defaults:table:rudder_events_production.web.identifies# one of the WH table RudderStack generates when processing identify or track events.occurred_at_col:timestampids:- select:"user_id"# kind of identity sql to pick this column from above table.type:user_identity:user# as defined in project fileto_default_stitcher:true- select:"anonymous_id"type:anonymous_identity:userto_default_stitcher:true- select:"lower(email)"# can use sql.type:emailentity:userto_default_stitcher:true- name:rsTrackscontract:is_optional:falseis_event_stream:truewith_entity_ids:- userwith_columns:- name:timestamp- name:user_id- name:anonymous_idapp_defaults:table:rudder_events_production.web.tracks# another table in WH maintained by RudderStack processing track events.occurred_at_col:timestampids:- select:"user_id"type:user_identity:userto_default_stitcher:true- select:"anonymous_id"type:anonymous_identity:userto_default_stitcher:true
As seen in the above file, you can use SQL to achieve some complex scenario as well.
Model
Profiles Identity stitching model maps and unifies all the specified identifiers (in pb_project.yaml file) across different platforms. It tracks the user journey uniquely across all the data sources and stitches them together to a rudder_id.
A sample profiles.yaml file specifying an identity stitching model (user_id_stitcher) with relevant inputs:
Specifies the validity of the model with respect to its timestamp. For example, a model run as part of a scheduled nightly job for 2009-10-23 00:00:00 UTC with validity_time: 24h would still be considered potentially valid and usable for any run requests, which do not require precise timestamps between 2009-10-23 00:00:00 UTC and 2009-10-24 00:00:00 UTC. This specifies the validity of generated feature table. Once the validity is expired, scheduling takes care of generating new tables. For example: 24h for 24 hours, 30m for 30 minutes, 3d for 3 days
entity_key
String
Specifies the relevant entity from your input.yaml file. For example, here it should be set to user.
materialization
List
Adds the key run_type: incremental to run the project in incremental mode. This mode considers row inserts and updates from the edge_sources input. These are inferred by checking the timestamp column for the next run. One can provide buffer time to consider any lag in data in the warehouse for the next incremental run like if new rows are added during the time of its run. If you do not specify this key then it’ll default to run_type: discrete.
incremental_timedelta
List
(Optional )If materialization key is set to run_type: incremental, then this field sets how far back data should be fetched prior to the previous material for a model (to handle data lag, for example). The default value is 4 days.
main_id_type
ProjectRef
(Optional) ID type reserved for the output of the identity stitching model, often set to main_id. It must not be used in any of the inputs and must be listed as an id type for the entity being stitched. If you do not set it, it defaults to rudder_id. Do not add this key unless it’s explicitly required, like if you want your identity stitcher table’s main_id column to be called main_id. For more information, see below.
edge_sources
List
Specifies inputs for the identity stitching model as mentioned in the inputs.yaml file.
Use cases
This section describes some common identity stitching use cases:
Identifiers from multiple data sources: You can consider multiple identifiers and tables by:
Adding entities in pb_project.yaml representing identifiers.
Adding references to table and corresponding sql in models/inputs.yaml
Adding table reference names defined in models/inputs.yaml as edge_sources in your model definition.
Leverage Sql Support: You can use SQL in your models/inputs.yaml to achieve different scenarios. For example, you want to tag all the internal users in your organization as one entity. You can use the email domain as the identifier by adding a SQL query to extract the email domain as the identifier value: lower(split_part({{email_col}}, '@', 2))
Custom ID Stitcher: You can define a custom ID stitcher by defining the required id stitching model in models/profiles.yaml.
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.