Feeling stuck with Segment? Say 👋 to RudderStack.
Blogs
What is the ML Stack?
Written by
Eric Dodds
Head of Product Marketing
Dileep Patchigolla
Principal Data Scientist, RudderStack
This is part III of a series breaking down each phase of the Data Maturity Journey, a framework we created to help data teams architect a practical customer data stack for every phase of their company’s journey to data maturity.
Before we get to the hot topic of machine learning, let’s do a quick recap of where we are in the data maturity journey. In the Starter Stack, you solved the point-to-point integration problem by implementing a unified, event-based integration layer. In the Growth Stack, your data needs became a little more sophisticated—to enable downstream teams (and management) to answer harder questions and act on all of your customer data, you needed to centralize both clickstream data and relational data to build a full picture of the customer and their journey. To solve these challenges you implemented a cloud data warehouse as the single source of truth for all customer data, then used reverse ETL pipelines to activate that data.
At this point, life is good. All of your customer data is collected and sent to your entire stack in real-time to cloud tools via event streaming and in batch loads to your data warehouse (via both event streaming batch loads as well as ETL for relational data). This means you can build a full view of your customer and push complete profiles, computed traits, and even audiences from your warehouse back to your stack via reverse ETL.
Yes, life is good. But could it be even better? Currently all of the insights and activation your work has enabled are based on historical data—what users have done in the past. The more teams understand about the past, though, the more they think about how to mitigate problems in the future.
Customer churn is a great example. With the right data you can easily see which customers have churned and launch win back emails, but wouldn’t it be better to engage those users before they churn? This type of magic is the next frontier of optimization, and it requires moving from historical analytics to predictive analytics. Predictive analytics enable you to determine the likelihood of future outcomes for users.
Predicting future behavior and acting on it can be extremely valuable for a business. Consider the example above. When you leverage behavioral and transactional data signals to identify customers who are likely to churn and proactively incentivize their next interaction, you’re more likely to prevent them from churning. The same is true for new users: if you can predict their potential lifetime value, you can customize offers accordingly.
This is a big step for your data team and your data stack because it introduces the need for predictive modeling, and predictive modeling requires additional tooling. The good news is that if your data is in order, which it should be if you implemented the Growth Stack, you already have a running start.
What is the ML Stack?
Machine learning, ML ops and keeping it simple
Depending on a number of factors you are considering in your analysis, and the types of data you’re using, the most scalable way to answer predictive questions is to use machine learning. Machine learning is a subset of artificial intelligence at the junction of data engineering and computer science that aims to make predictions through the use of statistical methods.
It’s worth noting from the outset that not all predictive problems have to be solved with formal machine learning, though. A deterministic model (i.e., if a customer fits these characteristics, tag them as being likely to churn) or multivariate linear regression analysis can do the job in many cases (hat tip to SQL and IF statements!). Said another way, machine learning isn’t a magic wand you can point at any problem to conjure up a game-changing answer. In fact, we would say that intentionally starting out with basic analyses and models is the best first step into predictive analytics—another good reminder of the KISS principle when building out your data stack and workflows.
If you are familiar with machine learning, you know that there is also an entire engineering discipline focused on the tools and workflows required to do the work (this is often called ML ops or ML engineering). ML engineering is different from data engineering, but the two disciplines must operate in tandem because the heart of good predictive analytics is good data. This is why many data scientists play the role of part-time data engineer.
Taking the first step
One other important thing to note: machine learning is a wide and deep field. The most advanced companies build fully custom tooling to support their various data science workflows, but for many companies complicated data science workflows are overkill. The good news is that with modern tooling, you don’t have to implement a massive amount of ML-focused infrastructure to start realizing the value of predictive modeling.
To that end, this isn’t a post about ML ops, workflows or various types of modeling. Our focus will be showing you how many companies take their first steps into predictive analytics by making simple additions to their toolset and leveraging existing infrastructure (the Growth Stack) to operationalize results from models.
Without further ado, let’s dive into the stack itself.
So, what is the ML Stack?
The ML Stack introduces a data flow that enables teams to work on predictive analytics. For companies running the Growth Stack, there are two fundamental challenges:
- Limitations of warehouse-based analysis: data teams hit ceilings in the warehouse when they 1) can’t perform their desired analysis in SQL and 2) need to work with unstructured data that can’t be stored in the warehouse (more on this below)
- Operationalizing model outputs: when models do produce outputs, it can be technically difficult to deliver them to tools where they can be used to optimize the customer journey
The ML Stack solves these problems by:
- Introducing a data lake for unstructured data
- Introducing a modeling/analysis toolset
- Leveraging existing warehouse and reverse ETL infrastructure to deliver model outputs to tools across the stack
As you can see in the architectural diagram below, the ML stack feeds data (inputs) to an analysis and modeling toolset from the data warehouse and data lake. The model runs and produces outputs (or features), which are pushed to the warehouse in the form of a materialized table. That table can then be used in the standard reverse ETL flow to send those features to the rest of the stack.
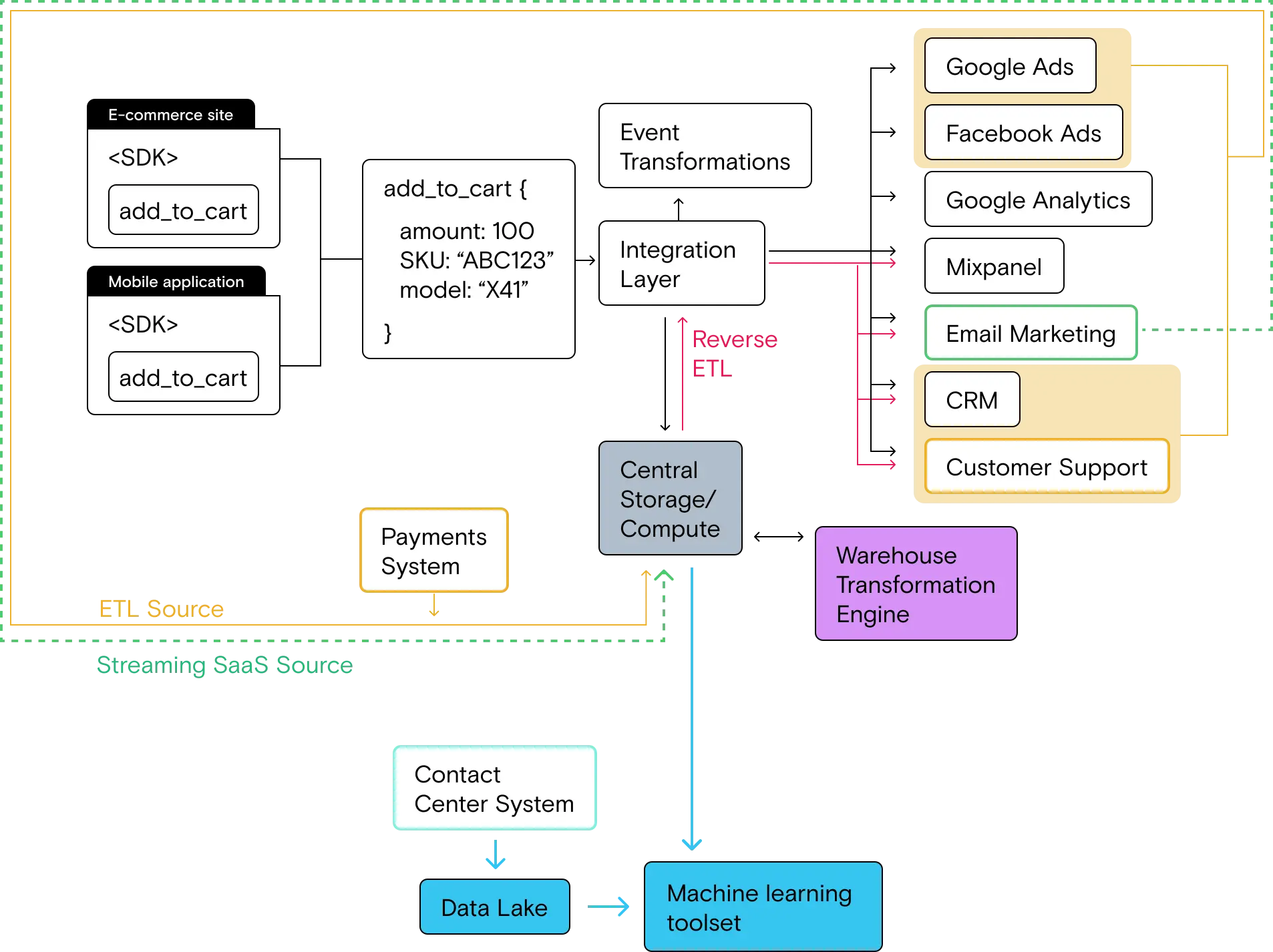
When do you need to implement the ML Stack?
You’d be surprised at how often machine learning gets thrown at questions that can be answered with basic SQL—something we heard loud and clear from one of the people who helped build the data science practice at Airbnb. So, when should you actually use machine learning?
Symptoms that indicate you need the ML Stack
The best indication you need to implement ML tooling into your stack is the desire to make data-driven predictions about the future. Here are a few example symptoms:
- Your teams have built muscle in understanding historical trends and events and why they happened, and now want to act proactively to influence those events before they occur.
- This is impossible because teams running the growth stack can’t anticipate the likelihood of those events happening, they can only analyze them in retrospect.
- You’ve hit the limits of SQL-on-warehouse analysis and are actively exploring how to apply statistical analysis to your data.
- You want to leverage new kinds of data that can’t be managed in your cloud data warehouse. This is often due to new tooling or processes that have been implemented (i.e., standing up a call center), or a desire to leverage existing data that hasn’t previously been used in analysis.
What your company or team might look like
As with every other phase of the data maturity journey, your stack isn’t about the size of your company, but your data needs. That said, stepping into the world of machine learning generally requires both a minimum threshold of data as well as dedicated resources to work on predictive projects. This means it’s often larger mid-market and enterprise companies that implement the ML Stack. But smaller companies are increasingly collecting huge amounts of data, and the ML tooling itself is getting easier to use (more on this in the tooling section below).
If your company is on the smaller end of the spectrum:
- You likely have a business that produces huge amounts of data (think eCommerce, web3, media, gaming, etc.) but can run with a smaller technical team
- Your business model stands to benefit significantly from predictive analytics, meaning you’re willing to invest in machine learning earlier in your lifecycle (this could mean a very high number of transactions for a consumer financial company or significant usage for a mobile game development company)
If your company is on the larger end of the spectrum:
- You’ve hit the limit of basic optimization across functions and are looking for the next frontier of growth, which requires moving from historical analysis to predictive analysis. This often takes the form of internal initiatives to build out a data science practice.
- You’ve desired to explore data science in the past, but the state of your data and legacy components of your stack have been blocking the effort. But now that you’ve modernized your stack, you’re prepared to step into the world of machine learning.
- Your analysts have begun to explore deeper statistical analysis and have already started teaching themselves the basics of machine learning, setting the stage for building formal data science workflows.
Returning to our example company
Let’s return to the example company that we’ve been following through their data maturity journey. Here’s the description, with the addition of a new dynamic:
You’re an eCommerce company, large or small (as we said above, company size doesn’t matter). Your website, mobile and marketing teams focus on driving digital purchases through your site and app, but you also have a sales team supporting wholesale buyers. Many of the sales team’s prospects are long-time repeat digital purchasers who would benefit from opening an account.
After launching a subscription program 6 months ago, your teams have noticed a concerning trend in cancellations. By running multiple analyses on historical data on the warehouse, you’ve discovered that most customers who churn have less than three purchases and have engaged with the customer support team.
Here’s the current Growth Stack, which includes multiple data sources (event streaming, cloud SaaS streaming and ETL), a cloud data warehouse for centralized storage/compute and multiple pipelines for integrating and activating data (direct integrations fed by real-time event streaming and reverse ETL that sends data from the warehouse to the rest of the stack).
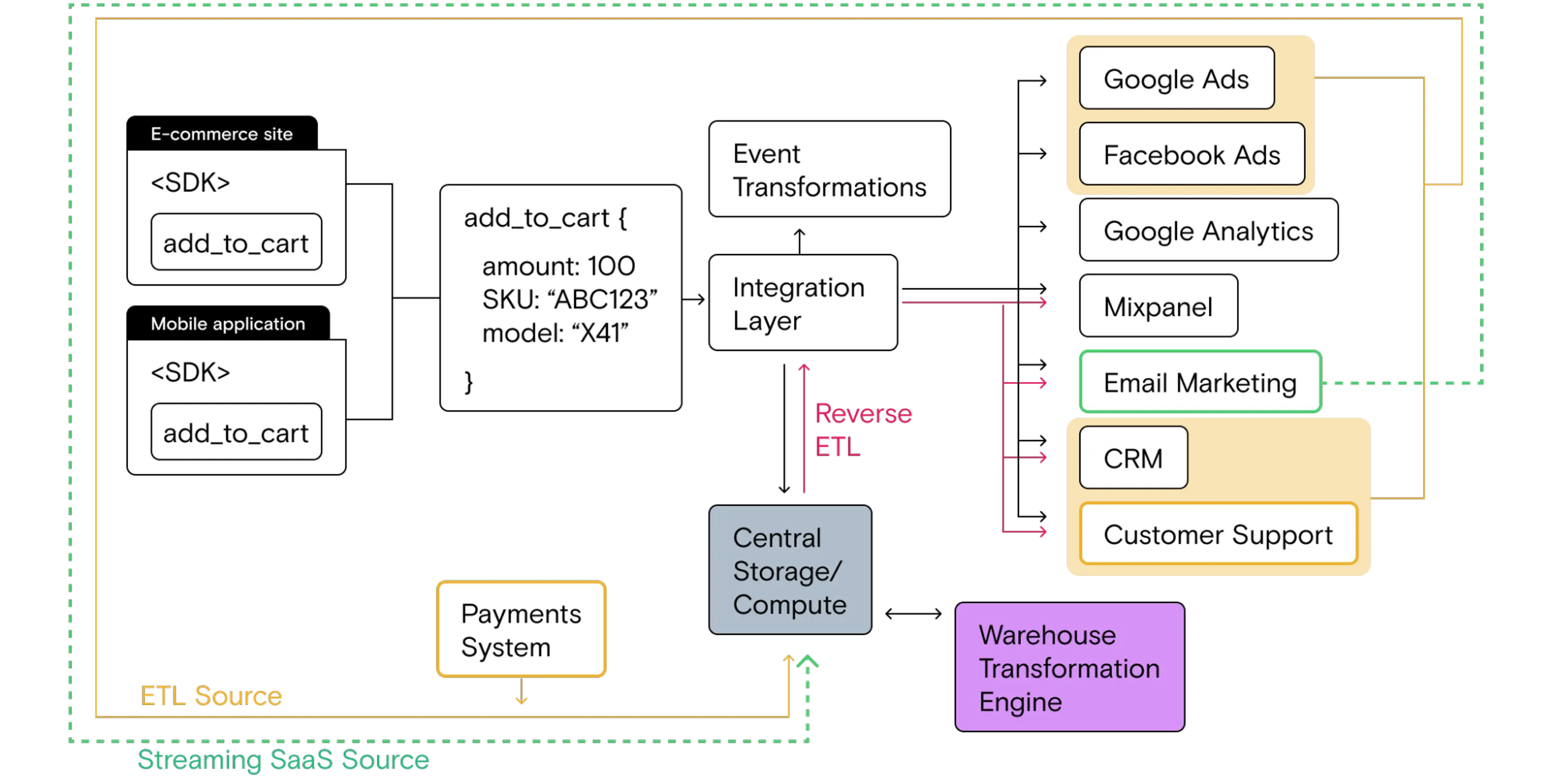
The data stack
At this point, your Growth Stack is a well-oiled machine for data collection, historical analysis and data activation. In fact, this stack is a big part of what enabled your teams to spot the subscription program churn problem.
The latest development in the stack, though, is the implementation of contact center infrastructure to help customer support representatives better serve customers with questions, problems, returns, etc. (This is different from the customer support system, which operates as a ticketing system for asynchronous support requests.)
The contact center system introduces several new types of customer data. First, support agents engage in live chats with customers who initiate contact on the website. Second, support agents have live calls with customers for certain types of support requests. This data lives in the contact center system.
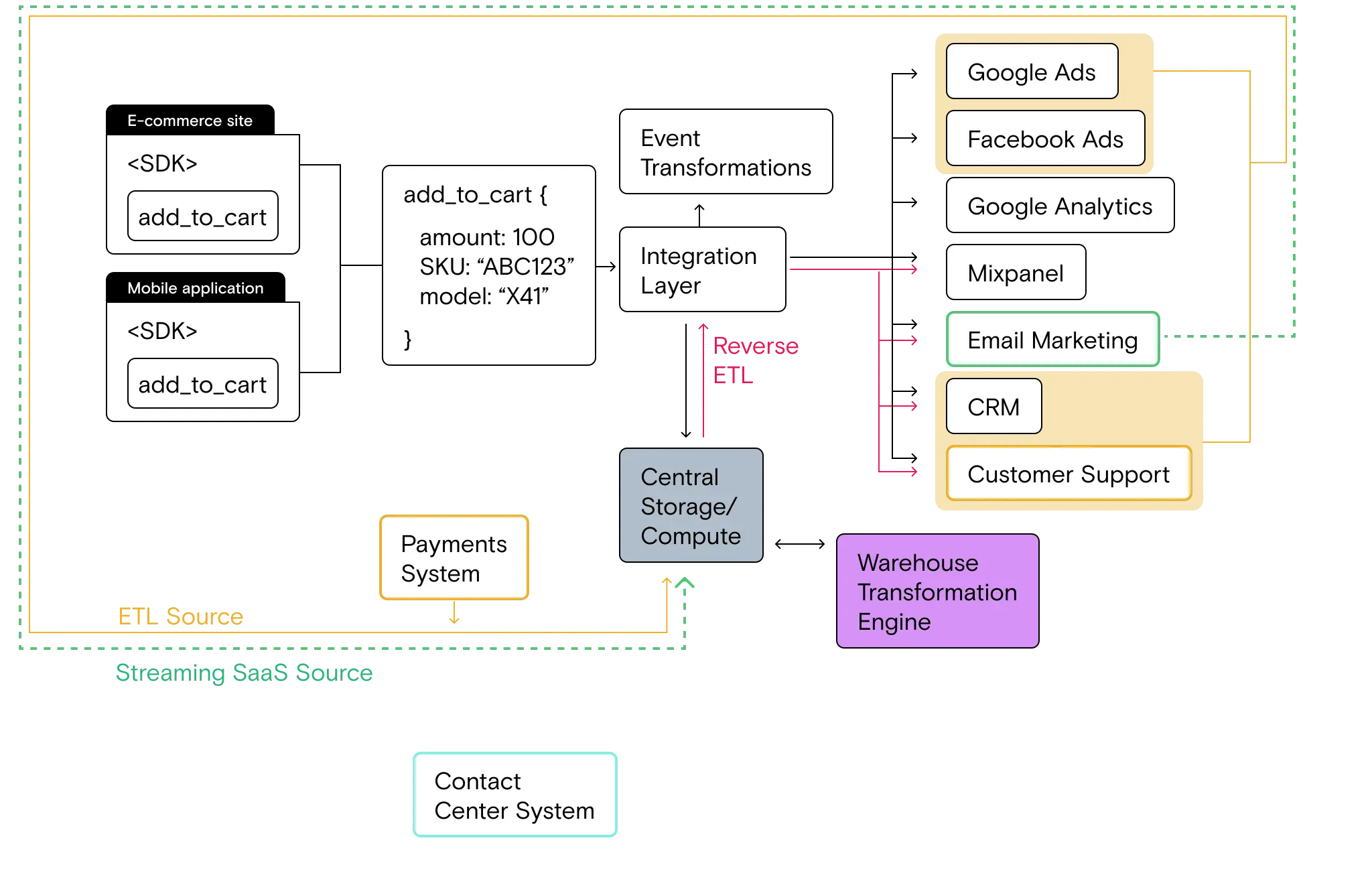
While the contact center data is technically available and could hold the key to solving the churn problem, the Growth Stack isn’t suited to working with this data.
Your data challenges
- The contact center data exists as long-form chat transcripts as well as audio files of phone call recordings, both of which are unstructured data that can’t be pulled into the warehouse for analysis.
- As a result, even though your historical analysis associates customer support interactions with churn, your analysts can’t figure out what it is about those interactions that cause people to cancel their subscription.
- Beyond understanding the dynamics of the support interactions, your marketing team would like to know about customers who are likely to cancel so they can send out incentives before the decision is made.
- Your current toolset doesn’t support the complex statistical modeling required to make these predictions.
Guide: implementing a basic ML Stack
Goals of the basic ML stack
The ultimate goal of the ML Stack is to enable your data team to develop predictive analytics that can be used to further optimize the business by acting before certain events, like churn, occur.
To accomplish this, the goals of the ML Stack stage of the data maturity journey are:
- Introduce a data storage layer that can ingest and manage unstructured data
- Introduce a modeling and analysis toolset that both enables advanced statistical analysis on inputs and produces usable outputs
There is one more piece of the puzzle, which is actually sending the outputs from a model to downstream tools for use—i.e., sending a churn score to the email marketing tool so that offers can be sent to subscribers who are more likely to cancel. The good news is that you already have this delivery mechanism built into the Growth Stack: reverse ETL from warehouse tables. If the modeling infrastructure can push outputs into a table in your cloud data warehouse, you can send them anywhere you want. This is a great example of how the smart tooling decisions you make earlier in your data maturity journey pay off big time as you build more complex use cases.
Data focuses of the ML Stack
ML models require inputs in order to produce outputs. As far as the inputs go, ML models are very data hungry. Thankfully, with the Growth Stack, you have a huge amount of the input data already at your disposal in your cloud data warehouse, including all event stream (behavioral) data as well as relational/transactional data.
The other major piece on the input side is data that the Growth Stack can’t manage. So, with one major input covered, the data focuses of the ML Stack are:
- Unstructured data inputs
- Model outputs
Both of these are simple on a basic level. Unstructured data inputs (like chat transcripts and audio recordings) can be extremely valuable for building models, especially because you can’t use traditional methods of analysis for those data points.
Outputs are exactly what you would expect: the results of the model. These are called features in the ML and data science world, and we’ve already discussed one great example: a churn score.
Step 1: implement a data lake to collect and manage unstructured data
At a basic level, this is pretty simple. Like cloud data warehouses, data lakes are simple to stand up and most of the major contact center systems have standard integrations with data lakes. If not, there are plenty of third-party tools that can facilitate the loading of unstructured data. The data lake providers themselves have various kinds of loading mechanisms, but these might require a more manual process than an automated pipeline.
Once you’ve set up a data lake and determined the best method for loading data, your stack will look like this:
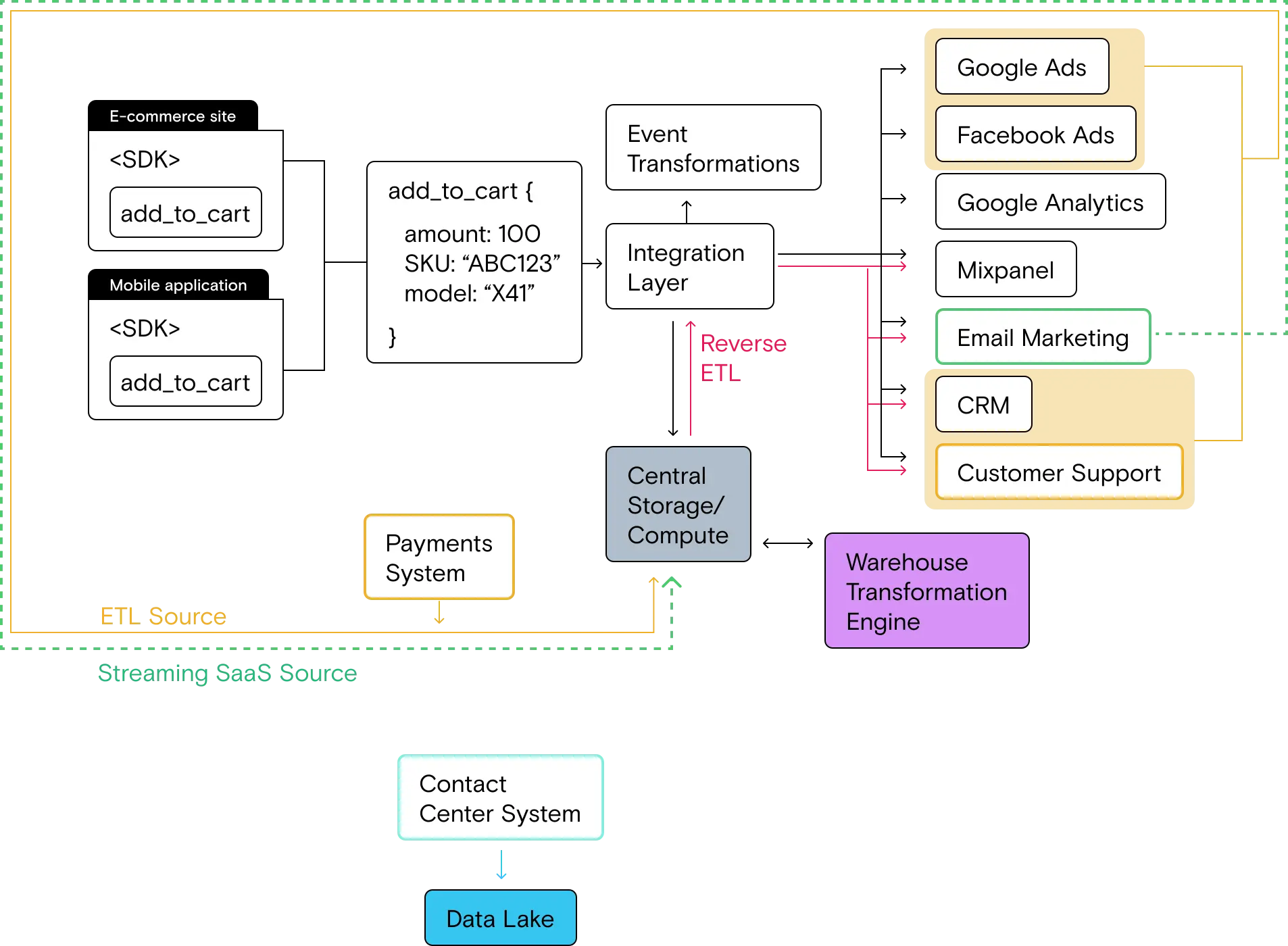
Step 2: implement a modeling and analysis toolset
As we said above, this isn’t a post about ML ops, so we aren’t going to go into a ton of detail on specific tooling. If you’re taking your first steps into ML, your modeling layer could be a simple python/notebook setup that you run locally. On the more complex end of the spectrum, you might choose to adopt a data lake that has ML tooling and integrations vertically integrated—this all depends on your needs and specific tech stack as a company.
Additionally, it’s worth noting that there are multiple “ML as a service” products that have come to market, which allow non-data scientists to run models based on inputs.
No matter which modeling toolset you choose, the fundamentals of this step remain the same: you have to set up the modeling layer and prepare to pull data into it. There’s good news here, too: most modern modeling tools are designed to work with data from multiple sources, so pulling inputs from your data lake and data warehouse should be part of the normal setup process.
Once you set up your modeling toolset and connect to your data lake and data warehouse, your stack will look like this:
Step 3: develop features and train the model
In machine learning, the inputs you use are specific attributes or input signals that your predictive model uses to generate a prediction. These are also called features.
It’s worth noting here that selecting features is a non-trivial task.
- If you select the wrong features, your model’s accuracy, precision, and recall will suffer due to noisy data
- Selecting features incorrectly may also lead to problems such as data leakage, which can give you great results on paper but perform poorly once deployed
Both are issues your data scientist can mitigate with proper setup and modeling.
Continuing on with our example company, the features for determining churn from the subscription program could be things like:
- Total number of purchases
- Total number of support agent interactions
- Sentiment of most recent support chat or call
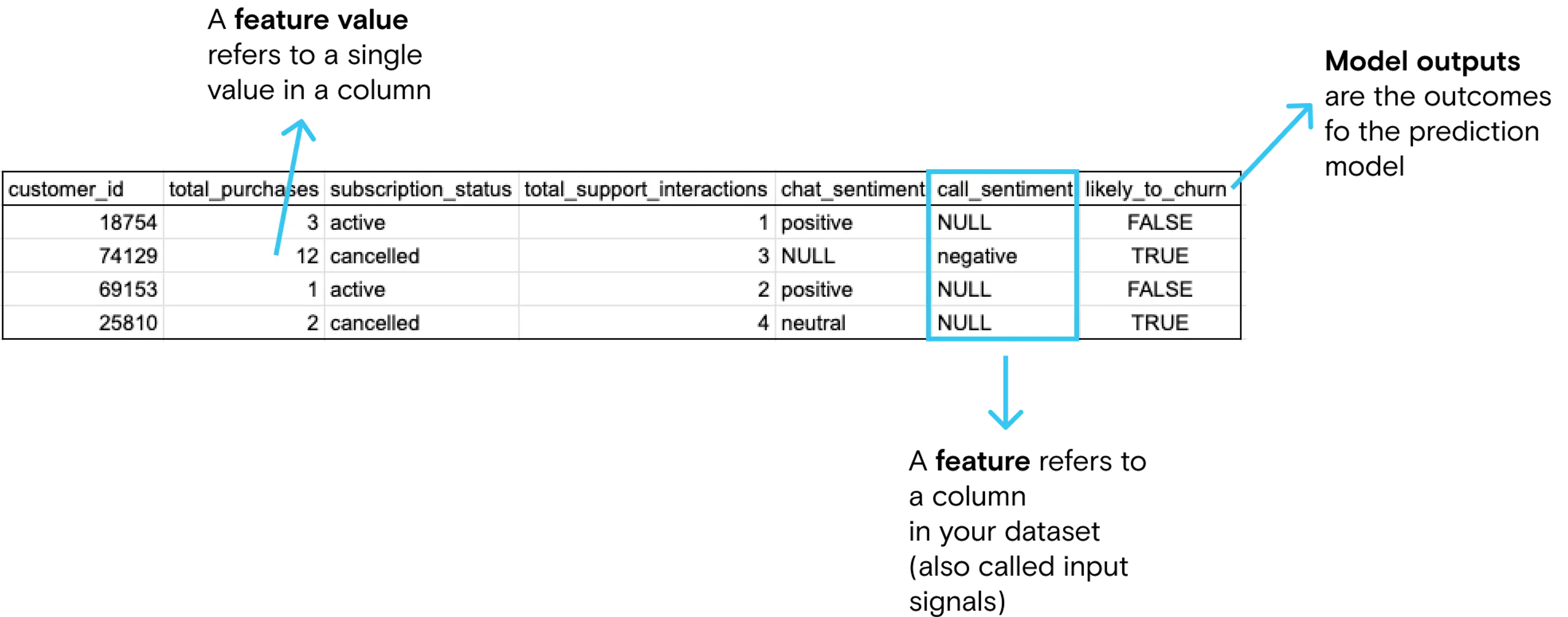
No matter the specific ML tool you choose, feature development is most commonly accomplished using SQL, Pyspark or good old Python.
Also, it’s out of scope for this post, but worth noting that at scale, feature stores become an important component of your ML stack. They make it easy to transform raw data into features, store the features, and serve them both for model training and, once deployed, for delivering predictions to a larger number of destinations, including your own software systems (apps and websites). We will address this in the next post on the Real Time Stack.
Step 4: train the model
Again, this isn’t a post about ML workflows, but for the sake of completeness, let’s cover the basics of training a model.
Once you have defined and computed your features, you need to train your model. The training process requires you to provide the training data (containing the correct output). The training data would include observations, feature values, and the correct answer.
In our example, you want to know if a certain customer will churn or not based on purchase history and the nature of recent interactions with support. You would provide the model with training data that contains customers for which you know the answer (i.e., a label that tells whether the customer churned or not). With this data, your chosen learning algorithm would train the model, enabling it to take features as inputs and predict whether a customer is likely to churn based on those inputs.
Once you have created your model, it is critical to evaluate whether your model is able to make accurate predictions given new inputs (i.e., data not seen during the training process).
If your model performs well, it’s time to put the outputs to use, which is where the Growth Stack comes back into the light and saves us a huge amount of work.
Step 5: send the outputs to your stack for use by downstream teams
Outputs from ML models can be deployed in a number of ways from simple to very complex deployments such as delivering predictions in real-time through your own custom app or website.
Here we’re talking about taking your first steps into machine learning, so we’ll cover the simplest use case which leverages the existing infrastructure of the growth stack to collect and distribute outputs.
Thankfully, this actually is simple thanks to the cloud data warehouse and reverse ETL pipeline that we already have in place. Here’s the basic workflow:
- Push outputs from your ML tooling into a table in your data warehouse
- Depending on the structure of the output table, you often need to perform a few simple joins to produce a materialized view that has all of the data you want to send to downstream tools
- Send the materialized table to downstream tools via reverse ETL
- Practically, this means that customers in systems like your email marketing tool will have a new data point added to their contact record (likelihood_to_churn).
- We generally recommend building important segments in the warehouse as their own materialized views. In the case of our example, this would most likely be a table of users who are likely to churn (likelihood_to_churn = TRUE).
- Celebrate when downstream teams send offers proactively and decrease churn!
It’s worth noting here that for the basic use case of sending outputs to your existing business tools, the efficiency of leveraging an existing data flow (warehouse, reverse ETL, downstream tools) saves an immense amount of operational and engineering lift, meaning incredibly quick time to value for your initial machine learning efforts.
The full (basic) ML Stack architecture
Once you’ve got outputs flowing back into your warehouse and through reverse ETL, your basic ML Stack will look something like this:
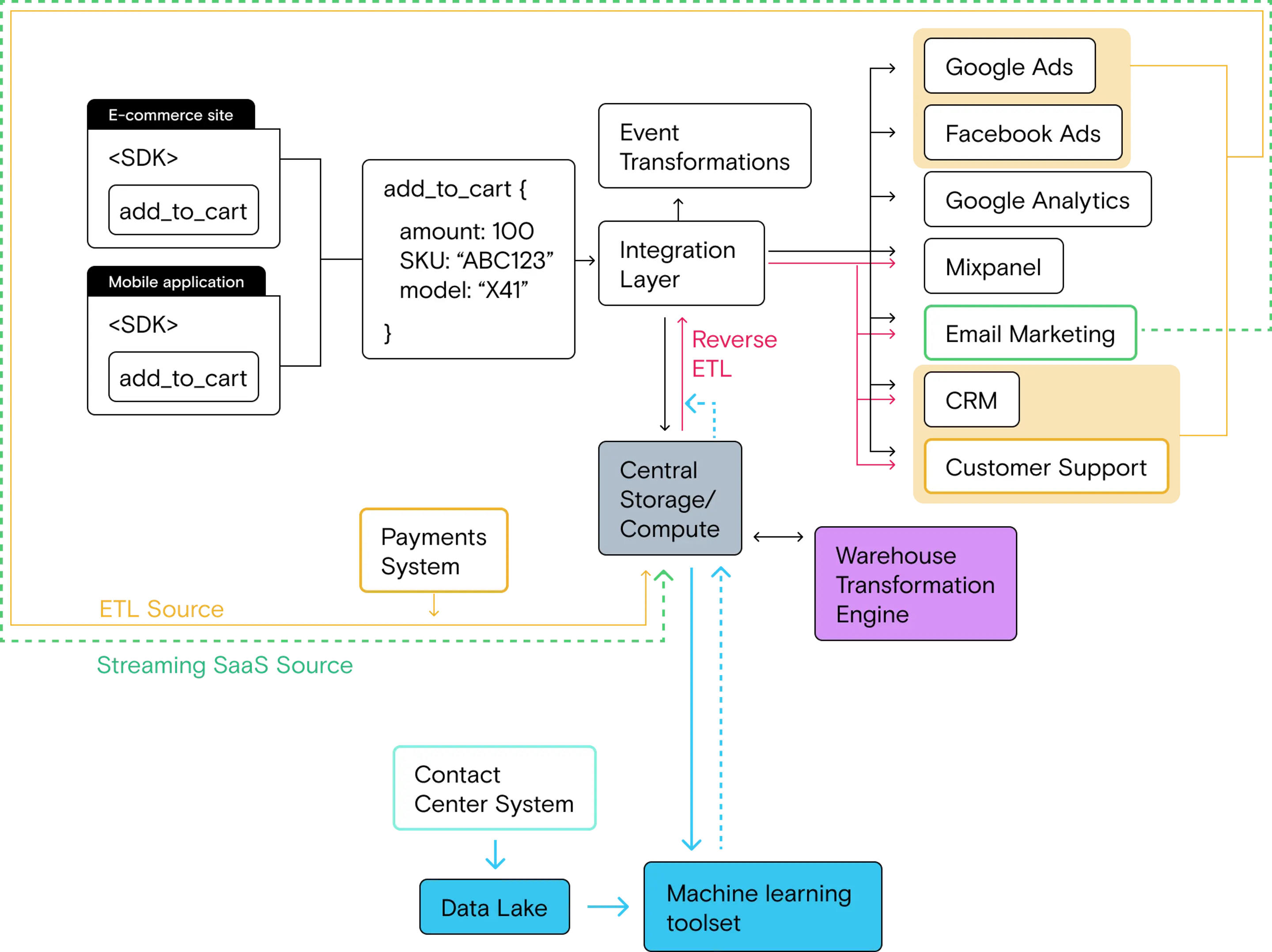
Tooling and technical review
The ML Stack adds two key components to the stack:
- A data lake (recommended if you have unstructured data)
- Data modeling and analysis tools, e.g., PySpark, NumPy, Pandas, Python
- These can include things like Python and PySpark, but as sophistication increases, could also include components for model deployment and modeling
Choosing the right tools for the job
To take your first steps into ML you won’t need to build out a full ML workflow. Here are a few guidelines for selecting the tools you do need:
Data lakes
Like cloud data warehouses, there are multiple good options for data lakes and almost all of the major players are easy to set up and work with. The big decision with data lake infrastructure is whether or not you want a vertically integrated system with built in tooling on top of the data lake to manage some or all of the ML Ops workflow. For companies just starting out, we generally recommend starting with a basic cloud data lake. You’ll likely even be able to bring this with you if you migrate to a more vertically integrated ML system in the future.
Data lake..houses?
We’d be remiss not to at least mention the data lakehouse. This architecture combines the flexibility and scalability of data lakes with the usability of table-based cloud data warehouses, and it shows a lot of promise for companies who want one tool for both jobs. But lakehouse as a service is still relatively new, and adopting a lakehouse architecture generally requires a larger conversation about your data stack in general. For most companies, the warehouse + data lake setup works great, even at significant scale.
ML tooling
If you’re taking your first steps into machine learning, our advice will be the same as it always is: keep it simple, even if that’s basic Python and notebooks. Your data scientist is probably already comfortable with certain languages and tooling—start with those.
As your data science practice matures, the team can make bigger decisions about more complex and comprehensive ML workflow architecture. The thing to keep in mind here is that if you’ve chosen an extensible toolset at every phase of modernizing your stack, you should be able to easily test and change out ML tooling around your warehouse and data lake as your team builds preferences and you determine what will work best for your specific needs.
One additional thing to bring back up is the rise of ML as a service tooling that provides all of the modeling and training as a service. There are even services that can run directly on your warehouse, meaning feature development can happen in your native SQL editor. Depending on the structure of your team and your machine learning needs, this can be a low barrier way to enter the world of predictive analytics.
Outcomes from implementing the ML Stack
The ML Stack is the natural evolution of the Growth Stack. While the Growth Stack allows you to derive insights using descriptive analytics, the ML Stack unlocks entirely new frontiers with predictive analytics. Implemented correctly, the ML Stack can drive massive bottom line impact by decreasing churn and increasing lifetime value.
Specifically, teams can:
- Mitigate problems proactively, as opposed to reacting after they have been observed
- Leverage valuable unstructured data that wasn’t possible to use before
With your built-in warehouse + reverse ETL distribution system from the Growth Stack, you’ll have far quicker time to value from your models than if you had to build all of the deployment componentry yourself (which is always a great point to make to your boss 🙂).
When have you outgrown the ML Stack?
For many companies, the ML Stack is the ideal end-state solution. However, for B2C companies with millions of customers and commensurate marketing spend, there is an opportunity to drive even more value from machine learning outputs through real-time personalization. If you can modify the customer experience in real-time based on outputs from a machine learning model, you can optimize the customer journey on a micro-level and remove friction at every possible point.
If you’re at a stage in your data maturity where you’re beginning to explore real-time personalization, you will need additional tooling to upgrade your infrastructure to the Real-Time Stack.
Recent Posts

Why Shopify will increasingly require data engineering expertise
By John Wessel
First Party Cookies - A Good Evolution
By Brooks Patterson, Tom Shelley

Why data teams must separate support work from development work
By Matt Kelliher-Gibson
Get the newsletter
Subscribe to get our latest insights and product updates delivered to your inbox once a month