Learn how to create unified customer records in your warehouse using RudderStack Profiles.
Available Plans
enterprise
6 minute read
Modern data teams rely on their warehouse as a single source of truth for customer data. RudderStack’s Profiles feature unifies every user touchpoint and trait into comprehensive customer profiles, establishing the data warehouse as the core of the customer data platform.
With Profiles, data teams can efficiently resolve identities and create user features to produce a comprehensive customer 360 table.
Highlights
See the following guides to learn more about Profiles features and their usage:
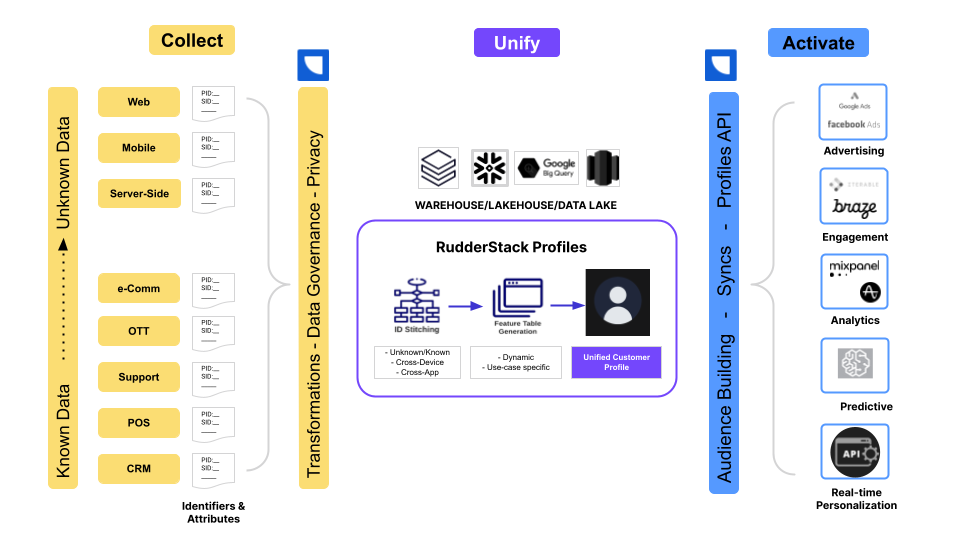
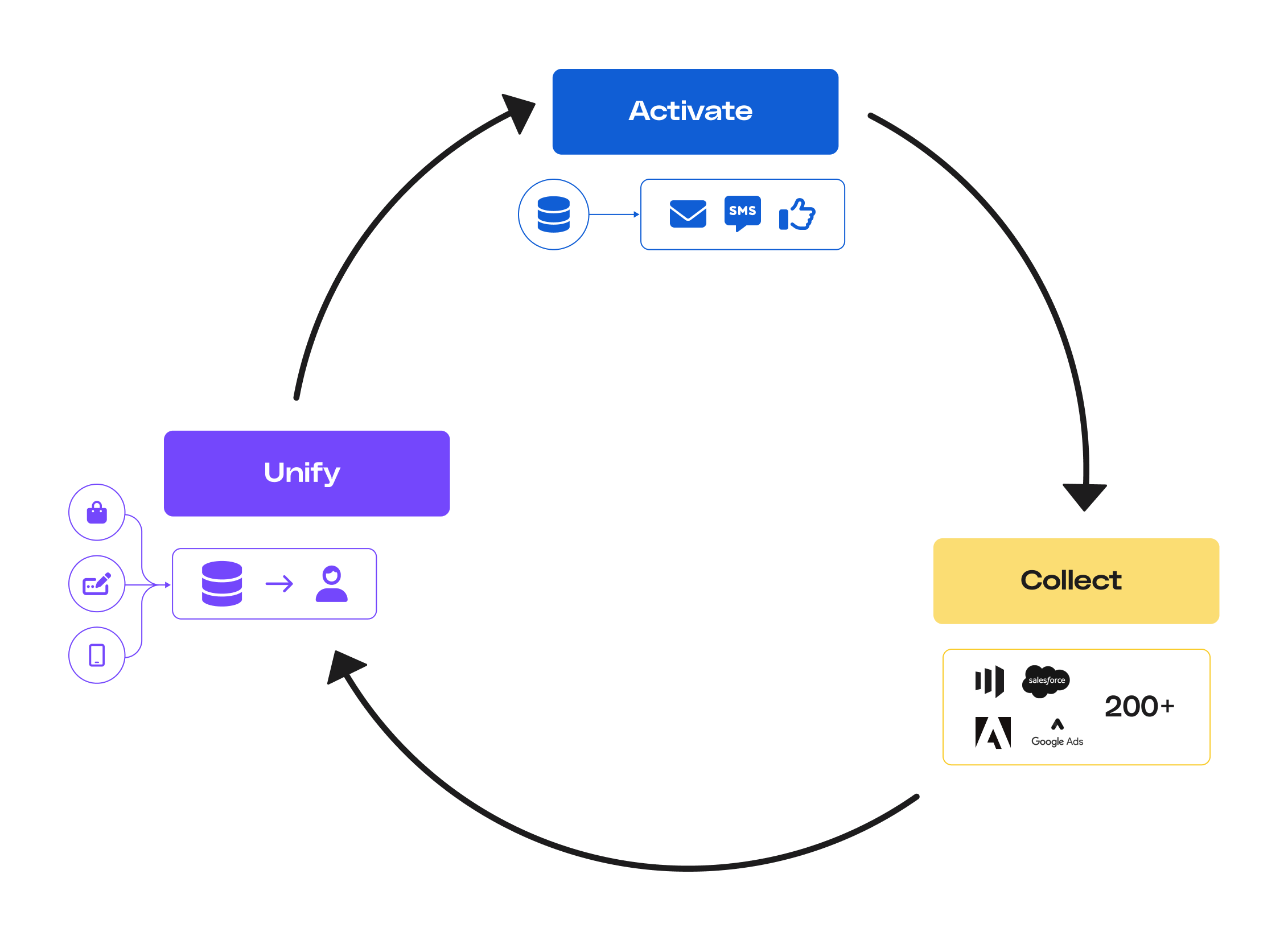
RudderStack helps you build a complete CDP on top of your data warehouse in three stages - Collect, Unify, and Activate.
The following sections highlight RudderStack’s comprehensive solution at every stage to create a complete customer profile.
Collect
First, RudderStack collects and stores all the source data in your warehouse. This includes:
Event data (for example, user interaction data from web and mobile apps)
Data from cloud sources (for example, CRM platforms like Salesforce, support tools like Zendesk, etc.)
Known data
RudderStack collects all the information from:
First-party data: Data collected from the enterprise’s own mobile application, websites, POS systems, etc.
Third-party apps like SalesForce CRM, Zendesk Support, ecommerce payments via Stripe, etc.
There is a known ID for all of these by which RudderStack collects the data like email, user ID, etc.
Unknown Data
This includes unknown user attributes like anonymousId captured from the RudderStack SDKs on the web/mobile apps. It is helpful in tracking user activities in cases where they are not logged in.
The difference between known and unknown data is that in the former, we have information about the user. First-party data can be known data if a user is logged in. For example, the data from cloud sources will always be known. However, data from the event stream sources can be known or unknown depending on whether a user had logged in.
As the data is collected, you can apply relevant transformations to it for compliance/security purposes like data governance, privacy, etc.
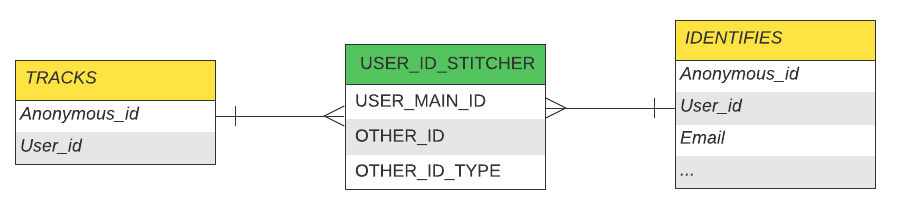
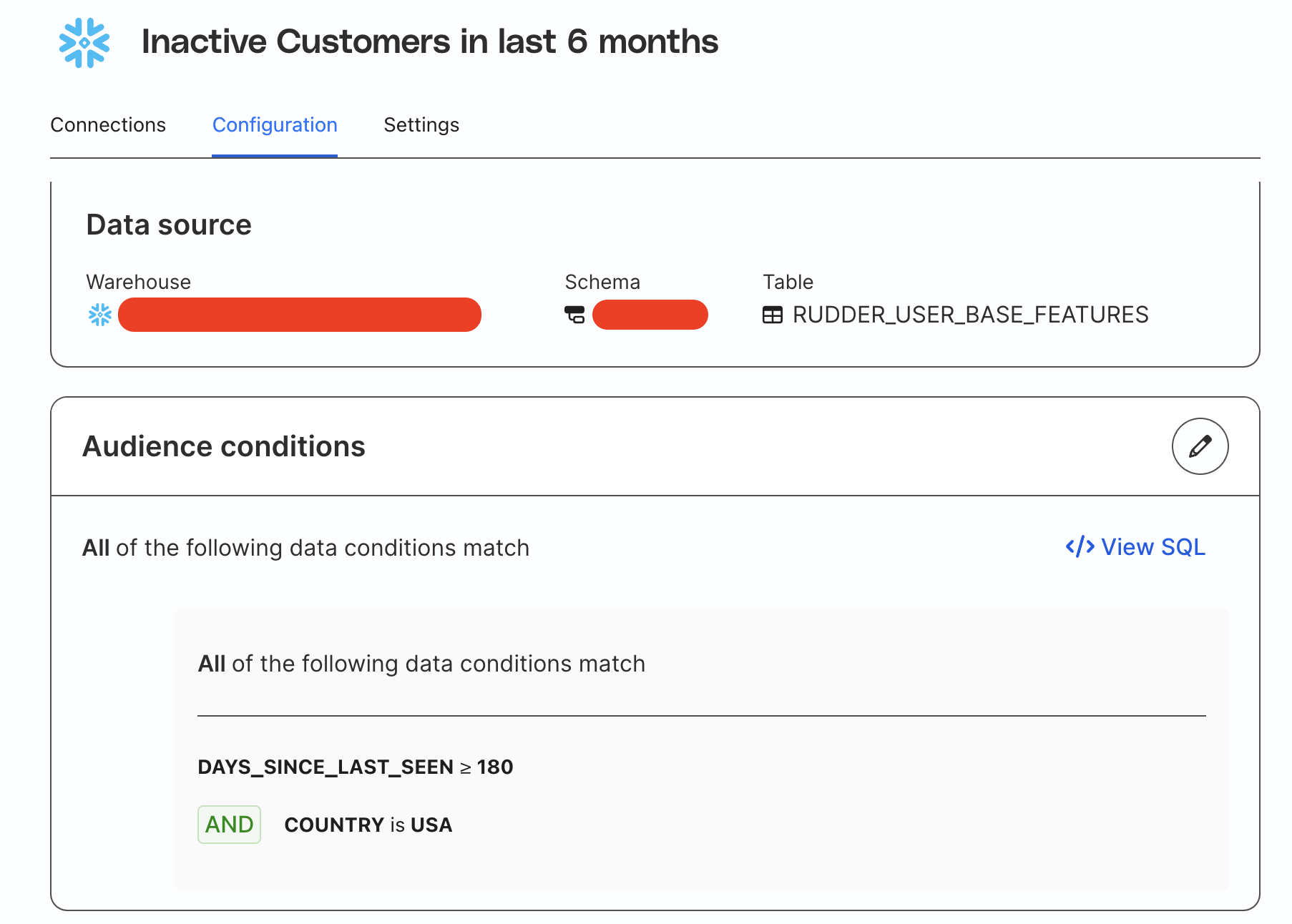
The below image highlights a snapshot of the identifies and trackstables, that RudderStack leverages for unifying the data.
Unify
This is the stage where Profiles comes into play. Primarily, two things are done here.
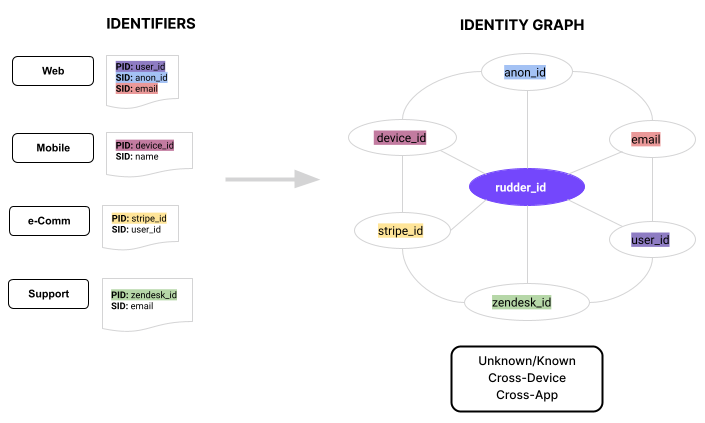
ID Stitching
Profiles stitches together all the known and unknown IDs into a single table. The IDs are linked using an autogenerated ID known as rudderId, which is akin to a golden record. Imagine a one-to-many relationship, in which one rudderId has multiple values for other IDs like user ID, anonymous ID, email, etc.
With a rudderId, you can easily identify that a customer - who shopped on your website 6 months ago, anonymously browsed from mobile 4 months ago, raised a complaint with the support team 2 months ago - is actually the same customer. RudderStack represents them as different nodes/edges of the ID stitching graph.
Entity Traits 360
If the features/traits of an entity are spread across multiple entity vars and ML models, you can use Entity Traits 360 to get them together into a single view. These models are usually defined in the pb_project.yaml file by creating entries under serve_traits key with corresponding entity.
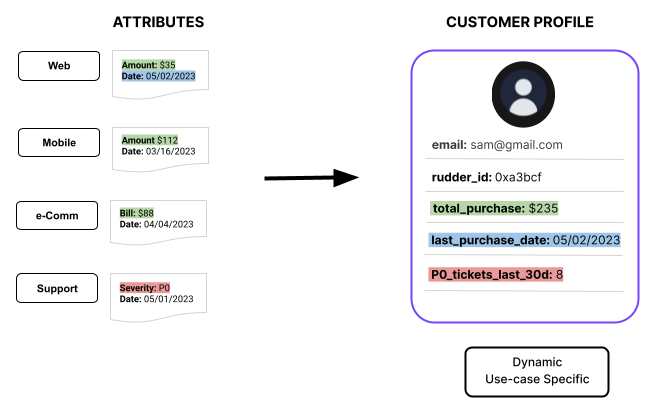
Feature Table
The entity vars specified in the project are unified into a view. A Feature Table is a unified customer profile containing useful information for each customer. Once all the known and unknown identities are stitched together, you can trace back activities for all such identifiers and aggregate them under the common rudderId. This is helpful in calculating features across all such interactions.
Some common use cases are computing the customer’s total LTV (lifetime value), purchase history, number of days a customer was active, etc.
Activate
Activation is a two-step process. In the first step, the user creates the target audience using RudderStack’s Audiences feature. They would then use Reverse ETL to route this audience information (also persisted in the same cloud warehouse) to downstream marketing tools like Braze, Mailchimp, etc.
Additionally - you can use the feature tables as inputs to ML models for use cases like churn prediction, lifetime value (LTV) prediction, etc. Again, you can route the output of such models to marketing platforms via Reverse ETL.
As you keep collecting data, Profiles continues to unify and send it for activation.
In this way, you can make informed decisions, run personalized marketing campaigns, and enhance the overall customer experience across multiple platforms.
Why use Profiles?
Data teams often face challenges when building a complete view of their customer. Maintaining large, complex SQL models or working around the limitations of rigid SaaS platforms is time-consuming and expensive at scale.
Profiles simplifies this process of unifying customer data by automating the manual data engineering and modeling required to build an identity graph, layer new data sources into customer profiles, and compute user features that leverage data from various disparate sources.
Using Profiles, data teams can quickly build and easily maintain a comprehensive customer 360 table and make it available to downstream teams and tools.
Move faster with an end-to-end platform
Profiles integrates directly with RudderStack’s other pipelines, which enables it to automatically solve otherwise complex data challenges throughout the entire data lifecycle.
Customer data ingested through RudderStack’s Event Stream pipelines have known schemas and unique identifiers. Profiles can produce a baseline identity graph, and user features out of the box. Data teams can then augment the graph and features using any other data in their warehouse.
RudderStack’s Reverse ETL pipeline makes it easy to send data from the customer 360 table directly to the downstream tools used by marketing, customer success, product, and other teams.
Enrich user profiles with features
With Profiles, you can enhance user profiles with additional data points and features. When new data sources are added, discovered, or calculated, data teams can add them to their Profiles configuration without having to clean data and update complex models and dependencies.
The features/traits can include demographic information, preferences, purchase history, browsing behavior, or other static or computed data points.
Unlock deeper insights
Profiles extends its capabilities to support features derived from complex concepts such as funnels, organizational metrics, and machine learning models. You can understand your customer’s journey through your sales funnel or locate each user across the histogram of customer metric values by simply defining a trait.
Deliver personalization and recommendations
Using Profiles, you can ship projects like personalization significantly faster by focusing entirely on activating key user features instead of cleaning and modeling data to build them.
Predict user conversions and churn
You can leverage Predictions to build predictive features that help you predict in advance whether a lead is likely to convert, or a customer is likely to churn or make a purchase.
Who can leverage Profiles?
Profiles is built for data engineers, data scientists, and technical marketers. You can define identity stitching, and user features as configuration files without requiring deep SQL, Python, or technical knowledge.
You can define the associated properties or attributes that provide detailed information for each new feature. For example, if the feature is purchase_history, its properties can include the date of purchase, product category, or order value.
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.